SSDS es un almacén de datos, que utiliza las tecnologías de SQL Server y expone su funcionalidad a través de interfases de servicios Web y protocolos abiertos. Como servicio provee su propio modelo de datos y de provisionamiento para operarlo y está diseñado para ser un servicio Web 2.0 proporcionando interfases SOAP y REST.
La idea de usar un servicio de datos en vez de una base de datos en las premisas del cliente es no tener que lidiar con costos de la tecnología en sí (licenciamiento de software + adquisición de hardware) ni con estimaciones de requerimientos de procesamiento y de planeación de capacidad.
El Modelo de Provisionamiento
El modelo de provisionamiento de SSDS, consiste en un modelo de entidades flexibles. Antes de explicar el modelo de entidades flexibles eviten asociar la palabra entidad con Entity Framework, cuyo modelo de entidad es diferente. Las entidades de SSDS no tienen un esquema asociado con ellas, o sea son schemaless, no tienen una estructura definida, sino que son un conjunto de propiedades, en donde cada propiedad es una dupla nombre/valor.
El modelo tiene 3 elementos: autoridad, contenedor y entidad, la siguiente figura muestra una analogía del modelo de provisionamiento ACE de SSDE y el modelo de provisionamiento relacional de SQL Server.

Para comenzar a almacenar datos se debe haber creado al menos una autoridad. La creación de una autoridad SSDS crea un nombre de DNS para poder referenciarla. Por ejemplo: como SSDS está hosteado en data.beta.mssds.com, si creamos una autoridad (base de datos) llamada fernik, SSDS crea la autoridad y la hace accesible en fernik.data.beta.mssds.com, lo cual revela que los nombres que elijamos para autoridades deben seguir las reglas y convención de nombres de DNS, así que olvidándose de elegir nombres con notación camel. Además la autoridad es una unidad de geo-ubicación, esto quiere decir que si se crean 2 autoridades como fernik.america.data.beta.mssds.com y fernik.europa.data.beta.mssds.com se han creado en diferentes datacenters en donde está hosteado SSDS. La idea de crear autoridades en diferentes datacenters es de disponer los datos lo más cerca posible de los usuarios que consumirán el servicio. Actualmente hay un datacenter de SSDS en Norteamérica (data.beta.mssds.com).
Como en el modelo relacional una base de datos es una colección de tablas en el modelo de SSDS, una autoridad es una colección de contenedores. La diferencia es que cuando se crean contenedores no se define o adjunta un esquema, en cambio cuando se crea una tabla hay que proporcionar información sobre la estructura de la misma. Esta independencia de los contenedores respecto de un esquema permite almacenar en ellos entidades tanto homogéneas como heterogéneas. Lo cual no es el caso de una tabla relacional la que sólo nos permite almacenar filas homogéneas. Así se plantean 2 modelos de uso según las necesidades de la aplicación:
Modelo Homogéneo: El contenedor almacena entidades del mismo tipo. En este modelo el contenedor se comporta como una tabla en una base de datos relacional.
Modelo Heterogéneo: El contenedor almacena entidades de diferentes tipos. En este modelo el contenedor se comporta como una base de datos que almacena entidades de todo tipo.
En el release actual de SSDS las consultas tienen ámbito de contenedor, todavía no es posible realizar consultas entre contenedores (lo que equivale a consultas entre tablas en el modelo relacional), pero como los contenedores pueden almacenar entidades heterogéneas es posible almacenar todas nuestras entidades en un único contenedor y realizar la consulta sobre el mismo.
Una entidad es el equivalente a una fila en el modelo relacional. Consiste en un conjunto de propiedades en forma de pares nombre/valor (como un objeto Dictionary o un array asociativo). El valor puede ser un tipo escalar simple, actualmente los siguientes tipos escalares son soportados: string, binary, boolean, decimal y datetime.
Una entidad es el objeto más pequeño que puede ser actualizado. Esto implica que se puede obtener una entidad, agregar/actualizar/eliminar propiedades y luego reemplazar la entidad original con la modificada. Las actualizaciones parciales no son soportadas por ahora.
El Modelo de Datos
La entidad flexible es el concepto fundamental en SSDS. Tanto autoridades, contenedores como entidades son entidades flexibles. Cada una de estas entidades consiste en propiedades en forma de pares nombre/valor se agrupan en 2 categorías: Metadatos y Flexibles.
Propiedades de Metadatos: Cada entidad posee in conjunto fijo de propiedades (Id, Version y Kind). Estas propiedades se denominan propiedades de metadatos. La propiedad Id identifica unívocamente a la entidad y debe ser única dentro del contenedor en el que existe, pero diferentes contenedores pueden contener entidades con el mismo Id. La propiedad Version actúa como un timestamp o marca de tiempo y se emplea para identificar la versión actual de la entidad. El valor de la propiedad Version se actualiza con cada operación que se realiza sobre la entidad. El valor de la propiedad Kind es definido por el usuario y se utiliza para categorizar entidades similares. No hay que olvidarse de que como no existe un esquema asociado a las entidades, por lo que tener entidades con el mismo valor de la propiedad Kind no garantiza la misma estructura.
Propiedades Flexibles: Además de las propiedades de metadatos, una entidad puede tener 0 o más propiedades flexibles adicionales. Estas propiedades es en donde se almacenan los datos de la aplicación. Las propiedades flexibles pueden tener cualquier nombre y valor de los siguientes tipos escalares: string, decimal, bool, datetime y binary.
Para verificar que toda autoridad, contenedor y entidad es una entidad flexible vamos inspeccionar el modelo de objetos de SSDS. Para ello es necesario agregar una referencia a al servicio SSDS.

Luego, si inspeccionamos el modelo de objetos con Object Browser se aprecia que la clase Entity del modelo ACE es en sí la entidad flexible, ya que se emplea para modelar el resto de las entidades del modelo ACE.


Ahora bien, si observamos el código del proxy generado las propiedades de metadatos son realmente propiedades definidas explícitamente, es decir tienen un nombre propio y un tipo, responden a un esquema. Sin embargo a lo que llamamos propiedades flexibles se las modela como un Diccionario genérico parametrizado con <string, object>, o sea que las propiedades flexibles están definindas como pares nombre/valor que son miembros de una colección. Al implementar las propiedades flexibles de esta forma se alcanza una flexibilidad similar a la del DataSet/DataTable no tipado pero al costo que tiene cualquier abstracción no tipada: verificación en tiempo de ejecución.
También es importante destacar el uso del atributo KnownTypeAttribute, para especificar contrados de datos equivalentes en tipos derivados. Por lo tanto se deduce que tanto Authority como Container derivan de Entity. Pero para que quede claro y no haya dudas, vamos a generar un diagrama de clases a partir de este código el cual representará la relación existente entre autoridad, contenedor y entidad desde un punto de vista estático.

Ahora sí se puede apreciar que aunque una autoridad y un contenedor son contenedores lógicos de entidades, ellos son clases hijas del la clase Entidad que es la entidad flexible en sí, y que se diferencian por las parametrizaciones de sus propiedades de metadatos y propiedades flexibles. La siguiente tabla muestras las posibles combinaciones de propiedades de metadatos y propiedades flexibles para crear autoridades, contenedores y entidades:

SQL Server Data Services es un servicio que todavía está en pañales, hay planes para ofrecer crear entidades con esquemas e incluso poder hostear una instancia en las premisas del cliente. Independientemente de los planes y mejoras futuras me parece interesante considerar esta tendencia que iniciaron Amazon con SimpleDB y Google con AppEngine de publicar los datos en la gran nube que es Internet. En ciertos escenarios no lo considero factible, sobre todo si se trata de información financiera o de información crítica para que el negocio funcione diariamente, pero para ciertas aplicaciones como mashups, perfiles de usuario, etc. creo que tiene un muy buen potencial. Ahora lo que nadie dice es que por más que confiemos en nuestro provedor del servicio ya sea Microsoft, Amazon o Google y que nuestros datos estén en un cluster diseñado para proveer servicios de datos, se experimentan tiempos de baja en el servicio y es ahí donde no tenemos acceso a la infraestructura y nuestro negocio puede depender de ello. Por ello finalizo este post con una de las tantas notificaciones que se reciben de SSDS y un consejo final, si están dispuestos a aceptar este tipo de notificaciones de interrupción en su negocio u aplicación, pues adelante sino a montar su propoia infraestructura de datos.

En los próximos posts escribiré sobre las interfases SOAP y REST de SSDS así como de características únicas como consultas basadas en LINQ.
Hasta la próxima,
Fernik
 Continuando con la serie de posts acerca del testing de Windows Vista Service Pack 2, el cual también se puede extender a Windows 7 Beta 1(que parece que todo el mundo lo tiene instalado). En esta ocasión analizaré algo muy familiar para todos los usuarios: el Shell.
Continuando con la serie de posts acerca del testing de Windows Vista Service Pack 2, el cual también se puede extender a Windows 7 Beta 1(que parece que todo el mundo lo tiene instalado). En esta ocasión analizaré algo muy familiar para todos los usuarios: el Shell. 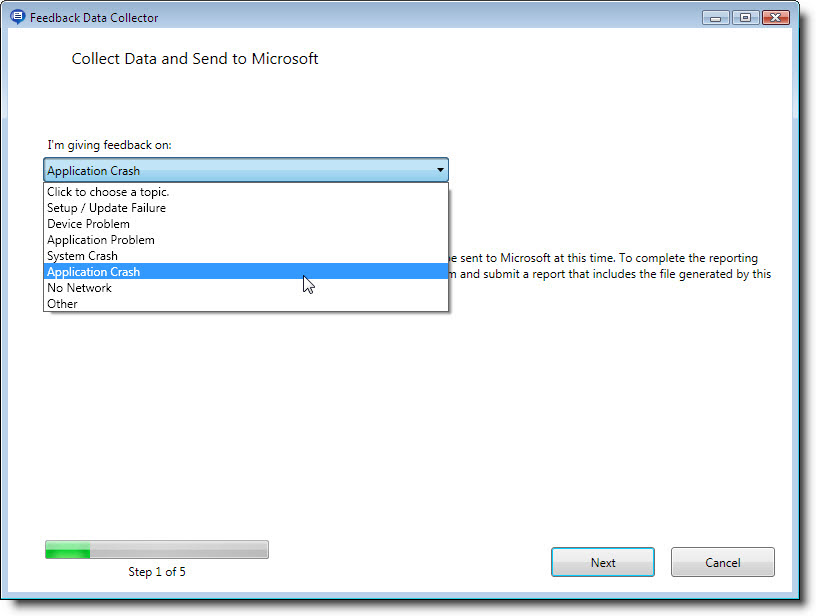
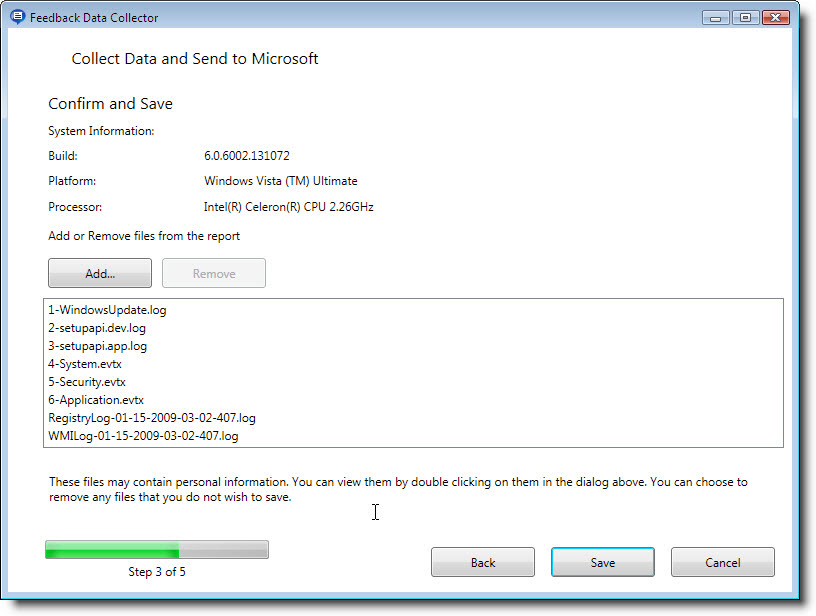
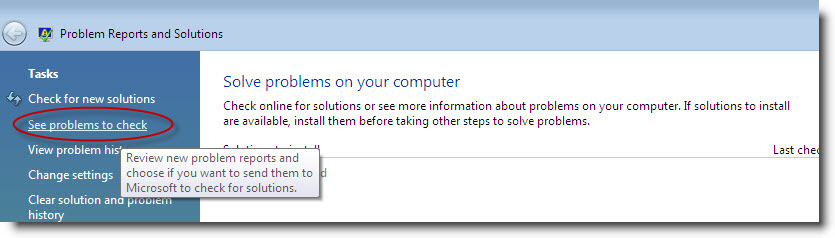
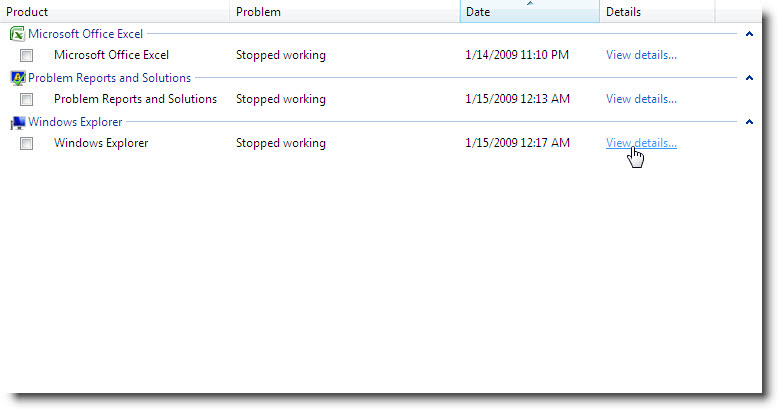
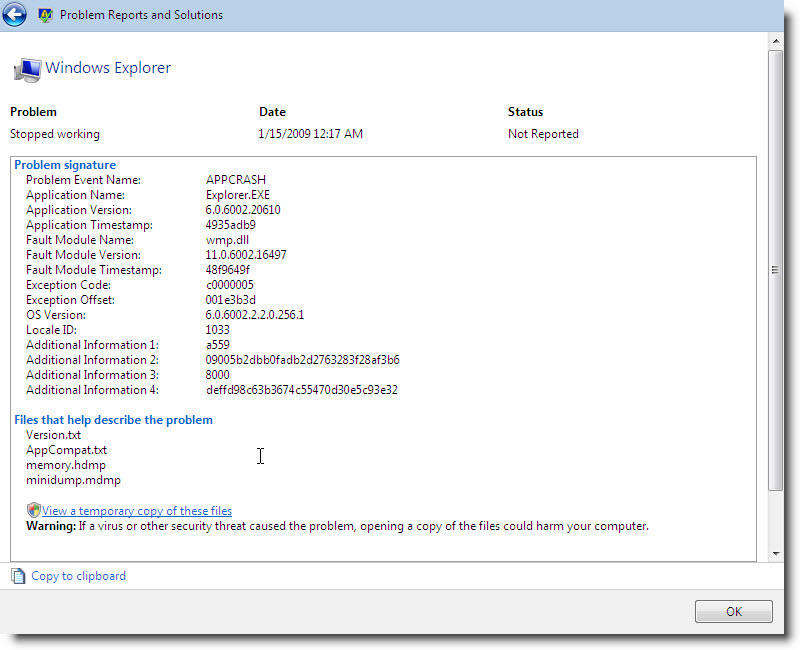
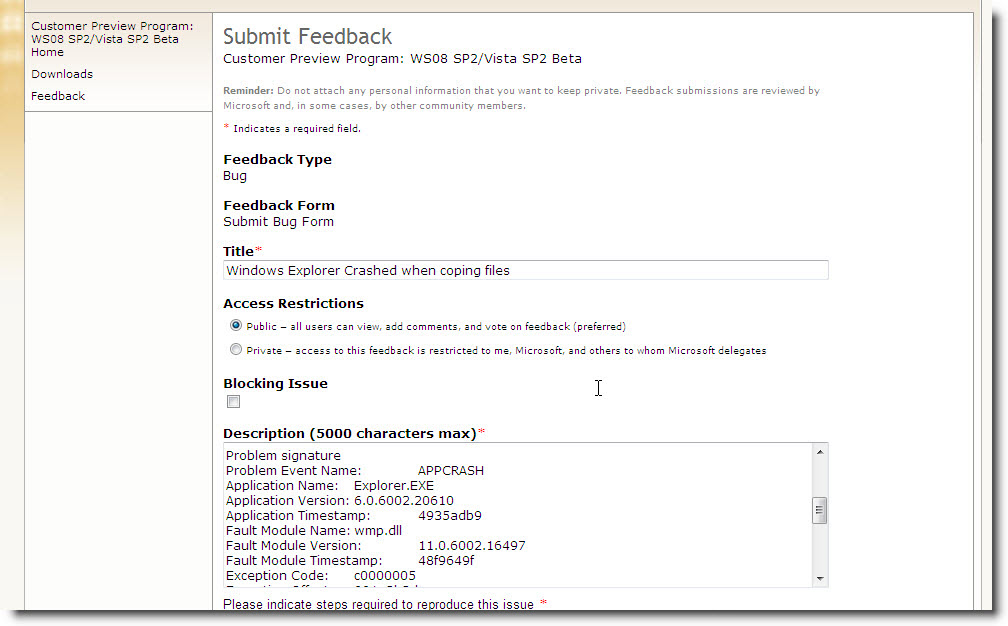
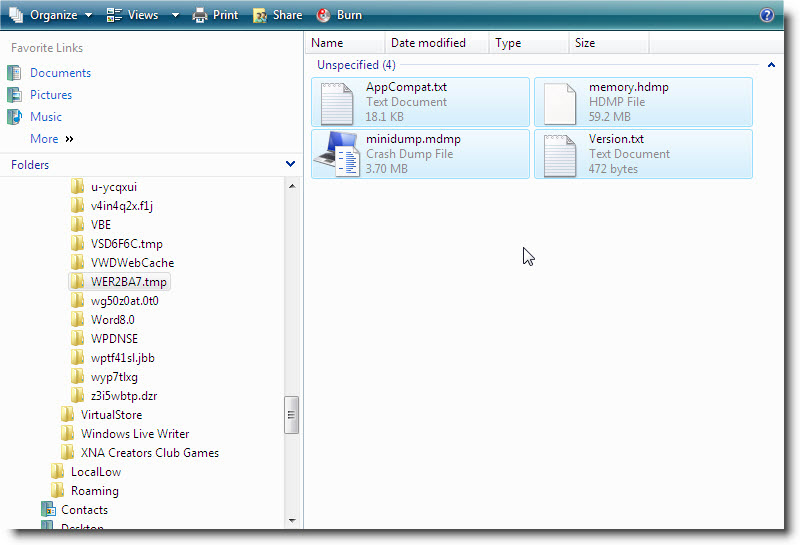

 Frecuentemente me encuentro con gente que lo único que sabe hacer es chillar y quejarse por que Windows Vista tiene problemas al no soportar un determinado hardware o no proveer los drivers necesarios. Pues bien esta es su oportunidad de ayudar a minimizar esta situación, ahora que puedo hablar ya que se ha abierto
Frecuentemente me encuentro con gente que lo único que sabe hacer es chillar y quejarse por que Windows Vista tiene problemas al no soportar un determinado hardware o no proveer los drivers necesarios. Pues bien esta es su oportunidad de ayudar a minimizar esta situación, ahora que puedo hablar ya que se ha abierto 












 Como parte del programa
Como parte del programa