Igual a alguien es util. El PDF atachado lo tiene a mejor resolución.
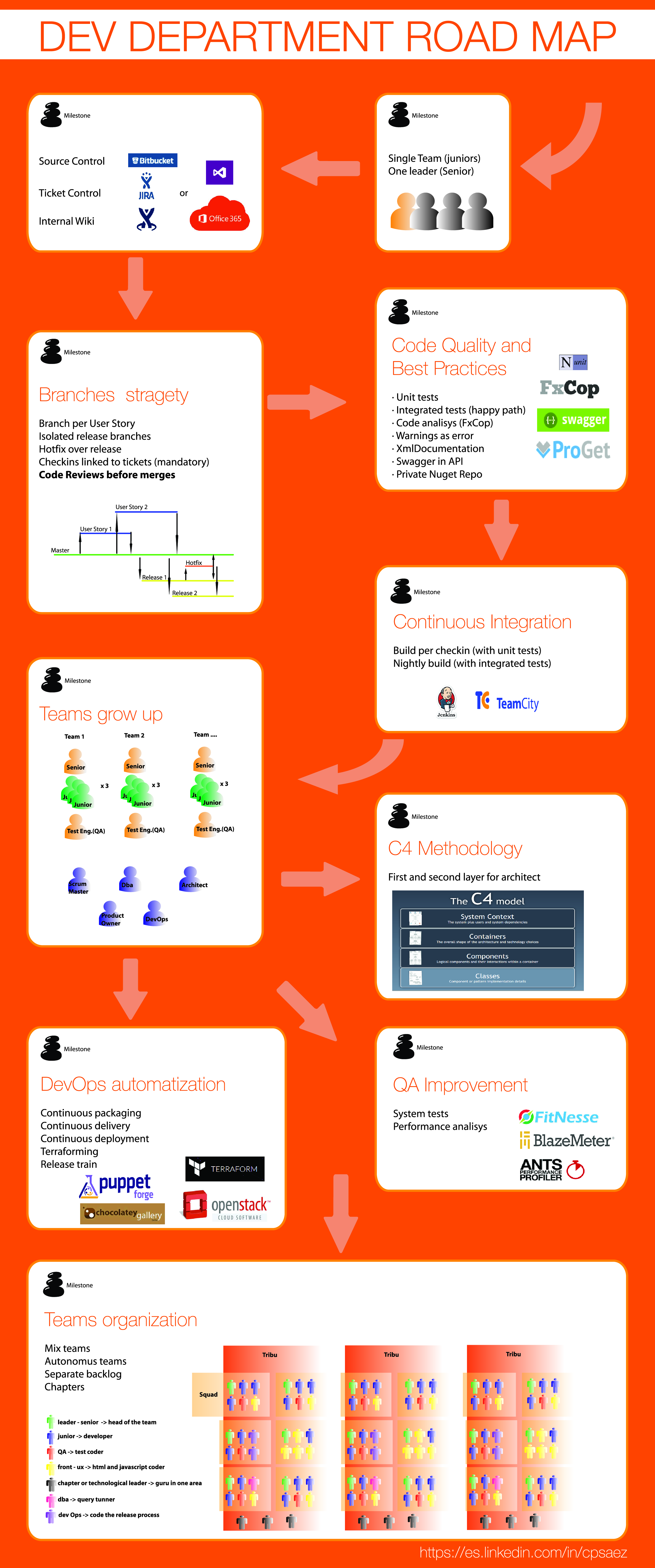
Igual a alguien es util. El PDF atachado lo tiene a mejor resolución.
Donde trabajo, estamos en pleno proceso de fichajes para el equipo .net, tanto seniors como juniors con poca o ninguna experiencia profesional. Dejo la propuesta por si alguien no está contento en su trabajo y se quiere venir a un equipo muy joven, internacional y con ganas de hacer las cosas bien. No es consultoria, tenemos producto propio, del cual sacamos releases cada muy poco, a un ritmo bastante frenético, con lo que se puede crecer, y mucho, dentro del equipo.
Dejo la oferta «oficial», si alguien le interesa, que me escriba a cpsaez@gmail.com y quedamos para hablar, enseñar donde trabajamos y ese tipo de cosas. Es presencial para Madrid, zona Pio XII, bien comunicado, aunque se valoraria el teletrabajo.
Your responsibilities:
Design and develop new features and functionality for high transaction, large scale system
Create and extend public/private facing APIs
Participate in design and code reviews
Identify and address performance bottlenecks in the existing software
Design solutions that are modular, scalable and portable
Design and create unit test cases and make your code work seamlessly in a continuous integration environment
Comply with change control, source control and configuration management tools and practices
Follow and promote software development best practices and maintain the highest quality of delivered software
Provide 3rd line support and troubleshooting when required
Your Profile:
Demonstrable talent coding in C# with in real-time, multi-tier, multithreading, back-end systems where high performance and availability are key. (5+ years working experience on .Net technology is a must)
Strong technical background in software design patterns and architecture
Database development and design experience (ideally SQLServer)
Understanding of REST based architecture as well as SOAP/XML
Knowledge using version control systems (ideally TFS)
A bachelor’s degree in a traditional science subject, ideally computer science, engineering, or information systems
Ideally some experience in gambling applications
The ideal candidate would also have:
Knowledge of Web technologies and internet protocols (XML, HTTP, TCP/IP, ASP.NET)
Knowledge of WPF/HTML5/Javascript
Strong understanding of WCF and Entity framework
Good level in futbolin is strongly recommended 😉
SCRUM
Donde trabajo, estamos en pleno proceso de fichajes de cracks .net, se paga muy bien. Dejo la propuesta por si alguien no está contento en su trabajo y se quiere venir a un equipo muy joven, internacional y con ganas de hacer las cosas bien. No es consultoria, tenemos producto propio, del cual sacamos releases cada muy poco, con lo que se puede crecer, y mucho, dentro del equipo.
Dejo la oferta «oficial», si alguien le interesa, que me escriba a cpsaez@gmail.com y quedamos para hablar, enseñar donde trabajamos y ese tipo de cosas.
Your
responsibilities:
Design and develop new features and functionality for
high transaction, large scale system
Create and extend public/private facing APIs
Participate in design and code reviews
Identify and address performance bottlenecks in the
existing software
Design solutions that are modular, scalable and
portable
Design and create unit test cases and make your code
work seamlessly in a continuous integration environment
Comply with change control, source control and
configuration management tools and practices
Follow and promote software development best practices
and maintain the highest quality of delivered software
Provide 3rd line support and troubleshooting when
required
Your
Profile:
Demonstrable talent coding in C# with in real-time,
multi-tier, multithreading, back-end systems where high performance and
availability are key. (5+ years working experience on .Net technology is a
must)
Strong technical background in software design
patterns and architecture
Database development and design experience (ideally
SQLServer)
Understanding of REST based architecture as well as
SOAP/XML
Knowledge using version control systems (ideally TFS)
A bachelor’s degree in a traditional science subject,
ideally computer science, engineering, or information systems
Ideally some experience in gambling applications
Fluency in English
The ideal candidate would also have:
Knowledge of Web technologies and internet protocols
(XML, HTTP, TCP/IP, ASP.NET)
Knowledge of WPF/HTML5/Javascript
Strong understanding of WCF and Entity framework
Good level in futbolin is strongly recommended 😉
SCRUM
Tal como comento en Barrapunto, han publicado un nuevo borrador del protocolo HTTP2. Según el borrador, Http2 provee una forma eficiente de serializacion de la semantica HTTP, será capaz de multiplexar diferentes peticiones HTTP sobre una misma conexión y de forma concurrente mediante el uso de streams con control de flujo y priorización y, además, soportará server push, es decir, poder forzar que el servidor mande datos al browser o cliente sin que este los pida por encuesta, tal como se hace ahora. Otra de las novedades es que http y https podrá compartir puerto ya que sobre la misma URI podrán ser mandados diferentes streams. Como nota curiosa, dicho protocolo nos permite hacer ping directamente al servidor web. Si te interesa saber más, recomiendo la lectura directamente del borrador.
Todo esto realmente no es “nuevo” ya que desde hace tiempo existen dos propuestas sobre la mesa, SPDY de Google y S+M (Speed+Mobility) de Microsoft. La mayor diferencia es que el server push (enviar un mensaje del servidor al browser, adios javascript en background para actualizar datos en tiempo real), en el modelo del borrador y SPDY esta totalmente acoplado, pero en el de Microsoft es una extensión opcional para evitar, sobre todo, gastos de bateria y consumo de red en dispositivos móviles y redes “metered”.
No sabemos si está tecnología se acabará usando o si HTTP 1.1 será tan reticente a cambiar como IPv4, pero creo que no hay que perder de vista estas propuestas ya que, por lo que parece, IE 11 va a soportar SPDY (Chrome y Firefox ya lo hacen más o menos). Si te puede el ansia y quieres probarlo ya existe un modulo para Apache (que no he probado) pero para IIS, nada.
NopCommerce es una aplicación opensource (licencia NPL+) para montarte tu tienda Online bastante completa y con una comunidad alrededor bastante fuerte. Como «caracteristica» es que funciona en
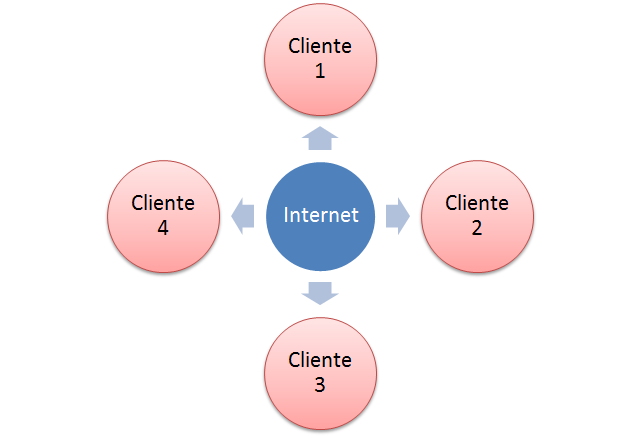
Últimamente esta muy en boca las nuevas características de conexión p2p entre navegadores. Es decir, un browser se comunica directamente con otro, sin necesidad de servidores que intervengan durante todo el ciclo de la comunicación, solo para determinadas tareas, normalmente el inicio del dialogo entre los navegadores. Dichas características se están empleando sobre todo para realizar streaming de contenido multimedia entre navegadores. ¿Pero como es posible dicha mágia?.
Para establecer una conexión de un punto a otro, en redes IP, necesitamos una dirección, un puerto, un protocolo (TCP o UDP normalmente) y dos participantes, el iniciador o cliente y el que escucha (listener). El listener estará escuchando por un puerto y cuando el iniciador se conecte a el, empezara una serie de intercambios de información entre el iniciador y el listener. Esta es la teoría conocida por todos en conexiones punto a punto. ¿Cual es el problema?, que Internet hace tiempo que dejo de ser una topología de IPs donde todas se veían entre todas.
A día de hoy la arquitectura predominante, por motivos de seguridad y de economía de direcciónes IP, son las subredes detras de routers haciendo NAT.
 Es decir, que una conexión p2p desde el cliente 1 al cliente 3 que esté detras de un NAT, es complicado a no ser que abramos puertos en el NAT que apunten directamente al cliente, haciendo la traslación de red.
Es decir, que una conexión p2p desde el cliente 1 al cliente 3 que esté detras de un NAT, es complicado a no ser que abramos puertos en el NAT que apunten directamente al cliente, haciendo la traslación de red.
 En la anterior figura, si un iniciador quiere conectarse al cliente 1, puerto 80, tendrá que conectarse en realidad a la IP 80.80.80.43, tambien llamada IP pública ya que el router, en su configuración NAT, todo que llege al puerto 80 por la IP pública lo enrutará a la IP del cliente 1, al puerto 80 u otro puerto.
En la anterior figura, si un iniciador quiere conectarse al cliente 1, puerto 80, tendrá que conectarse en realidad a la IP 80.80.80.43, tambien llamada IP pública ya que el router, en su configuración NAT, todo que llege al puerto 80 por la IP pública lo enrutará a la IP del cliente 1, al puerto 80 u otro puerto.
Entonces, en una arquitectura así, ¿como es posible realizar p2p?. Si alguien ha trasteado con los tipicos clientes p2p, como torrent o emule, para tener la máxima velocidad habrán tenido que “abrir los puertos” en el router, es decir, configurar el NAT del router. Esta solución es un poco inviable ya que por cada aplicación que quiera usar las características p2p, deberíamos abrir un puerto en el router con los consiguientes problemas de administración de la red. Existen otras soluciónes más dinámicas y normalmente se trata de “engañar” al router. Para engañar al router se suelen seguir varias estrategias en función de si uno o los dos clientes están detras de un NAT.

En este caso un dispositivo conectado a internet con una IP pública intenta establecer una conexión p2p con un dispositivo detras de un NAT y no puede ya que la IP privada no es accesible desde internet. Como no queremos abrir puertos en el NAT, se suele recurrir a una conexión pasiva con ayuda de un tercero.

En el dibujo se puede ver como el dispositivo recurre a ayuda de un tercer, un servidor, para anunciar su disponibilidad de servicio, manteniendo una conexión con el servidor.
Cuando el dispositivo cliente o iniciador quiere conectarse, lanza la petición al servidor y el servidor comunica al listener que abra una conexión con el cliente. En el momento que el cliente detecta dicha conexión de entrada, empieza el intercambio de información como si la conexión la hubiese abierto el.
Este es el escenario más habitual y más complejo de resolver, aunque a día de hoy ya con exito.

Dos dispositivos detras de NAT, con lo cual ninguno puede abrir una conexión con el otro. En este caso vamos a empezar en como se resuelve cuando queremos usar el protocolo UDP, el cual no está orientado a conexión, no garantiza la recepción ni el orden de llegada de los paquetes y es mas rápido, por lo tanto candidato ideal para hacer streaming donde no importa perder paquetes ni el orden, ya que como mucho tendremos peor calidad, pero seguiremos manteniendo la comunicación en tiempo real y con baja latencia.
Esta palabreja (UDP Hole Punching) nombra una técnica donde los dos clientes mantienen una conexión activa UDP anunciándose en un servidor Rendezvous o de citas. En el momento que un dispositivo quiere abrir una conexión p2p, preguntará al servidor Rendezvous su IP pública y empezará a inyectar paquetes por dicha conexión suplantando al servidor Rendezvous.
 La técnica tiene su intriga pero puede verse más información en esta url donde describen los pasos para saber si los dos dispositivos están detras del mismo NAT o no y diferentes tecnicas.
La técnica tiene su intriga pero puede verse más información en esta url donde describen los pasos para saber si los dos dispositivos están detras del mismo NAT o no y diferentes tecnicas.
http://www.brynosaurus.com/pub/net/p2pnat/

Un servidor STUN (Simple traversal of User Datagram Protocol) es simplemente un servidor rendezvous descrito en el punto anterior, pero estandarizado bajo la norma RFC 3489. STUNT, con T al final, es lo mismo pero aceptando el protocolo TCP, pero no suele ser muy habitual.
Por tanto, y volviendo al tema original, esta claro que si queremos conseguir una comunicación de browser a brwoser, necesitaremos un servidor STUN, entre otras cosas.
Hoy en dia existe una corriente muy fuerte para llevar el p2p al navegador y ya se van viendo proyectos donde usan dicha técnica para poder comunicarse, como pro ejemplo WebRTC
Este proyecto está basado sobre todo en la transmisión multimedia, con lo que dentro de su arquitectura ya contempla diferentes codecs de audio y video.

Si nos fijamos en la capa de transporte, sección p2p, veremos STUN, además de una extensión llamada TURN y ICE, un protocolo de agentes que se apoyan en STUN/TURN.
Espero que con esta pequeña introducción ya no sea tan mágico como funciona las conexiones p2p hoy en día.
Integración continua es tener un sitio donde, periódicamente, tus proyectos se compilen y se lancen los tests para que el código fuente este sano, es decir, que cualquiera que se lo baje sepa que esta funcionando y nos olvidemos de “en mi máquina funciona”.
En el mundo .NET es muy habitual tener un TFS y las builds configuradas dentro del mismo, pero si no tenemos un TFS por lo que sea, podemos usar HUDSON para montarnos nuestro entorno de CI.
Hudson es un veterano del mundo UNIX/Linux que ha sido portado a Windows en forma de ejecutable stand-alone, para lanzarlo manualmente cuando lo necesitemos, o como servicio de Windows donde está disponible continuamente, ademas de poseer un montón de módulos y plugins para conectarlo con cualquier repositorio que se te ocurra y realice una compilación de casi cualquier lenguaje. Todo ello manejado desde una simple interface web.
Hudson está echo en JAVA así que lo primero que toca es bajarse la ultima máquina virtual si no la tienes ya e instalarla. Después nos bajamos el último war de la web de Hudson y lo descomprimimos en una carpeta donde tengamos mucho espacio ya que por defecto, las builds se ejecutaran dentro del mismo (se puede configurar). Si lo piensas montar como servicio, déjalo en el escritorio, abre una consola (cmd) y ejecuta
java –jar hudson.war.
En estos momentos Hudson lanzará un sencillo servidor web en el puerto 8080, entrando con nuestro navegador favorito a http://localhost:8080 nos aparecerá un menú tal que así:

Pinchando en instalarlo como servicio, ahora sí, tendremos que especificar una carpeta donde quedará instalado permanentemente

Una vez instalado el mismo nos da la opción de parar la instancia actual de Hudson, que recordemos es plenamente funcional, y logarnos en nuestra nueva instalación de Hudson como servicio.

Si nos vamos a los servicios del sistema, veremos a la nueva criatura

Yo recomiendo dejarlo como arranque automático.

Si queremos que Hudson escuche en otro puerto diferente a 8080, nos tenemos que ir a la carpeta de instalación y cambiar dentro del fichero Hudson.xml la siguiente linea:
<arguments>-Xrs -Xmx256m -Dhudson.lifecycle=hudson.lifecycle.WindowsServiceLifecycle -jar «%BASE%hudson.war» –httpPort=8050</arguments>
Cambiando el puerto al 8050 por ejemplo
Para configurar que Hudson pueda compilar .NET, tenemos que activar el plugin correspondiente, no tenemos que instalar nada ya que se baja automáticamente.
Nos vamos al panel de control de Hudson
Pulsamos en Manage Hudson y en Manage Plugins

Buscamos el MSBuild Plugin y el MSTest plugins (si queremos tener en cuenta tests unitarios), los marcamos y pulsamos en instalar.
Una vez instalados los plugis debería quedar el listado de Installed tal que así:

Hay un montón de plugins así que si os parece util la herramienta, conviene darle un vistazo a la lista de disponibles, sobre todo si usamos repositorios como TFS o Sourcesafe, que no vienen activos por defecto.
Una vez tenemos los plugins listos, tenemos que configurar la compilación con MSBuild (el plugin que acabamos de instalar), con lo que nos vamos a configure system

donde veremos una sección de MSBuild. Aquí hay que ponerle el path al ejecutbale MSBuild.exe, en mi caso:
C:WindowsMicrosoft.NETFramework64v4.0.30319MSbuild.exe
y darle un nombre identificativo.
Podemos configurar más de un entorno de compilación, por si queremos usar .NET 2.0 o .NET 4.0 indistintamente
También conviene darle un repaso a todas las opciones pero una muy util es las configuraciones por mail (al final del todo). Si cuando acabe una build y esta falla, queremos avisar a quien a enviado la build, conviene configurar el Email suffix escribiendo por ejemplo “@midominio.com”. Si bob hace un checkin al código y rompe la build, Hudson enviará un correo a bob@midominio.com
Cuando terminemos de configurar todo no hay que olvidar de darle al boton save al final de la página.
Vamos a ordenar a nuestro nuevo mayordomo una nueva tarea, que es la compilación de un proyecto que tenemos en el SVN cada vez que alguien haga checkin y suba nuevos cambios.
Navegamos hasta https://localhost:8080 ( o la ip del servidor) y pulsamos en New Job
Damos un nombre al trabajo, por ejemplo: Branch-8876 o «mi superbuild» (es solo una descripción) pulsamos en Build free-style software project. (podemos clonar un trabajo existente, muy util si cambiamos solo la rama donde esta nuestro proyecto en el repositorio).
Pulsamos en ok y en la siguiente página tendremos que configurar las propiedades de nuestra tarea. Yo recomiendo modificar las siguientes:
-Discard old builds para tener solo la compilación mas reciente y no usar espacio en disco duro de forma innecesaria
-Source code management: En mi caso va a acceder a una rama de SVN, con lo que poniendo la dirección http del servidor de source safe bastaría, ejemplo:
Y como quiero integración continua, usaré la estrategia Use svn update as much as possible y Clean checkout folders and then checkout para que cada vez que se lance una compilación me baje todo el código de nuevo.
En los disparadores de la build, si queremos que se ejecute en cada checkin, hay que elegir Poll SCM y en el schedule la siguiente opción “* * * * *”. Si quisiéramos lanzarla cada día a las 2 y media de la noche, escribiríamos “2 30 * * *” por ejemplo.
En el apartado build debemos elegir el que configuramos previamente y como fichero de build, elegiremos nuestro fichero sln que contiene la solución. Hudson lanzará “MSBuild fichero elegido” y entenderá el output del mismo, indicando si ha habido algún error o ha ido todo bien.
Cuando terminemos no olvidemos pulsar el botón save.
Y ya está, en la pantalla principal podremos ver todas las builds que están ejecutándose y si alguna ha ido mal con su icono rojo correspondiente ( en esta nueva versión si va todo bien aparece un sol y si va mal un icono de tormenta)

Ah, decir que es una aplicación inmensa y que tiene soporte de esclavos para distribuir los diferentes builds en escenarios complejos.
Ya no tenemos excusa para no montar un entorno de integración continua en nuestro entorno en una tarde y empezar a usarlo desde el primer día. Con una máquina modesta nos servirá para lanzar una build cada cinco minutos y dejar de esperar ese TFS que nunca llega por falta de recursos, máquinas disponibles o pánico a la nube del nuevo cloud TFS.

Hola.
Aqui donde estoy trabajando, en Irlanda, están DESESPERADOS por encontrar gente que controle de Microsoft Dynamics. Si piensas que tu ingles es regulero, no importa, son comprensivos. Si te interesa trabajar en una zona tranquila, de 9:00 a 17:30 en un buen ambiente y controlas de Dynamic tanto version 4 como 2011 y te apetece venirte para Irlanda, contacta conmigo en cpsaez@gmail.com.
Saludos.
Normalmente, cuando hacemos una aplicación de escritorio o servicio de Windows, intentamos, mediante try – catch de los métodos principales, evitar fallos catastróficos. Pero lo que se suele desconocer es que hay una última barrera de defensa en esta propiedad llamada UnhandledException de nuestro app domain.
En este ejemplo estoy blindado la ejecución de un servicio. Si algo falla que no esté controlado, antes de que se pare el servicio, nuestro código del segundo método se ejecutará sí o sí:
1: static void Main()
2: {
3: ServiceBase[] ServicesToRun;
4:
5: ServicesToRun = new ServiceBase[] { new BatcherService() };
6: AppDomain.CurrentDomain.UnhandledException += new UnhandledExceptionEventHandler(CurrentDomain_UnhandledException);
7: ServiceBase.Run(ServicesToRun);
8: }
9:
10: static void CurrentDomain_UnhandledException(object sender, UnhandledExceptionEventArgs e)
11: {
12: ...
13: }
Ideal para esos logs de ultima hora que nos pueden servir para ver por qué realmente ha fallado. En el argumento e tenemos toda la información de la excepción tal como vemos en esta captura de la ayuda contextual.

Esto también sirve en aplicaciones WPF, Winforms etc… Espero que a alguien le sea útil.
Nota: Es conveniente que el código que metamos aquí sea ultra ligero para evitar problemas como matar el proceso a mano porque el servidor sql encargado de guardar los logs da time – out por ejemplo 😉
Update: Si queremos la aplicación termine evitando las molestas ventanas de error, debemos usar el método Enviroment.Exit()
1: static void CurrentDomain_UnhandledException(object sender, UnhandledExceptionEventArgs e)
2: {
3: try
4: {
5: Exception ex = (Exception)e.ExceptionObject;
6: // logeamos
7: }
8: finally
9: {
10: Environment.Exit(…);
11: }
12: }
Con ello, terminaremos la ejecución, dicho de forma rápida, antes de que la excepción llegue hasta el S.O y saqué dichas ventanas.
Todo el mundo sabe que es un contexto de entity framework… ok
http://msdn.microsoft.com/en-us/library/system.data.objects.objectcontext.aspx
Todo el mundo sabe que son los interceptors de Unity… ¿ok? (Es un mecanismo para poder lanzar código antes y después de que un método se ejecute)
http://msdn.microsoft.com/en-us/library/ff647107.aspx
Si interceptamos un contexto con Unity tal que así
1: container.RegisterType<MyEntities, MyEntities>(
2: "auditable",
3: new PerThreadLifetimeManager(),
4: new InjectionConstructor(),
5: new Interceptor<VirtualMethodInterceptor>(),
6: new InterceptionBehavior<AuditableContextBehavior>());
(MyEntities es algo que hereda de ObjectContext y tiene un método llamado SaveChanges que vamos a auditar.(
Y AuditableContextBehavior es algo tal que así:
1: public class AuditableContextBehavior : Microsoft.Practices.Unity.InterceptionExtension.IInterceptionBehavior
2: {
3: /// <summary>
4: /// Gets a value indicating whether this behavior will actually do anything when invoked.
5: /// </summary>
6: public bool WillExecute
7: {
8: get
9: {
10: return true;
11: }
12: }
13:
14: /// <summary>
15: /// Returns the interfaces required by the behavior for the objects it intercepts.
16: /// </summary>
17: /// <returns>
18: /// The required interfaces.
19: /// </returns>
20: public IEnumerable<Type> GetRequiredInterfaces()
21: {
22: return Type.EmptyTypes;
23: }
24:
25: /// <summary>
26: /// Implement this method to execute your behavior processing.
27: /// </summary>
28: /// <param name="input">Inputs to the current call to the target.</param>
29: /// <param name="getNext">Delegate to execute to get the next delegate in the behavior chain.</param>
30: /// <returns>
31: /// Return value from the target.
32: /// </returns>
33: public Microsoft.Practices.Unity.InterceptionExtension.IMethodReturn Invoke(Microsoft.Practices.Unity.InterceptionExtension.IMethodInvocation input, Microsoft.Practices.Unity.InterceptionExtension.GetNextInterceptionBehaviorDelegate getNext)
34: {
35: if (input == null)
36: {
37: throw new ArgumentNullException("input");
38: }
39:
40: if (getNext == null)
41: {
42: throw new ArgumentNullException("getNext");
43: }
44:
45: // Audit the entities, the new entities will be delayed.
46: IEnumerable<ObjectStateEntry> entriesDelayed = this.PreSaveChanges(input);
47:
48: // get next handler
49: IMethodReturn message = getNext()(input, getNext);
50:
51: // Audit the delayed entities
52: this.PostSaveChanges(entriesDelayed);
53:
54: // return the result of the interceptors
55: return message;
56: }
57:
58: /// <summary>
59: /// Execute code after the method
60: /// </summary>
61: /// <param name="input">The input.</param>
62: /// <returns>Entities delayed to audit</returns>
63: [System.Diagnostics.CodeAnalysis.SuppressMessage("Microsoft.Design", "CA1031:DoNotCatchGeneralExceptionTypes", Justification = "We can never stop the execution for a error in this method")]
64: private IEnumerable<ObjectStateEntry> PreSaveChanges(Microsoft.Practices.Unity.InterceptionExtension.IMethodInvocation input)
65: {
66: IEnumerable<ObjectStateEntry> entriesToAdd = null;
67:
68: try
69: {
70: if (input.MethodBase.Name == "SaveChanges")
71: {
72: ...
73: }
74: }
75:
76:
77: }
78: catch (Exception ex)
79: {
80: ...
81: }
82:
83: return entriesToAdd;
84: }
85:
86: /// <summary>
87: /// Execute code after the method SaveChanges.
88: /// </summary>
89: /// <param name="entriesToAdd">The entries to add.</param>
90: [System.Diagnostics.CodeAnalysis.SuppressMessage("Microsoft.Design", "CA1031:DoNotCatchGeneralExceptionTypes", Justification = "We can never stop the execution for a error in this method")]
91: private void PostSaveChanges(IEnumerable<ObjectStateEntry> entriesToAdd)
92: {
93: // the entries marked to added must be logged at the end of the method to log the state
94: if (entriesToAdd != null && entriesToAdd.Count() > 0)
95: {
96: ...
97: }
98: }
99: }
¿Que ocurre cuando el método interceptado lanza una excepción? ¿Se para todo?
Pues no, si el método getNext devuelve una excepción, PostSaveChanges tambien se ejecutará y en mi caso no tiene sentido. Para evitar eso hay que hacer una comprobación tal que así (en amarillo)
1: if (input == null)
2: {
3: throw new ArgumentNullException("input");
4: }
5:
6: if (getNext == null)
7: {
8: throw new ArgumentNullException("getNext");
9: }
10:
11: // Audit the entities, the new entities will be delayed.
12: IEnumerable<ObjectStateEntry> entriesDelayed = this.PreSaveChanges(input);
13:
14: // get next handler
15: IMethodReturn message = getNext()(input, getNext);
16:
17: // if an exception is produced in the SaveChanges method of the context, it doesn't make sense save the state of the entities
18: if (message.Exception != null)
19: {
20: // Audit the delayed entities
21: this.PostSaveChanges(entriesDelayed);
22: }
23:
24: // return the result of the interceptors
25: return message;
Tenerlo en cuenta porque la inercia es usar el result para logear o lo que sea pensando que siempre está disponible y no, en caso de excepción, la vida sigue en el interceptor y luego, dentro del método interceptado, es cuando saltará la excepción, nunca antes

{kind=link}