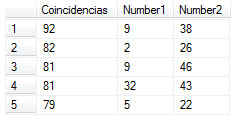
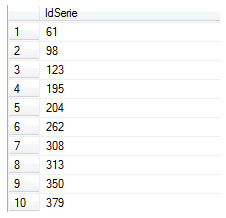
De manera frecuente nos encontramos en escenarios en los que la utilidad de una tabla de números resulta una opción de gran valía, en este caso particular me quiero referir a una consulta hecha
por un usuario en los foros msdn (http://social.msdn.microsoft.com/Forums/es-ES/sqlserveres/thread/4ecf2763-9200-4a45-b184-ee240aa13970/#01137538-8c2b-488a-887b-20f2fbaa384c ), la cual cito textualmente:
“Hola amigos les expongo mi problema espero me puedan ayudar me super urge les explico a modo de ejemplo:
Tengo un contrato y su fecha de primer pago es el 15/06/2012 y el precio es de $1000 y ese saldo el cliente lo va a pagar en 10 pagos semanales lo que necesito es que apartir de la fecha de primer pago, se generen los registros de los 10 pagos y que se especifique que van a ser 10 pagos por 100 pesos cada uno mas o menos quedaria asi:
15/06/2012 $100.00
22/06/2012 $100.00
29/06/2012 $100.00
y asi hasta acompletar los 10 pagos de 100 pesos cada uno.
Creando una tabla de Numeros
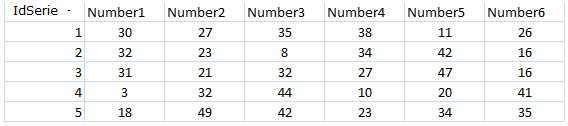
En la opción que me planteaba para solventar la consulta buscaba como evitar cualquier posible uso de cursores o soluciones de tipo procedimental, con el fin de potenciar y generar una opción óptima y enfocada a un manejo de teoría de conjuntos (set theory). El primer paso consistirá en crear una tabla de Números , esta estructura es muy útil, para una diversidad de escenarios que va desde la generación de datos de prueba hasta su uso con funciones de ventana.
La estructura de la tabla es muy simple, puesto que lo requerido es una secuencia numerica, en cuanto al numero de filas o numeros que queremos almacenar en la tabla varia según los requerimientos o usos comunes que les pretendamos dar. En este caso utilizare un codigo planteado por el excepcional Itzik Ben-Gan, cuyo código en lugar de utilizar un tipico ciclo While en donde se recorre un registro a la vez, se insertan las filas de manera masiva, minimizando la cantidad de vueltas o loop, siendo la diferencia en tiempo y rendimiento muy amplia, a continuación el codigo:
IF OBJECT_ID(‘dbo.Nums’, ‘U’) IS NOT NULL DROP TABLE dbo.Nums;
CREATE TABLE dbo.Nums(n INT NOT NULL PRIMARY KEY);
DECLARE @max AS INT, @rc AS INT;
SET @max = 1000000;
SET @rc = 1;
INSERT INTO Nums VALUES(1);
WHILE @rc * 2 <= @max
BEGIN
INSERT INTO dbo.Nums SELECT n + @rc FROM dbo.Nums;
SET @rc = @rc * 2;
END
INSERT INTO dbo.Nums
SELECT n + @rc FROM dbo.Nums WHERE n + @rc <= @max;
Llegado a este punto ya contamos con nuestra tabla de Numeros, a continuación procedemos a construir una funcion definida por el usuario que nos retornara una tabla, lo interesante es la utilización de un CROSS JOIN que nos permitira evitar el uso de un ciclo para generar el cuadro de pagos que se requiere. La funcion recibira como parametros de entrada la fecha inicial en la que se generara la tabla de pagos, seguido del monto (en este caso se asume como un monto fijo) y el numero de cuotas a calcular.
CREATE FUNCTION FDU_CalculoPagos(@i_fecha_inicial date,@i_monto money,@i_cuotas int)
RETURNS @Tabla TABLE
(
numpago int,
fechapago date,
cuota money
)
AS
BEGIN
DECLARE @cuota money
SELECT @cuota=@i_monto/@i_cuotas
INSERT INTO @Tabla
SELECT N.n,DATEADD(month,n,F.fecha_inicio),@cuota
FROM Nums AS N
CROSS JOIN (VALUES(@i_fecha_inicial)) AS F(fecha_inicio)
WHERE N.n <= @i_cuotas
RETURN
END
GO
Como podemos observar la tabla de numeros nos permite realizar una operación para obtener las posibles combinaciones (recordemos que CROSS JOIN genera un producto cartesiano n x m), ubicando como unica restricción que el numero de filas tomadas sea menor o igual que las cuotas que se reciba como parametro en la funcion, en este caso @i_cuotas, ademas de auxilarnos de un uso no tan conocido del operador VALUES y disponible a partir de SQL Server 2008, en cuyo caso podemos representar valores como si se tratase de una tabla, para nuestro caso particular ese unico valor es el parametro de fecha inicial (@i_fecha_inicial).
Se procede a insertar en la variable de tipo tabla (@Tabla) el resultado de la instrucción SELECT que contiene un secuencial, pero sobre todo el calculo de las fechas correspondientes para los pagos haciendo uso de la funcion DATEADD que se encarga de adicionar a la fecha inicial una cantidad de meses (sumando un mes en cada fila) correspondiente a las cuotas definidas.
Como vimos en este pequeño ejemplo, se trato de plantear una solución generica y sin un manejo procedimental que pudiera afectar el rendimiento y eficiencia de nuestra aplicación.