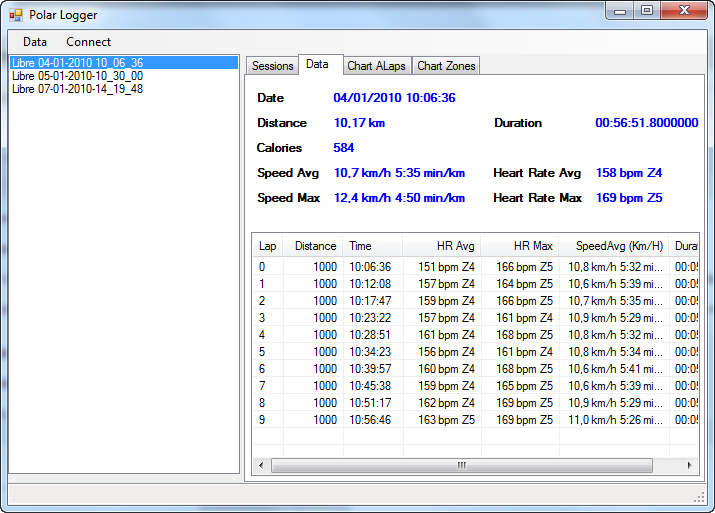
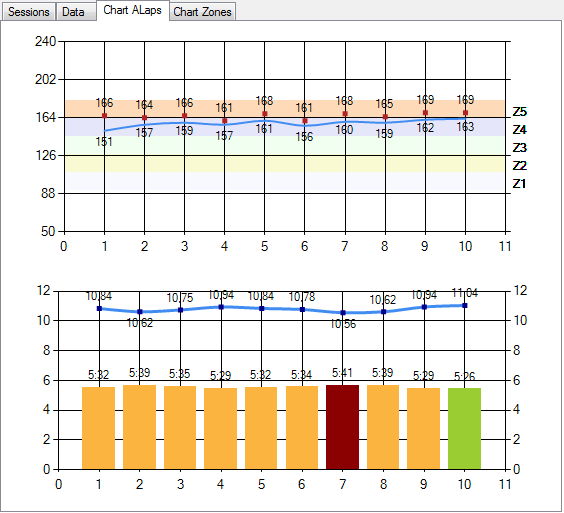
Como comentaba en el post anterior, me gustaría dedicar una serie de artículos a algunas de las consideraciones sobre el diseño de soluciones en SharePoint, el en titulo olvide mencionar que me voy a centrar básicamente en el área empresarial.
FeedBack
Uno de los aspectos que considero más importante es el feedback de los usuarios. Como mencione anteriormente muchos de sus problemas a veces se resuelven con imaginación y creatividad, siempre hay que estar atentos a lo que dicen los usuarios.
Por ello una de las partes principales de un desarrollo en SharePoint, puede comenzar por un simple foro de discusión en donde los usuarios puedan dejar sus opiniones tanto críticas como de mejora.
Evidentemente aquí no hay mucho de diseño, pero esto será un pilar fundamental si se hace un buen uso del mismo.
Para poder categorizar los temas que se tratarán en el foro, a la lista se le puede añadir un tipo de contenido o un campo que contenga los diversos asuntos a los que hace relación un post, así como otro campo que indique si el post es referente a una crítica o a una mejora.
En la mayoría de las organizaciones dinamizar un simple foro como este suele ser un problema si no existe una cultura de colaboración, en ocasiones a la gente le da vergüenza comentar cosas, pensando que lo único que van a decir son estupideces, bien, esto es una labor interna en la que hay que concienciar a la gente (y este es un buen punto de arranque) aludir a que jamás mejoraran las herramientas de las que disponen si ellos no hacen nada por mejorarlas; atacar ese pequeño orgullo que todos tenemos, tocar esa fibra, suele dar un buen resultado.
Esto tiene su contrapartida, si el usuario se expresa y pide cosas hay que dárselas (y rápido) si no toda labor anterior habrá caído en balde. Por parte del departamento de IT, habrá que valorar las peticiones de los usuarios y como mencione (y no dejaré de mencionar en lo sucesivo) deberemos realizar una valoración de dichas mejoras de modo que podamos encontrar quórum para llevarlas a cabo y que encajen en tiempo, coste y complejidad.
Según mi experiencia, el usuario tiende a pedir en ocasiones cosas como ¿no podríamos tener un botón aquí que hiciera tal o cual cosa?, nosotros tenemos que pensar en que es lo que el usuario quiere hacer realmente, ¿Por qué, quiere hacerlo?, ¿Qué ventajas encuentra en ello? Y de qué modo podemos ofrecerle algo que le ayude sin que ello suponga demasiada complejidad; Igual el botón no pude estar allí, pero tal vez podamos poner un hipervínculo aquí para hacer lo mismo o casi lo mismo.
El vocabulario del usuario y el nuestro es distinto, hay que hacer un esfuerzo por entenderle, comprenderle y dar a entender lo que nosotros podemos hacer por él.
Una pequeña encuesta en donde los usuarios voten ó valoren las mejoras, puede ser de gran ayuda a la hora de determinar por dónde empezar, así como de tener una idea de a cuanta gente vamos a contentar y/o enfadar con la realización de los cambios.
Un escenario como este puede complicarse todo lo que uno quiera, pero en la práctica debe ser algo sencillo, empecemos dando algo con lo que todos podamos trabajar, un foro en SharePoint y dos o tres campos personalizados (diseño 0%, evangelización y concienciación sobre el uso 100%) pongámoslo en marcha y escuchemos a nuestros usuarios, ellos tienen cosas importantes que decir.
Vigilancia del Entorno
La rapidez con que una empresa sea capaz de reaccionar a los acontecimientos de su entorno, es una medida de los reflejos corporativos.
Sin duda es una parte muy importante, vigilar nuestro entorno; diseñar un portal de vigilancia del entorno dentro de una empresa es algo que aporta gran valor. Hace algún tiempo ayude a un amigo a realizar un portal de vigilancia del entorno y tuve la oportunidad de aprender algunas cosas importantes.
Gracias a internet tenemos a nuestro alcance una ingente cantidad de datos, muchos de ellos nos pueden ayudar a ver qué es lo que está ocurriendo en nuestro entorno, pero identificar la información que nos es útil entre tantos datos puede ser un problema.
Cuando mi amigo me pidió ayuda él había hecho gran parte del trabajo, el había buscado las fuentes de datos que consideraba más relevantes para el entorno de su empresa, clientes, proveedores, mercado, producto, marketing, competencia, tendencias y noticias del sector, incluso encontró algunos foros donde se mencionaba su empresa, todo ello estaba dentro de un site en donde había usado el web part de transformación de XSLT, para recuperar las feeds que él había considerado importantes y poderlas visualizar en varias páginas en función de las distintas categorías a las que hacían referencia.
El site, era útil, de un plumazo tenia agregadas muchas de las noticias que eran relevantes para la empresa, sin embargo la gran cantidad de noticias apabullaba a los usuarios; la gente entraba veía la ingente cantidad de noticias, leía una o dos y salía.
El site resolvía un problema, pero desde luego no lo hacía de la mejor manera posible, pero había algo por dónde empezar lo cual es como ya hemos comentado, bueno.
Le sugerí, que antes de hacer nada, hablara con los usuarios y les preguntará como se podría mejorar el site de vigilancia, tras unas cuantas sugerencias (feedback) por parte del personal de la empresa, había varios puntos en común, la focalización (o audiencia) de la información y la posibilidad de escalar noticias.
La focalización de la información hace referencia al hecho de donde se debe encontrar la información, en vez de tener un site en donde concentrar toda la información, los usuarios opinaban que era mejor que cada web de departamento se viese un resumen de esas noticias, de este modo se orienta la información a una audiencia determinada.
En segundo lugar, debería existir un mecanismo de escalar las noticias importantes; cuando se cuenta con mucha información alguien debe poner está en su contexto, y valorarla de manera adecuada. En la empresa de mi amigo fabrican piezas con plásticos inyectados, de modo que la invención de un nuevo compuesto o mecanismo puede parecerle muy importante a la gente de producto pero a alguien de dirección un artículo más bien técnico puede parecerle intrascendente o un autentico coñazo. De modo que la información ha de ser valorada por alguien de las trincheras que la ponga en su contexto y le de la importancia que debe tener y luego la transmita dentro de su contexto al resto de la organización.
Eso dio pie a la creación de un site DAFO, (Debilidades, Amenazas, Fortalezas y Oportunidades).
Se hicieron los cambios necesarios para que cada departamento visualizara la información pertinente a su área, y como complemento de esa información con un simple click se podía llevar la información del agregador de noticias al sistema DAFO, con eso la noticia podía crear una alerta en el sistema, periódicamente se examina el site DAFO y se toman decisiones en función del contenido.
En un primer momento el sistema funcionaba de manera manual, es decir junto a cada noticia existía un enlace a la web DAFO, en donde el usuario debía crear un breve resumen de la noticia, el tipo de alerta Debilidad, Amenaza, Fortaleza o Oportunidad y un comentario personal de ¿Por qué? Se contempla la noticia como una alerta.
La gerencia de la empresa usa la web de DAFO de forma periódica en una reunión quincenal de seguimiento de diversos asuntos, se analizan todas las alertas y se hace un pequeño acta que se deja en ese mismo sitio.
Más adelante cuando el sistema demostró su utilidad, se mejoró sustancialmente incluyendo algo de programación y ahora permite que tras valorar la noticia, esta incluya un enlace a la fuente original, también el site DAFO cuenta ahora con una serie de gráficos y resúmenes quincenales de las alertas que se han producido así como una lista por cada departamento que permite introducir las fuentes desde donde cada departamento va a recibir las noticias así como los filtros que ha de pasar el contenido para ser agregado; de este modo se su pueden añadir y suprimir fuentes y filtros sin necesidad de programar absolutamente nada.