Una interesante característica nueva que ofrece la versión 2.0 de la plataforma.NET es la de «Tipos anulables» o, en inglés, «Nullable types».
Se trata de un tipo especial de dato que permite que los tipos base por valor se puedan comportar como valores por referencia nulos cuando sea necesario (repasa mi post sobre tipos por valor y por referencia).
De este modo este nuevo tipo anulable permite representar valores concretos o la ausencia de valor. Por ejemplo, una variable de tipo ‘int’ siempre contiene un número entero. Aunque no le asignemos explícitamente nada, al ser un tipo base por valor siempre toma un valor por defecto, en este caso concreto un 0. Pero claro, un 0 no es lo mismo que decir ‘esta variable no contiene valor alguno’.
En el caso de las clases (tipos por referencia) la ausencia de «valor» se representa asignándole un nulo a la variable, pero en los tipos por valor esto no es posible.
¿No sería estupendo disponer de un híbrido entre estos dos comportamientos?
Pues sí. Veamos el porqué…
El caso prototípico en el que esto es muy útil es al obtener ciertos campos desde una base de datos los cuales contienen tipos base (enteros, cadenas, etc…) pero que permiten albergar valores nulos. Este tipo de datos pueden existir (en cuyo caso es un valor concreto) o ser nulos (o sea, no existen). Sin embargo al intentar asignar un valor nulo (o también un System.DBNull) a un tipo por valor como un entero se producirá una excepción. Esto es lo que pasaba en las versiones anteriores de .NET.
¿Cómo se definen?
Para definir un tipo anulable en C# se usa una interrogación al final de la declaración del tipo, así por ejemplo:
int? miEnteroAnulable;
Es decir se declara igual que un entero normal pero con una interrogación.
En VB.NET la sintaxis es diferente y sería así:
Dim miEnteroAnulable As Nullable(Of Integer)
Como vemos en este lenguaje se indica de manera menos sútil, pero ambas declaraciones son equivalentes.
¿Es una onda o es una partícula? ¿Cómo se comporta?
Cuando declaramos un tipo como Nullable, cuando este contiene un valor se comporta a todos los efectos como un tipo por valor, o sea, como siempre. Cuando se le asigna un nulo no se queja (no hay excepción) y, en realidad, se convierte en un tipo por referencia para permitirlo mediante una operación de ‘Boxing’. Es como la luz que es dos cosas al mismo tiempo 😉
Lo que pasa por debajo es que la CLR trata el tipo anulable como una estructura (por lo tanto como un tipo por valor) cuando éste se comporta como un valor, y como una clase (o sea, un tipo por referencia) cuando se comporta como una referencia. Esto lo hace de modo transparente para nosotros.
El tipo Nullable dispone de dos propiedades fundamentales que nos permiten lidiar con él de forma idéntica bien sea una clase o bien una estructura.
La propiedad HasValue nos permite saber si el tipo contiene un valor o por el contrario es nulo.
La propiedad Value nos devuelve el valor subyacente al tipo (un entero o lo que sea) siempre y cuando HasValue sea verdadera. Si intentamos leer esta propiedad cuando HasValue es falsa se genera una excepción de tipo InvalidOperationException.
En resumen…
Los tipos anulables tienen grandes aplicaciones, sobre todo en el mundo de las bases de datos y están integrados en la propia CLR por lo que se pueden usar desde cualqueir lenguaje. Aunque tras haber leído lo anterior te puedan parecer alejados de tus necesidades actuales dales una oportunidad. Una vez que empieces a utilizarlos no podrá vivir sin ellos 🙂
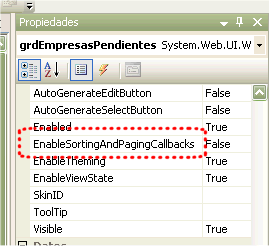 Como es sabido este estupendo control nos permite dotar de funcioalidades de paginación y ordenación de datos a un origen de datos sin necesidad de escribir código alguno. Lo que ya no sabe mucha otra gente es que, además, en la mayoría de los casos se puede conseguir esta funcionalidad sin tener que refrescar la página completa, al más puro estilo AJAX. De este modo al pulsar sobre la cabecera de la rejilla o al cambiar de página se recargan exclusivamente los contenidos de ésta, pero sin realizar un «PostBack» al servidor que fuerza el refresco de la página completa.
Como es sabido este estupendo control nos permite dotar de funcioalidades de paginación y ordenación de datos a un origen de datos sin necesidad de escribir código alguno. Lo que ya no sabe mucha otra gente es que, además, en la mayoría de los casos se puede conseguir esta funcionalidad sin tener que refrescar la página completa, al más puro estilo AJAX. De este modo al pulsar sobre la cabecera de la rejilla o al cambiar de página se recargan exclusivamente los contenidos de ésta, pero sin realizar un «PostBack» al servidor que fuerza el refresco de la página completa. Pero como casi todo en esta vida tiene solución y encima está en Internet 😉 los amigos de RiderDesing.com (especializados en sitios Web ecuestres, lo flipas) han creado un gestor de peticiones para ASP.NET 1.1 que se encarga de que las páginas hechas en ésta versión generen XHTML 1.1 Strict, incluso quitando el atributo ‘target’ de los enlaces y otras lindezas por el estilo.
Pero como casi todo en esta vida tiene solución y encima está en Internet 😉 los amigos de RiderDesing.com (especializados en sitios Web ecuestres, lo flipas) han creado un gestor de peticiones para ASP.NET 1.1 que se encarga de que las páginas hechas en ésta versión generen XHTML 1.1 Strict, incluso quitando el atributo ‘target’ de los enlaces y otras lindezas por el estilo.
 Hace poco un alumno de mi curso de ASP.NET 2.0 de
Hace poco un alumno de mi curso de ASP.NET 2.0 de