El intercambio de información entre empresas y
organizaciones representan una tarea cada vez más común, por esto no es de
extrañar el amplio uso y aceptación del formato XML como estándar para el
intercambio de dicha información. SQL Server cuenta entre sus muchas características con una
serie de funciones que nos permiten potenciar el uso de XML, pero en esta ocasión
nos centraremos el proceso de transformación de datos XML en un conjunto de
datos (rowset).
El procesamiento de XML se realiza en cinco pasos
fundamentales como se ilustra en la siguiente imagen:
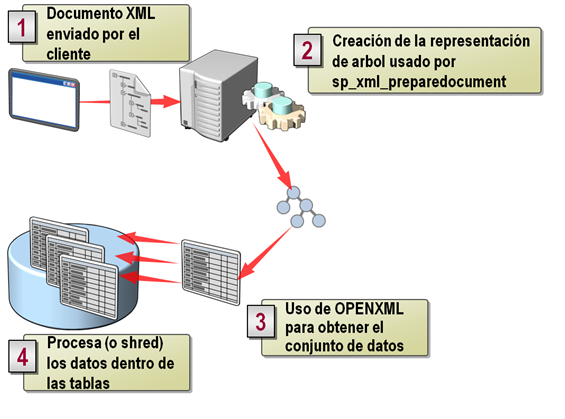
Una vez que se cuenta con el documento XML (bien formado)
este se procede a procesar por medio del procedimiento almacenado del sistema
sp_xml_preparedocument, el cual nos permite validar un documento XML y transformarlo en
una estructura de árbol en memoria, cuyo contenido podemos consultar por medio de la
instrucción OPENXML para obtener las columnas deseadas y así manipular los
datos en la forma requerida.
Iniciemos con un ejemplo simple, suponiendo que formamos
parte de la empresa dedicada a la reventa de artículos por internet y estamos
recibiendo información de un proveedor externo, el documento XML es el
siguiente:
DECLARE @doc xml
SET @doc = ‘<?xml
version=»1.0″ ?>
<Factura
FacturaID=»1000″ ClienteID=»123″
FechaFactura=»2012-01-14″ FormaPago=»1″>
<Lineas>
<Linea ProductoID=»12″
Cantidad=»2″
PrecioUnitario=»12.99″><Descripcion>Encendedor marca
Zippo</Descripcion></Linea>
<Linea
ProductoID=»41″ Cantidad=»1″
PrecioUnitario=»17.45″><Descripcion>Ron Flor de
Cana</Descripcion></Linea>
<Linea ProductoID=»2″ Cantidad=»1″
PrecioUnitario=»2.99″><Descripcion>Bebida embotellada
natural</Descripcion></Linea>
</Lineas>
</Factura>’
DECLARE @IdentificadorDoc
int
EXEC sp_xml_preparedocument
@IdentificadorDoc OUTPUT, @doc
De forma simple podemos decir que
el sp_xml_preparedocument
nos permite procesar un documento XML y obtener una representación del mismo,
el resultado de este sp es un código identificador que apunta hacia la
estructura de árbol del XML creado previamente.
Una descripción más amplia se encuentra en el siguiente link:
http://msdn.microsoft.com/es-es/library/ms187367.aspx
Una vez que construida la estructura o árbol en memoria debemos
acceder a ella, para esto nos apoyamos en la instrucción OPENXML , este nos
permite obtener un conjunto de datos a partir del árbol. La instrucción OPENXML tiene la siguiente estructura:
OPENXML( idoc int [ in] , rowpattern nvarchar [
in ] , [ flags byte [ in ] ] )
[ WITH ( SchemaDeclaration | TableName ) ]
El parámetro idoc
representaría en nuestro caso el parámetro de salida resultante de la ejecución
del sp_xml_preparedocument, en donde especifica la representación interna del
documento XML, el patrón de filas (rowpattern) es el patrón XPATH que permite definir la ruta o nodos que deberá reconocerse
en la lectura del XML, a continuación nuestro código:
SELECT *
FROM
OPENXML(@IdentificadorDoc, ‘/Factura/Lineas/Linea’)
WITH
( FacturaTarget int ‘../../@FacturaID’,
ClienteTarget int ‘../../@ClienteID’,
FechaFacturaTarget datetime
‘../../@FechaFactura’,
FormaPagoTarget int ‘../../@FormaPago’,
DetallesTarget varchar(30) ‘./Descripcion’,
CantidadTarget int ‘@Cantidad’,
PrecioUnitarioTarget float ‘@PrecioUnitario’)
En este caso especifico utilizamos una opción conocida como patrones
de columna, estos contienen un patron XPath para la recuperación de los nodos y
este será relativo al patrón de fila (rowpattern) especificado. Y esto que quiere decir? Que la recuperación
de los nodos estará basada en una expresión o expresiones en donde se navegara
a través de la jerarquía del documento XML para obtener los datos deseados.
Aquí caben notar dos cosas:
OPENXML(@IdentificadorDoc, ‘/Factura/Lineas/Linea’)
Le estamos indicando a la
instrucción que debe tomar la representación interna perteneciente al documento
que acabamos de transformar, posteriormente le indicamos hasta que nivel deseo «navegar»
en la estructura del documento XML.
Posteriormente comenzamos a construir la estructura que deseamos
recuperar, especificando el nombre del campo, su tipo de datos y el origen o expresión XPATH a partir de
donde obtendrá los datos.
WITH
( FacturaTarget int ‘../../@FacturaID’,
ClienteTarget int ‘../../@ClienteID’,
FechaFacturaTarget datetime
‘../../@FechaFactura’,
FormaPagoTarget int ‘../../@FormaPago’,
DetallesTarget varchar(30) ‘./Descripcion’,
CantidadTarget int ‘@Cantidad’,
PrecioUnitarioTarget float ‘@PrecioUnitario’)
El manejo o navegación se realize desde el ultimo nodo que
se especifico en el patron de fila, cabe mencionar que los atributos se
representan por medio de @nombreatributo, el siguiente caso funciona así:
FacturaTarget int ‘../../@FacturaID’
FacturaTarget
int: Es el campo con su respectivo tipo de datos que almacenara el resultado
devuelto por la expresión.
../../@FacturaID: Cabe recordar que
según el patrón de fila este tiene una estructura ‘/Factura/Lineas/Linea’ , en este caso se
quiere recuperar el atributo FacturaID, este se encuentra en el nodo
correspondiente a Factura, por lo que si partimos de la ruta especificada en el
patrón de filas y viendo el documento XML tenemos que subir dos niveles , para
este caso se usa la expresión << ../>>.
En los casos de los atributos que se encuentran en el ultimo
nivel (Linea) solo se debe de anteponer el símbolo @NombreAtributo.
Un caso especial aquí es el del ELEMENTO Descripcion, debido
a su naturaleza y ubicación dentro del XML para obtener su valor se debe de
especificar de la siguiente manera:
./Descripcion’
Aquí le indicamos que seleccione el nodo actual a partir del
nodo raíz (nodo Linea), como punto de ayuda presento una tabla resumen de las
principales expresiones de ruta usadas en XPath.
|
Expresión |
Descripción |
|
nodename |
Selecciona todos los nodos hijos del |
|
/ |
Selecciona a |
|
. |
Selecciona el nodo actual |
|
.. |
Selecciona el padre del nodo actual |
|
@ |
Selecciona atributos |
Con estos pasos descritos anteriormente ya tenemos como
resultado los campos extraidos directamente de un documento XML. Nuestra consulta completa quedaría así:
DECLARE @doc xml
SET @doc = ‘<?xml
version=»1.0″ ?>
<Factura
FacturaID=»1000″ ClienteID=»123″
FechaFactura=»2012-01-14″ FormaPago=»1″>
<Lineas>
<Linea
ProductoID=»12″ Cantidad=»2″
PrecioUnitario=»12.99″><Descripcion>Encendedor marca
Zippo</Descripcion></Linea>
<Linea
ProductoID=»41″ Cantidad=»1″
PrecioUnitario=»17.45″><Descripcion>Ron Flor de
Cana</Descripcion></Linea>
<Linea
ProductoID=»2″ Cantidad=»1″
PrecioUnitario=»2.99″><Descripcion>Bebida embotellada natural</Descripcion></Linea>
</Lineas>
</Factura>’
DECLARE
@IdentificadorDoc int
EXEC sp_xml_preparedocument @IdentificadorDoc
OUTPUT, @doc
SELECT * FROM
OPENXML(@IdentificadorDoc, ‘/Factura/Lineas/Linea’)
WITH
( FacturaTarget int ‘../../@FacturaID’,
ClienteTarget int ‘../../@ClienteID’,
FechaFacturaTarget datetime ‘../../@FechaFactura’,
FormaPagoTarget int ‘../../@FormaPago’,
DetallesTarget varchar(30) ‘./Descripcion’,
CantidadTarget int ‘/@Cantidad’,
PrecioUnitarioTarget float ‘@PrecioUnitario’)
EXEC sp_xml_removedocument @IdentificadorDoc
GO
Espero les haya servido de ayuda y seguimos escribiendo,
pero sobre todo aprendiendo…
Gio
Email: info@geohernandez.com