Para finalizar las «the a-pelo series» sobre AJAX dedicadas a los Script Callbacks en ASP.NET 2.0 vamos a realizar un ejemplo completo que muestre todo lo que comentamos en los post precedentes.
Nuestro ejemplo será muy sencillo pero suficiente para comprender todo lo explicado hasta ahora. Crearemos una página con una lista de categorías y un botón que, al ser pulsado, mostrará debajo (sin hacer postback) los contenidos de dicha categoría (sin florituras). La siguiente figura muestra la idea:
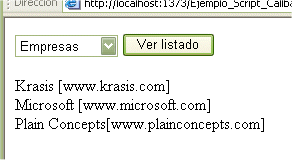
Un poco cutre ¿no? Pero de esta forma obviaremos otro código que nos pueda descentrar de nuestro objetivo que es entender los Script Callback.
Los preparativos
Crea un nuevo proyecto de Visual Web Developer. En la página por defecto (Default.aspx) arrastra un control DropDownList y llámale ‘ddlCategorías‘. Asígnale una lista de elementos (Empresas, Libros, Blogs, Revistas…). No marques su opción de AutoPostBack.
Ahora añade un botón. Pero ojo, muy importante, no nos sirve un botón de ASP.NET (control Web) ya que este tipode control siempre se renderiza como un botón de envío de formulario (submit) y es precisamente eso lo que queremos evitar. Debes utilizar un botón de HTML (o sea un INPUT de toda la vida) arrastrándolo desde la categoría HTML de los controles de ASP.NET. Una vez en el formulario pulsa sobre él con el botón derecho y escoge la opción de ejecutar en el servidor. Llámale ‘cmdVer’.
Para finalizar añade debajo y desde el mismo sitio un a capa (DIV) con el nombre ‘divResultados’ con un estilo que permita que crezca adaptándose a su contenido.
Con todo ello tendrás un código como este para tu página:

Ya tenemos todo lo necesario para crear nuestro ejemplo. Ahora vamos a la «chicha» de verdad.
1.- Realizar las peticiones al servidor.
Lo primero en el orden lógico es pensar cómo vamos a enviar las peticiones al servidor. En nuestro ejemplo lo haremos cuando se pulse el botón, aunque podría ser al cambiar la selección de la lista o con cualquier otro evento de JavaScript que se nos ocurra. es obvio que tendremos que escribir un manejador para el evento ‘onClick’ del botón. El código que debemos incluir para conseguirlo nos lo da el método GetCallbackEventReference estudiado antes. Por lo tanto lo único que debemos hacer es asociarlo al botón en el evento Load de la página. Para ello necesitaremos decidir qué valor se le pasará al servidor durante la llamada, qué función de JavaScript se va a llamar como respuesta final al Callback (resultado), un dato de contexto (no lo usaremos) y el nombre de la función JavaScript que se llama´ra en caso de producirse un error. Por todo ello en nuestro caso escribiremos el siguiente código:
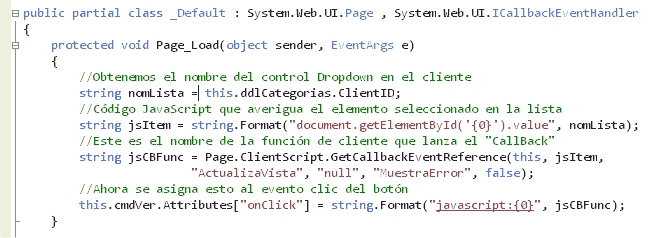
Lo que se hace es en realidad muy sencillo: obtenemos el identificador para la lista desplegable que se usará en el HTML resultante (no tiene porqué coincidir en general con el que le hemos dado en la página ASPX) y con eso construimos una cadena JaVaScript que simplemente sirve para obtener el valor del elemento que esté seleccionado en ésta (este código JavaScript lo almacenamos en la variable jsItem).
A continuación generamos el código JavaScript que va a provocar la llamada al servidor con el método GetCallbackEventReference. Como parámetros se le pasan el control que gestionará el Callback (la propia página, this en C# o Me en VB), el código JavaScript que nos da el valor a enviar al servidor (el elemento seleccionado en la lista), el nombre de la función a llamar tras terminar la petición al servidor (‘ActualziaVista’), el dato de contexto (en este caso un nulo), el nombre de la función JavaScript que se llamará si hay un error en la comunicación, y un booleano que indica si queremos que la llamada sea asíncrona o no (en el listado se ha dejado como síncrona, debería ser true para ser AJAX de verdad).
Por fin se asigna ese código JavaScript al evento ‘onClick’ del botón (que no deja de ser un atributo), con lo que al final, al ejecutar la página obtendremos el siguietne HTMlo para el botón:
<input name=»cmdVer» type=»button» id=»cmdVer» value=»Ver listado» onClick=»javascript:WebForm_DoCallback(‘__Page’,document.getElementById(‘ddlCategorias’).value,ActualizaVista,null,MuestraError,false)» />
2.- Definir la interfaz ICallbackEventHandler
Ahora que ya estamos provocando las peticiones al servidor vamos a definir los métodos que se ejcutarán en éste como resultado de la llamada y que son los que obtienen el resultado a devolver. Como recordarás hay que implementar dos. En nuestro ejemplo el código sería:

Si nos fijamos el código es muy sencillo. Hemos eliminado acceso a datos y otras cuestiones para centrarnos en lo que nos ocupa, así que según el valor que se pasa al método (la selección de la lista desplegable) anotamos una u otra lista de elementos separados por comas en una variable. El contenido de ésta es lo que se devuelve en el método GetCallbackResult y por lo tanto lo que se le pasa al cliente como resultado. Listo.
3.- Implementar las funciones de recepción de resultados en el cliente
Por fin sólo nos resta una cosa y es decidir qué hacemos con los resultados una vez que se termine la llamada. En nuestro caso haremos algo muy sencillo: separaremos los elementos recibidos como resultado sustituyendo las comas por retornos de carro (<BR/> en HTML) y esta cadena resultante la introduciremos directamente en el <DIV> de resultados que hemos incluido. El código JavaScript es muy sencillo:

Fijémosos en las funciones. La primera de ellas es general y se usa desde las otras dos simplemente para introducir el HTML que queramos dentro del DIV. Las otras dos funciones son la implementación de los métodos de resultado y de error y que deben tener exactamente los mismos nombres que escogimos en el paso 1, al general la llamada al servidor. En el primer caso se sustituyen las comas por un retorno de carro y en el caso del error se muestra el mensaje de error en el DIV en lugar de los resultados. Así de sencillo.
En ejemplos reales podríamos hacer cosas mucho más complejas con HTML dinámico, todo dependerá de nuestro dominio de JavaScrpit.
Una última cosa: para simular un error hemos incluido un elemento en la lista (el último) que cuando se elige provoca un código de estado HTTP 500 en el servidor (código estándar para errores en el servidor), de modo que en el navegador se interpreta como si fuese un error en nuestra página ASPX y se fuerza así la llamada a la función de error para así poder verificarla.
En definitiva
Espero que todo esto te haya resultado interesante. Puedes descargarte el código de ejemplo para probarlo sin tener que escribirlo pulsando aquí (3,12 Kb).
Esta técnica tiene muchas aplicaciones, aunque la verdad es que queda un poco deslucida si la comparamos con las posibilidades que nos da Atlas para ASP.NET. Ahora bien, para muchos casos sencillos en los que no queramos (o no podamos) instalar Atlas o que no se justifique la carga adicional relacionada resultará una opción más simple y segura que usar AJAX «super-a-pelo» como hemos visto hace tiempo 🙂


 Estos días he estado leyendo un libro que, la verdad, me ha resultado de lo más interesante y por eso lo reseño aquí. Se trata de ‘SPAM’, ISBN:84-415-1864-5 de Anaya Multimedia y autor anónimo (firma como spammer-X).
Estos días he estado leyendo un libro que, la verdad, me ha resultado de lo más interesante y por eso lo reseño aquí. Se trata de ‘SPAM’, ISBN:84-415-1864-5 de Anaya Multimedia y autor anónimo (firma como spammer-X). Aunque falta bastante para que aparezca definitivamente en el mercado Windows Vista, pero el gigante de Redmond ha alcanzado un acuerdo con el fabricante de refrescos
Aunque falta bastante para que aparezca definitivamente en el mercado Windows Vista, pero el gigante de Redmond ha alcanzado un acuerdo con el fabricante de refrescos