Aviso: Es un artículo largo y no muy técnico. Te recomiendo coger un café y/o armarte de paciencia 🙂
Nota: Este artículo nace de un proyecto personal, presentado como charla en The Mindcamp. No hubiera sido posible construir esto sin todos mis amigos y colegas que me ayudaron cuando lo pedí. Aprovecho este canal para daros las gracias 🙂
Cuando Microsoft presentó el Bot Framework hace unos meses y además insistió bastante en IA y bots, se me ocurrió que podría hacer un mini proyecto para ver qué tal funciona y comprobar su uso.
El concepto de bots no es nada nuevo. Ya cuando era joven pasaba las tardes en el IRC respondiendo a bots de preguntas; e incluso alguno me hice para hacer chorradas con los usuarios de la sala de chat. Al presentar el Bot Framework, me vino el recuerdo de esa etapa y me puse a investigar a ver cuál es la visión de usar bots ahora y qué podemos hacer con ellos. Por un motivo o por otro quería hacer un bot y quería que fuese distinto. No quería el típico que te diga la hora o tengas frases prefijadas.

Bot Framework
Este artículo NO va a ser un artículo dedicado a analizar Bot Framework. Ya hay infinidad de artículos muy buenos en la MSDN y otros tantos tutoriales de «Hola Mundo». Si quieres saber cómo funciona, te recomiendo que le eches un vistazo a la página de Bot Framework.
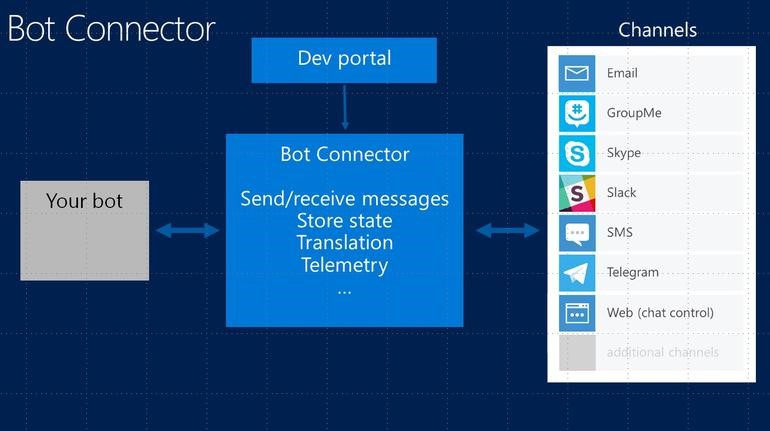
Para mí Bot Framework me supone un alivio a la hora de crear un bot, ya que simplifica lo que es el propio bot (básicamente una WebAPI que tiene un único endpoint a través del cual se reciben todos los mensajes): gestión de conversaciones, permite traducir automáticamente los mensajes y en especial, han cuidado mucho la integración con otras plataformas. Tiene un gestor muy sencillo en el cual con varios pasos guiados y muy sencillos te permite desplegar tu bot sobre distintas plataformas, como Skype, Telegram, Facebook, SMS, etc. Tal vez para mí esta sea una de las características más importantes, ya que me permite gestionar la publicación del bot sobre las distintas plataformas de una forma centralizada.
Una cosa a tener en cuenta es que no es una release. Bot Framework está en preview, con todo lo que ello implica. Funciona bien y han mejorado bastante respecto a hace unos meses, pero no omitas la palabra «preview» al pensar en ello.
Una vez sabiendo cómo podía publicar el bot, el siguiente paso era darle contenido. Según la plataforma puedes hacer que el bot sea proactivo desde el punto de vista del usuario o te ofrezca opciones. Por ejemplo, puedes hacer que a determinada hora el bot te abra una conversación y te diga algo. O puedes que te envíe imágenes o preguntas con opciones elegidas para que te muestre algún tipo de información. En cualquier caso mi objetivo es mucho más humilde y si el bot responde a algo relacionado con lo que el usuario le envía, me doy por satisfecho. No quiero que el bot reciba comandos, quiero que sea capaz de interpretar un texto normal escrito por un humano.
Como quiero un bot que responda, necesito dotarle de frases que responder. En un primer momento pensé en buscar frases célebres de WikiQuote o usar textos de subtítulos de alguna serie. Pero me resultó más fácil coger algún perfil de Twitter famoso y usarlo como corpus de frases que responder. Así pues con esto, la arquitectura de mi bot sería la siguiente:
- Una web app que expone una web api para usar Bot Framework.
- Un web job se encargaría de la ingestión de datos vía Twitter. Cada hora se conectaría a Twitter y extraería los tweets de los perfiles de usuario que he marcado.
Con esto tan simple ya tengo el bot con contenido funcionando. Además, me permite tener la web app en Free. Y sí, Bot Framework es gratuito. Al menos de momento.
Cognitive Services
Text Analyzer
El siguiente paso es encontrar una forma de dada una entrada de usuario, poder devolver la respuesta más apropiada dentro del corpus de mensajes. Aquí es importante tener un corpus amplio y variado. Para ello tenía que disponer de alguna forma de «entender» lo que quería decir el usuario y tener una forma de «entender» qué significan los tweets del corpus. La primera aproximación consistía en intentar hacer un análisis de la frase para extraer la estructura gramatical y trabajar con ello. Evidentemente es una tarea muy compleja y no es algo que se pueda hacer en un par de horas, así que descubrí una serie de APIs dentro de Microsoft Cognitive Services que permiten extraer información del texto. En concreto me basé en Text Analyzer, que permite detectar el idioma y extraer las frases principales de un texto. Aunque bien es cierto que Cognitive Services proporciona APIs para extraer la estructura gramatical de una oración o frase, esta sólo está disponible en inglés. Como mi corpus son mensajes en español, tuve que descartarlo directamente.
Usar TextAnalizer (la API de Cognitive Services que se encarga de esto) es tan sencillo como hacer una petición HTTP a la propia API:
client.DefaultRequestHeaders.Add("Ocp-Apim-Subscription-Key", _accountKey);
client.DefaultRequestHeaders.Accept.Add(new MediaTypeWithQualityHeaderValue("application/json"));
Primero se le pasa como header la clave de autenticación (que se obtiene una vez te registras en la API) y después lanzas una petición al endpoint deseado. En mi caso es el siguiente:
var uri = "text/analytics/v2.0/keyPhrases"; response = await CallEndpoint(client, uri, byteData); var keyPhrases = JsonConvert.DeserializeObject<TextResponse<KeyPhraseResponse>>(response);
Donde el método CallEndPoint, simplemente hago la llamada con el formato correcto:
var result = string.Empty;
using (var content = new ByteArrayContent(byteData))
{
content.Headers.ContentType = new MediaTypeHeaderValue("application/json");
var response = await client.PostAsync(uri, content);
if (response.Headers.Contains("operation-location"))
{
var operationId = response.Headers.GetValues("operation-location").Single();
var operationRequest = string.Format(operationUrl, operationId);
do
{
// Request every minute
await Task.Delay(60000);
response = await client.GetAsync(operationRequest);
result = await response.Content.ReadAsStringAsync();
} while (result.Contains("\"status\": \"succeded\""));
}
else
{
result = await response.Content.ReadAsStringAsync();
}
}
return result;
La estructura de datos de la API se organiza en base a un documento que incluye todos los datos, así que lo modelé y a la hora de hacer una petición, realmente envío el siguiente conjunto de bytes:
Document document = null;
var request = new TextRequest() { Documents = new List<Document>() };
for (int i = 1; i &lt;= input.Count; i++)
{
document = new Document
{
Id = i.ToString(),
Text = input[i - 1]
};
request.Documents.Add(document);
}
var serializedEntity = JsonConvert.SerializeObject(request);
byte[] byteData = Encoding.UTF8.GetBytes(serializedEntity);
Cada texto que envío debe estar identificado, porque después me es devuelto con el mismo identificador y con el resultado del análisis. Además, esto me sirve para aprovechar que puedo analizar varias frases en una misma llamada a la API en lugar de una por una, ya que hay un límite mensual de llamadas (tengas o no la suscripción gratuita). De esta forma aprovecho el webjob de ingesta de datos de Twitter para preanalizar las frases en bloques y así reducir la cantidad de llamadas efectuadas. Sólo se hace una llamada cuando se pregunta al bot, para obtener las frases principales de lo que ha escrito el usuario. Para hacerlas coincidir, miro cuáles coinciden con el corpus y elijo una al azar entre las seleccionadas.
L.U.I.S.
Ya tenía un sistema «para salir del paso» que me permitiese tener un bot que responda a algo parecido a lo que se le pregunta. Una vez hecho esto, le pedí a varios amigos que me ayudasen y le preguntasen cosas al bot. Esto fue crucial, porque pude ver qué se le preguntaba al bot y afinar un poco las respuestas. Gracias a ello, me permitió descubrir una serie de patrones de preguntas/frases que lanzan al bot y que yo no hacía. Ahora ya necesitaba algo más, necesitaba algo que me permitiese detectar patrones en las peticiones que recibía y reorientar la respuesta hacia esos patrones. Por ejemplo, si preguntas «¿Quien es Messi»? lo ideal es ser capaz de identificar que estás haciendo una pregunta, que preguntas quién es y en concreto, alguien en concreto. Si cambio la pregunta por «¿Quien es Cristiano Ronaldo?» es el mismo tipo de pregunta, pero el objeto sobre el que pregunto ha cambiado. La pregunta puede variar levemente, puede empezar en minúscula, sin el signo de interrogación inicial, sin el final, con / sin tildes… Además puede haber otras preguntas similares.
Para este tipo de casos se suele usar aprendizaje automático. La idea es sencilla: dado un conjunto inicial de elementos ya categorizados, seré capaz de ir detectando los nuevos elementos. Tal vez no los detecte a la primera, o no sean exactos, pero en ese caso puedo reanalizarlos de nuevo y detectarlos mejor iteración por iteración.
Cognitive Services nos proporciona L.U.I.S. (aka Language Understanding Intelligence System) que es justamente una herramienta de aprendizaje automático que está pensada para procesar modelos basados en comandos. Por ejemplo, dentro de mi modelo la pregunta «Quien és Messi?» es una entidad y le marco que «Messi» es una persona. A base de ponerle más preguntas y entrenarlo más, puedo ponerle preguntas similares y el sabrá decirme si es una pregunta de tipo «Quien és» y que «Messi» es la persona.
Aunque L.U.I.S. admite un conjunto limitado de entidades, me sirvió para obtener una serie de preguntas típicas que mis usuarios habían hecho. Además me permite mantener y entrenar a mi modelo si veo que algo no lo detecta. Si por ejemplo recibo la pregunta «quien es Federico Garcia Lorca» y no me detecta bien el nombre, puedo reindicarle «Federico García Lorca» es la persona y el modelo se vuelve a entrenar con esta información.
Veámoslo con una captura de ejemplo, extraída directamente del modelo que tengo construido:
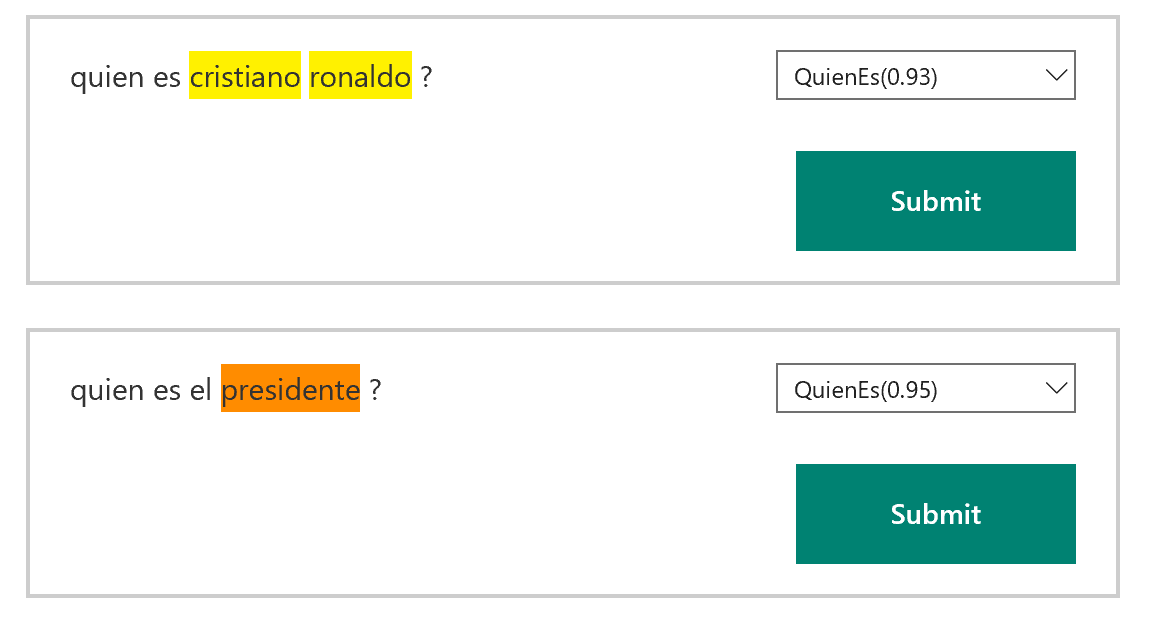
Dentro de las entidades que dispongo, es capaz de detectar que a las entradas «quien es cristiano ronaldo?» y «quien es el presidente?» se corresponden con la pregunta modelada como «quien es X». Nos indica para la primera un 93% de probabilidad y un 95% para la segunda. La diferencia de colores en las palabras resaltadas es el tipo que busco, ya que tengo dos tipos de objetivos: personas y cosas. Es capaz de detectar que «cristiano ronaldo» es una persona y que «presidente» es una cosa. Y siempre, si considero que está mal o no está muy afinado, puedo cambiar esa asignación y volver a enviar la entrada pulsando «Submit». En ese momento el modelo se entrenará de forma automática y será capaz de afinar la respuesta con la información que le hemos suministrado.
A nivel de código L.U.I.S tiene su propio paquete de NuGet, por lo que no es necesario hacer una llamada HTTP y preparar/procesar los datos a enviar/recibir.
bool _preview = true; LuisClient client = new LuisClient(_luisAppId, _luisSubscriptionKey, _preview); LuisResult res = await client.Predict(input);
Con estas tres simples líneas, invocamos a L.U.I.S. Nótese que lo que le enviamos es que nos prediga en base a una frase. Esa frase la lanzará contra el modelo que tiene ya entrenado y nos devolverá un resultado con la probabilidad de las entidades que él cree que son relacionadas con la frase que hemos enviado. Además, podrá detectar parte en las entidades (ej: «Messi») si así le hemos entrenado previamente. Ya es decisión nuestra, en parte a la probabilidad de cada entidad en determinar qué hacer. Lo bueno es que si vemos que la probabilidad no nos encaja con lo que creemos que debería ser, siempre podemos volver a L.U.I.S y darle más información sobre el modelo para volver a entrenarlo.
Ahora ya sí, con un simple algoritmo podía lanzar peticiones a L.U.I.S, ver si encontraba algo que me pudiera valer y si no, seguía cotejando con las frases clave de los textos.
¿Cuál es el secreto de la felicidad?
Una pregunta arriesgada y profunda. Si supiera la respuesta o quisiera hacer creer que la se, posiblemente dejaría el gremio y me pondría a escribir libros y dar conferencias como buen gurú. Lamentablemente sólo sé que no sé nada, así que dejaré mis bestsellers para otro momento en mi vida. Pero si has llegado hasta aquí, al menos me reconocerás que el título tiene gancho.

Pero la pregunta, si bien no quiero saber cuál es el secreto, sí me interesa saber si mis usuarios son felices o no. Los textos que escribimos en redes sociales se usan en los típicos estudios de doctorandos desde hace varios años para analizar su contenido y entender qué significan. Tal vez no ahora, pero hace unos años era bastante común: saber si lo que escribo es algo feliz o triste. Se suele analizar teniendo en cuenta el contexto, las palabras que se emplean, expresiones no lingüísticas (como emoticonos) etc. Evidentemente desde un punto de vista comercial es bastante interesante de cara a categorizar a tus usuarios…
Una de las propiedades de la API de Text Analyzer es que permite extraer la felicidad de los textos. Realmente, para ser exactos, más que la felicidad en sí trata de analizar los textos para ver si tienen un sentimiento negativo o positivo. Usando esta API, del mismo modo que se hizo antes con las frases clave, puedo extraer de primera mano el sentimiento de mi corpus. Después lo usaré para ver el sentimiento del usuario cada vez que escriba un mensaje.
Preparados para el análisis…
Como la idea ahora ha sobrepasado la línea de «aplicación», pues vamos a entrar en el análisis, necesito modificar el proyecto. Ahora he de decidir qué quiero analizar/medir y en base a qué, así que:
- Voy a analizar el sentimiento de mis usuarios
- Voy a analizar cuáles son las palabras más usadas en mis usuarios
- Voy a establecer una granularidad de tiempo hasta la hora del día.
Para ello necesitaré una estructura que permita estos análisis. Aunque tengo pocos datos, he decidido montar un cubo multidimensional que tiene las siguiente dimensiones:
- Canal: Para saber de dónde vienen mis usuarios (Telegram, Skype, Facebook, SMS, etc)
- Conversación: Los mensajes se agrupan en conversaciones (cada ventana de chat que se abre se considera una conversación)
- Fecha: Fecha de cuándo se envío/respondió el mensaje, con una definición hasta la hora del día.
- Fuente del mensaje: Para ver si es un mensaje que ha enviado el usuario o ha respondido el bot.
- Tipo de mensaje: Para ver si es un mensaje o un comando.
- Usuario: Los distintos usuarios que han usado el bot. Tengo la información que me suministra Bot Framework, que es prácticamente nada (Id y con suerte el nick/nombre) pero suficiente para poder separarlos después durante el análisis.
- Palabra: Las palabras que se han usado en los mensajes.
Y finalmente, tendré dos tablas de hechos (donde junto las dimensiones con lo que quiero medir):
- Conversación: Mido la felicidad de la conversaciones, cuántos mensajes tienen, cuántos usuarios participan…
- Palabras: Mido cuántas palabras hay, cuál es la longitud de cada palabra…
Y para montar este modelo, he usado la aproximación de Kimball para montar un modelo en estrella. La idea detrás de un cubo multidimensional es que relajamos las formas normales típicas de los modelos relacionales. Así pues, en mi tabla de hechos tendré una fila por cada entrada que quiera medir. En el caso de conversaciones, la granularidad llega hasta la frase. Por lo tanto, cada vez que alguien escriba o el bot responda, se insertará una fila en esa tabla. Esta limitado así porque si quiero medir el sentimiento, lo mido en base a una frase completa. La siguiente imagen es un ejemplo del contenido de esta tabla:

En el caso de la tabla de Palabras, la granularidad alcanza hasta la palabra en sí. Es decir, si se escribe una frase con 50 palabras, en esa tabla se insertarán 50 filas con cada una de las palabras.
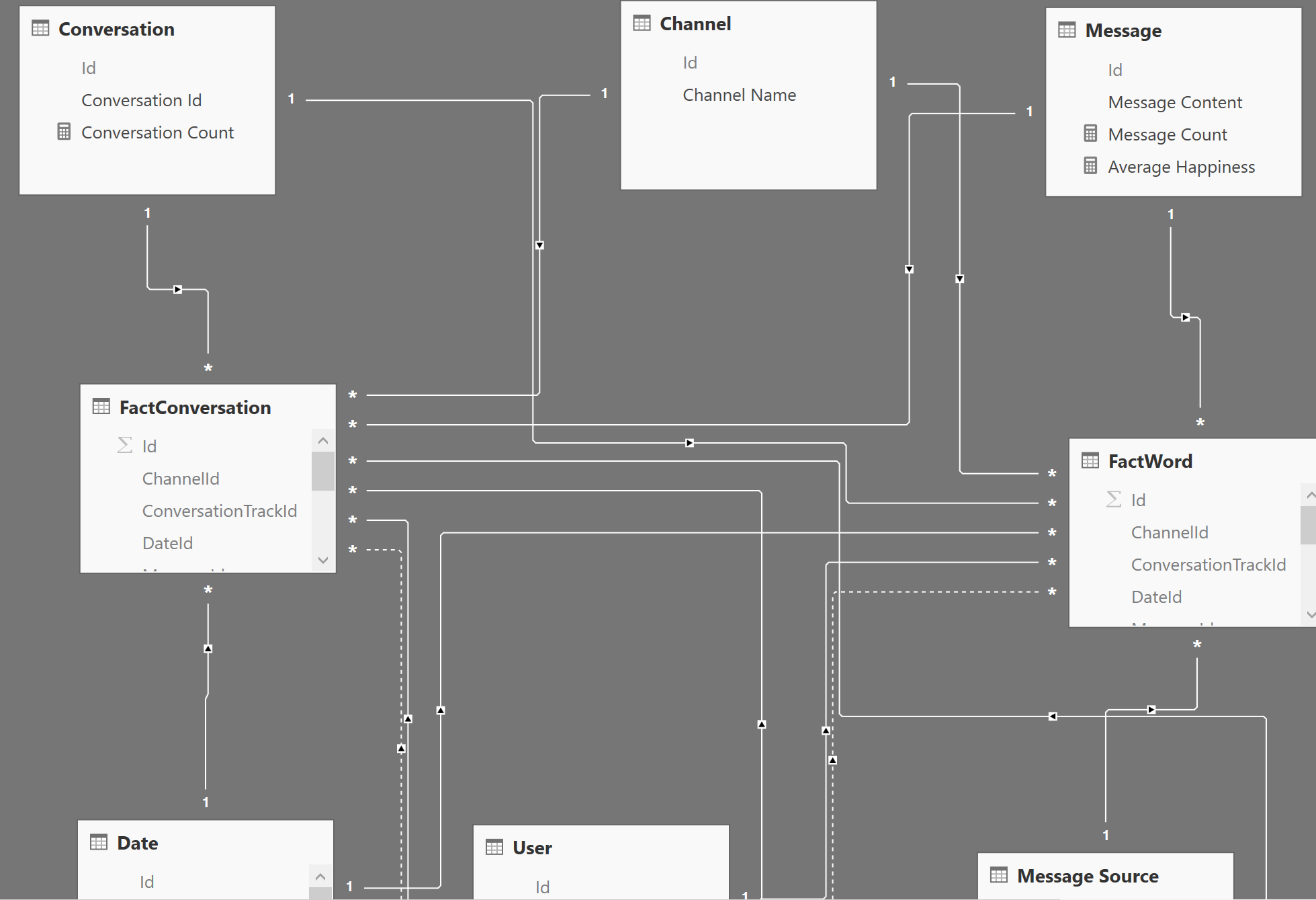
El modelo en estrella propone que cada columna de la tabla de hechos que no sea una medida apunte hacia una fila de una dimensión. De este modo, tenemos la tabla de hechos en el centro «rodeada» de las dimensiones que emplea. De ahí el nombre en estrella:
Para poder montar este modelo, tengo dos retos fundamentales. El primero es que no quiero que la experiencia del bot se vea perjudicada. Ya bastante hace el tener que lanzar peticiones a una API externa por cada mensaje como para que además tenga que calcular e insertar las filas en el cubo. Aprovechando la estructura que tenía (webjobs gratuitos) y el patrón multitenant, monté dos webjobs y una cola:
- Cada vez que hay una interacción con el bot, se manda la información a una cola de Azure.
- Un webjob será el encargado de leer los datos de la cola y meterlos en una tabla de Staging dentro del cubo multidimensional. Esta tabla tiene datos casi «en bruto».
- Otro webjob se encarga de coger todo lo que hay en Staging y procesarlo para actualizar cada una de las dimensiones y finalmente, rellenar las tablas de hechos con la información suministrada.
Posiblemente la parte de la cola la podría haber ahorrado, pero al tener todo el entorno «bajo mínimo» quería minimizar el impacto en el bot y prefería darle a otro esa responsabilidad.
Ya casi está todo. Veamos un resumen:
- Tenemos un bot que lee datos de Twitter
- Al recibir una petición, consulta con L.U.I.S y TextAnalyzer la frase más acorde. Justo antes de mandar la respuesta al usuario, manda la información analítica a una cola
- Por otro lado, los procesos de la parte analítica se encargan de coger los mensajes y rellenar las dimensiones y las tablas de hechos.
Todos los webjobs se ejecutan cada hora. Son independientes entre sí (pueden caerse los tres y el bot seguiría funcionando sin problema). Los mensajes no se borran de la cola hasta que no se insertan, por lo que si se cae incluso el job de la parte analítica, no perdería esa información. Quedaría ahí hasta que se pueda insertar de forma satisfactoria.
Además, lo tengo montado con Visual Studio Online con builds de integración y despliegue continuo. El despliegue sólo se hace si antes se ha hecho un backup automático de las bases de datos, por si rompo algo que al menos el bot deje de ir pero no pierda mis datos analíticos (que en el fondo es lo que importa en esta vida!)
Ver y entender, esa es la cuestión
De nada sirve que extraiga información, analíticas y luego no se pueda mostrar. Si no la puedo ver, es lo mismo que no tenerla.
Para visualizar los datos he usado PowerBI. Es una herramienta de Microsoft gratutita (la parte online no lo es) que permite generar reportes e informes en base a modelos de diversas fuentes. En mi caso particular, importé el cubo multidimensional en un modelo de PowerBI y le puse un formato correcto (nombre, tipos de datos, relaciones, etc). Esto permite que cualquiera que acceda al modelo pueda consultarlo con las dimensiones que antes he mencionado para extraer las medidas.
Así por ejemplo, se han visto cosas curiosas. He creado varios reportes para poder visualizar la información. El primero de ellos es una vista general:
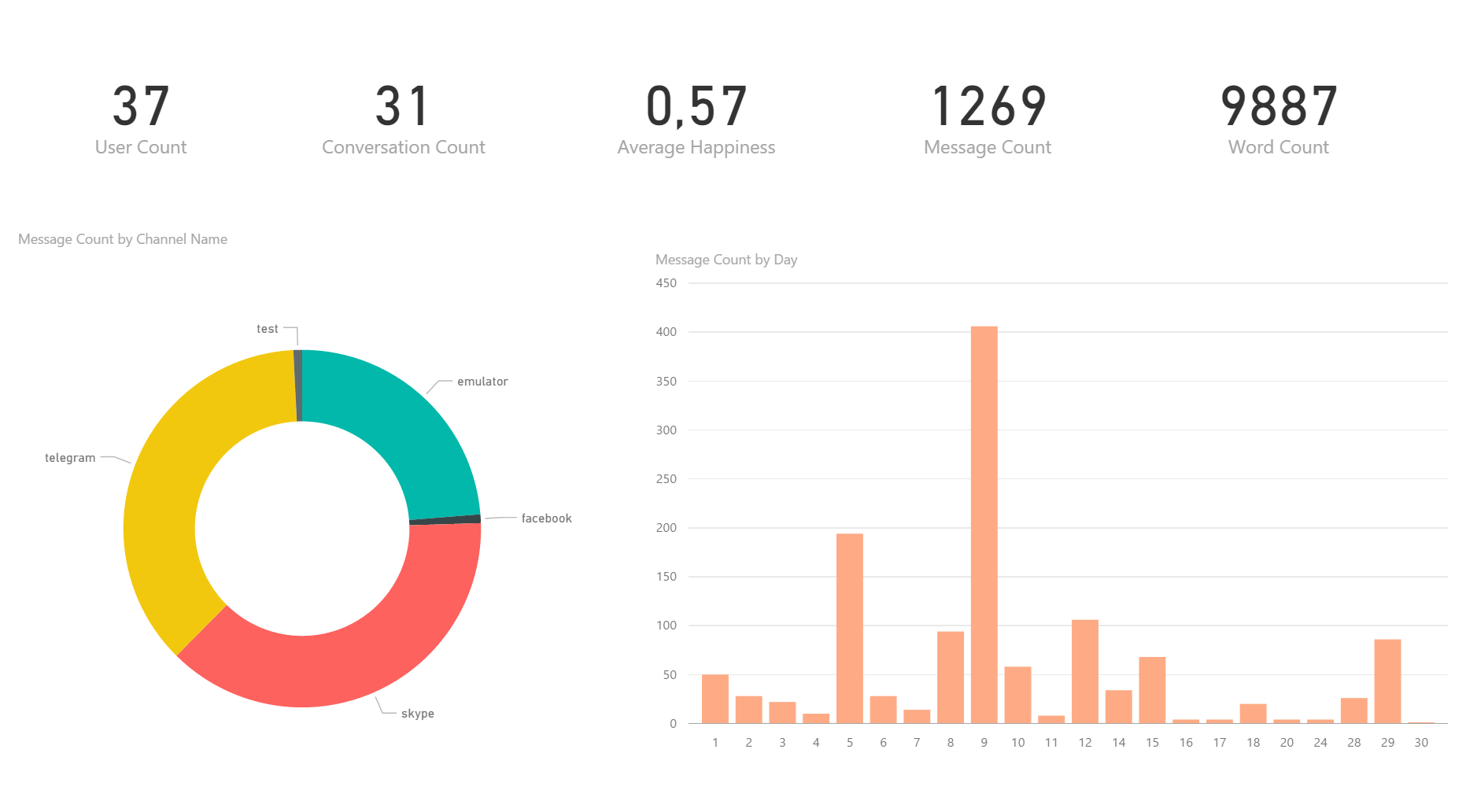
Podemos ver la cantidad de usuarios que han interactuado, cantidad de conversaciones, felicidad media, mensajes, palabras y canal empleado. Lo bueno de PowerBI es que puedo hacer click sobre una parte del «circulito» de canal o fecha y me filtra todos los datos.
Sin embargo, la parte interesante comienza cuando creo el reporte de felicidad por usuario. Se percibe que los usuarios tienen un sentimiento positivo por la tarde. Durante la mañana están menos positivos, hasta que llega la tarde. A partir de las 20-21h (los datos son de verano) el sentimiento comienza a decrecer:

La gráfica superior izquierda muestra el sentimiento del usuario seleccionado por día y la cantidad de mensajes escritos. La de la parte superior derecha sirve para mostrar la relación entre el tamaño de los mensajes y el sentimiento. Los mensajes más cortos tienen un sentimiento más positivo que los mensajes más largos. Y la gráfica inferior, muestra el sentimiento por horas. Pueden variar los picos por usuario, pero la tendencia es la misma para todos mis usuarios.
El siguiente reporte que monté fue para analizar el resultado de las conversaciones. Si como usuario escribes un texto positivo y el bot te responde mal, tu siguiente respuesta será menos positiva. De un modo u otro, tu respuesta está condicionada por lo que te digan. Esto me resultó muy curioso porque no me lo imaginaba, ya que el contenido del bot era de tono humorístico y no esperaba que pudiese afectar a los usuarios. Sin embargo con los datos que tengo no es así. Es decir, que podría manipular el tono de una conversación sin que el usuario se perciba de ello. Véase la siguiente gráfica:

Se aprecia que una «respuesta» por parte del bot condiciona tu siguiente petición, ajustando tu sentimiento de forma inconsciente.
Conclusión
Hemos visto como podemos montar un bot y analizar cómo son los usuarios que tenemos. Que cada cual saque las aplicaciones que esto tiene y que se aplican hoy día 🙂
Si quieres más información, he dejado en mi GitHub una versión del bot lista para desplegar y probar. Sólo necesitarás:
- Tener cuenta de desarrollador en Twitter.
- Tener una suscripción de Azure.
- Darlo de alta en Microsoft Bot Framework.
- Dar de alta el servicio de L.U.I.S. en Cognitive Services.
Con estos datos, rellena los campos en la plantilla parametrizada de ARM. Luego la despliegas y ya lo tienes todo. No debes generar nada, los webjobs se encargarán cuando se ejecuten de generar y rellenar las bases de datos con lo que necesiten para funcionar. Pero por supuesto, hasta que no haya datos de Twitter, el bot no podrá responder nada.
Happy coding!
Muy buen artículo y bastante genérico el ejemplo (aplicable a cualquier otro caso del mismo estilo). Intentaré probarlo y ver si puedo hacer algo parecido con Azure Functions. Saludos!