
Resulta un hecho innegable que en los últimos tiempos, el volumen de datos que las organizaciones deben manejar ha aumentado desmesuradamente. Analizar tal cantidad de datos, con el objetivo de tomar decisiones estratégicas se ha convertido en un auténtico problema. En el presente artículo realizaremos una introducción a los cubos de datos en SQL Server 2008 Analysis Services, una potente herramienta con la que podemos transformar ingentes cantidades de datos en información de utilidad.
La masificación de datos en los sistemas de información de una compañía, sin la adecuada organización ni estructuración, puede acarrear efectos negativos tales como lentitud en el análisis de su estado, o lo que es peor, la toma de decisiones estratégicas inadecuadas, ya que el hecho de disponer de millones de registros repartidos en múltiples orígenes de datos heterogéneos (bases de datos SQL Server, Access, archivos de texto plano, Excel, etc.), no tiene porque ser en todos los casos sinónimo de un sistema que proporcione información de calidad.
Para solventar este tipo de problemas, en SQL Server contamos, desde hace ya algunas versiones, con los Servicios de Análisis (SQL Server Analysis Services o SSAS) o herramientas de Inteligencia de Negocio (Business Intelligence o BI), cuyo exponente principal, el cubo de datos, permite generar información para analizar el estado de la empresa a partir del conjunto de sus fuentes de datos.
Aspectos conceptuales
Desde una perspectiva conceptual, un cubo de datos es una pieza más en el engranaje de un sistema de información denominado almacén de datos (data warehouse). El cubo está dotado de una maquinaria interna que le permite procesar elevados volúmenes de datos en un periodo relativamente corto de tiempo, y cuyo objetivo es siempre la obtención de un resultado numérico (importes de ventas, gastos, cantidad de productos vendidos, etc.). Estos resultados pueden cambiar en función de uno o varios filtros que apliquemos sobre el cubo. El tiempo de respuesta es mínimo gracias a que el motor de procesamiento del cubo realiza un cálculo previo de las posibles combinaciones de resultados que el usuario puede solicitar. A los diferentes resultados numéricos obtenidos se les denomina medidas, mientras que los elementos utilizados para organizar/filtrar la información reciben el nombre de dimensiones.
Representado gráficamente, un cubo de datos se mostraría como la forma geométrica de la cual toma su nombre, particionado horizontal y verticalmente en una serie de divisiones que dan lugar a múltiples celdas o casillas, las cuales identifican cada uno de los posibles resultados de las medidas, obtenidos por la intersección en cada celda de las dimensiones que conforman el cubo. La siguiente figura muestra dicha representación gráfica de un cubo, con información de ventas por productos, empleados y monedas. En los lados del cubo se sitúan las dimensiones, cuyo cruce produce los resultados numéricos en las celdas.
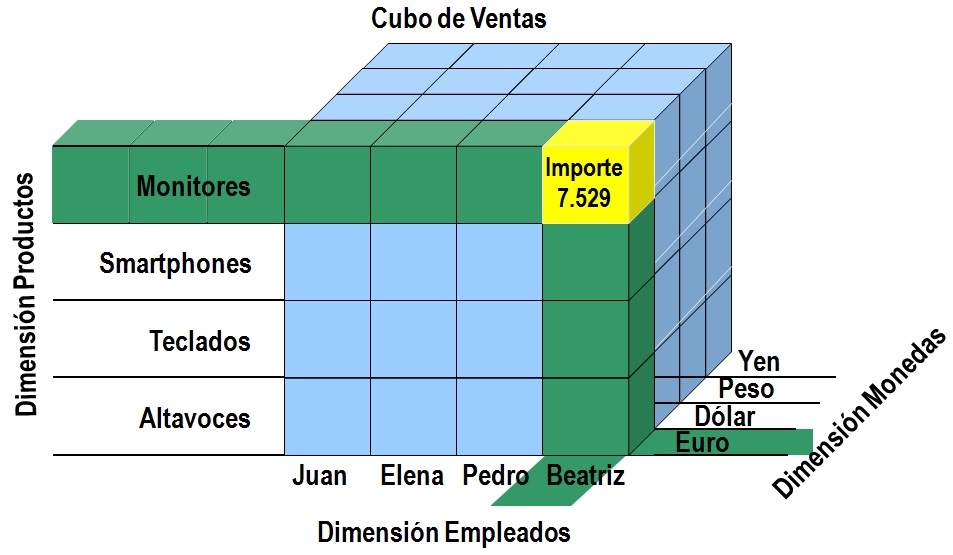
Observando la figura anterior, el lector puede pensar que el número de dimensiones en un cubo está limitado a las que podemos representar a través de dicha forma geométrica. Nada más lejos de la realidad, ya que un cubo puede soportar una elevada cantidad de dimensiones, que permiten cubrir sobradamente los requisitos de la información a obtener.
Elementos principales en un almacén de datos
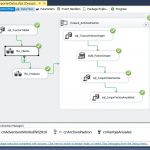
Como hemos mencionado anteriormente, un cubo de datos es una de las piezas de una arquitectura más compleja: el almacén de datos, en cuyo proceso de creación están involucrados diversos componentes, que serán los encargados de tomar el dato original en bruto y pulirlo hasta convertirlo en información lista para su análisis. A continuación vemos un diagrama con las fases de este proceso de transformación.

Descrito este proceso a grandes rasgos, en primer lugar se realiza una operación de extracción, transformación y carga (Extract, Transform & Load o ETL) desde las fuentes de datos origen, situadas en el área operacional, a una base de datos que se encuentra en el área de integración, utilizando para ello paquetes de los Servicios de Integración (SQL Server Integration Services o SSIS), los cuales realizarán también tareas de depuración de datos.
A continuación pasaríamos a la fase de construcción del cubo, que desarrollaremos utilizando las herramientas de los servicios de análisis (SSAS). Finalmente, llegaremos a la fase de acceso a los cubos por parte de los usuarios finales, para lo que existen diversos productos tales como Reporting Services (SSRS), Excel, etc.
Elementos físicos. Tablas de hechos y dimensiones
A nivel físico, para construir un cubo de datos necesitamos una base de datos que contenga una tabla denominada tabla de hechos, cuya estructura estará formada por una serie de campos, denominados campos de medida, a partir de los cuales obtendremos los resultados numéricos del cubo; y por otro lado, un conjunto de campos, denominados campos de dimensión, que utilizaremos para unir con las tablas de dimensiones, a fin de poder obtener resultados filtrados por las diversas dimensiones de que conste el cubo.
El otro pilar fundamental para la creación de un cubo lo componen las tablas de dimensiones. Para cada dimensión o categoría de consulta/filtro que incorporemos a nuestro cubo necesitaremos una tabla, que uniremos con la tabla de hechos por un campo clave. Esta tabla de dimensiones actuará como catálogo de valores, también denominados atributos, que usaremos de forma independiente o combinados con otras dimensiones, para obtener resultados con un mayor grado de precisión.
Desarrollando un cubo de datos
Una vez explicadas las nociones básicas necesarias, entramos en la parte práctica del artículo, donde desarrollaremos nuestro propio cubo de datos. Centraremos todos nuestros esfuerzos exclusivamente en la creación del cubo, sin abordar aquí las operaciones de extracción, transformación y carga, que serían realizadas mediante paquetes SSIS, ya que estos últimos son aspectos que quedan fuera del ámbito de este artículo, quedando pendientes para una futura entrega.
En primer lugar, desde el menú de Windows iniciaremos SQL Server Business Intelligence Development Studio, cuyo acceso directo se encuentra en el grupo de programas Microsoft SQL Server 2008 R2. Se trata de una versión especial de Visual Studio preparada para desarrollar proyectos de BI, en cuyo diálogo inicial seleccionaremos como tipo de proyecto Analysis Services Project, al que daremos el nombre CuboDatosAdvWorks.
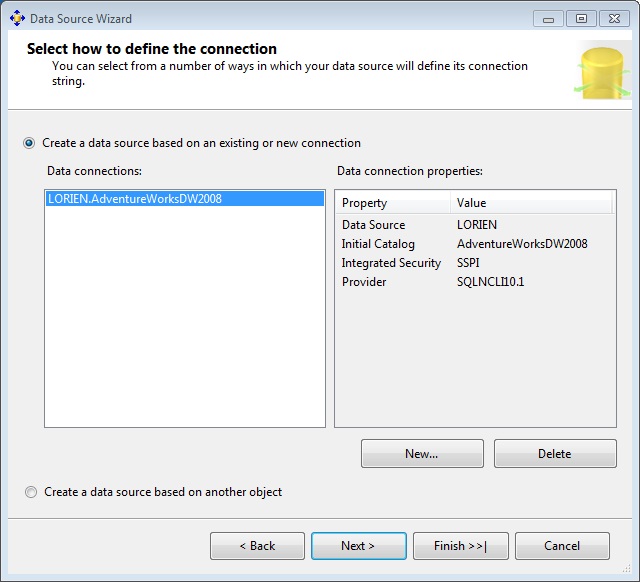
A continuación, haciendo clic derecho en el nodo Data Sources del Explorador de Soluciones, seleccionaremos la opción New Data Source, que abrirá el asistente para crear la fuente de datos del cubo, y que en nuestro caso será la base de datos de prueba AdventureWorksDW2008, cuya estructura ya se encuentra preparada para ser utilizada en el diseño de cubos de datos.
Dejaremos las opciones por defecto en el asistente hasta llegar al paso correspondiente a la conexión contra la fuente de datos, donde seleccionaremos AdventureWorksDW2008. Al llegar al paso final de este asistente veremos un resumen de la fuente de datos que hemos creado.
Nuestro siguiente paso consistirá en crear una vista de la fuente de datos, que nos permitirá, como su nombre indica, definir una visualización personalizada sobre la base de datos, incluyendo aquellas tablas que necesitemos para crear el cubo.
Lo que en este cubo de ejemplo vamos a medir es el importe de las ventas que los distribuidores de la compañía AdventureWorks han facturado, pudiendo consultar/filtrar los resultados por el tipo de moneda en que se ha realizado la venta, y el área geográfica a la que se ha enviado el pedido. Para ello utilizaremos la tabla FactResellerSales como tabla de hechos, siendo DimCurrency y DimSalesTerritory las tablas de dimensión.
Haciendo clic derecho en el nodo Data Source Views del Explorador de Soluciones seleccionaremos la opción New Data Source View, que abrirá un asistente en cuyo primer paso elegiremos la fuente de datos recién creada, y en el segundo las tablas que acabamos de mencionar.
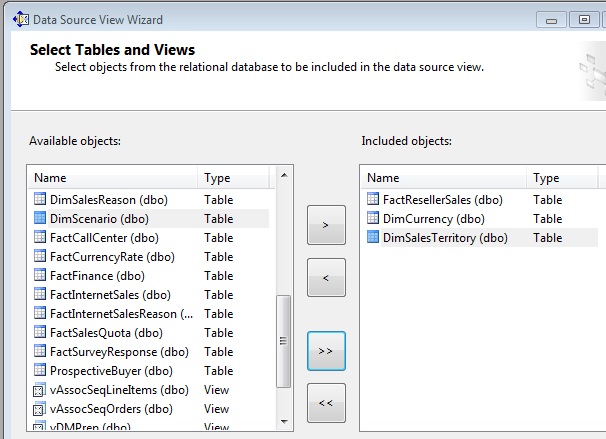
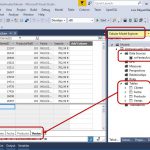
Finalizado este asistente aparecerá su ventana de diseño, en la que vemos un diagrama de las tablas seleccionadas, con las relaciones existentes entre las mismas.

Creación de dimensiones. Dimensión básica
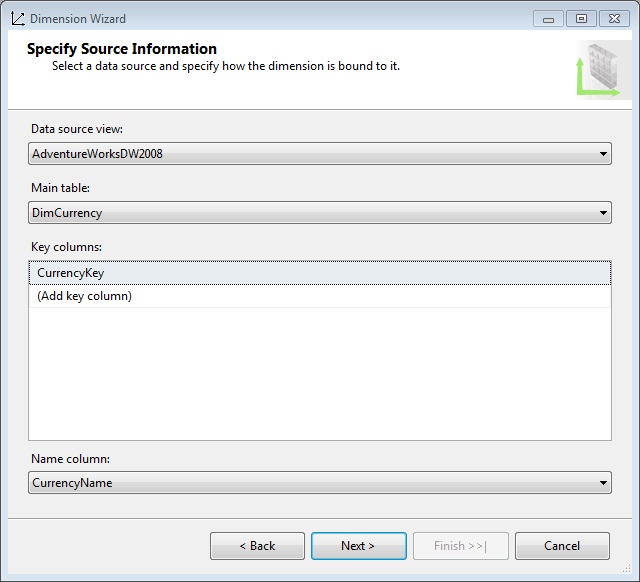
El siguiente paso consistirá en crear la dimensión que nos permitirá consultar/filtrar la información del cubo por el tipo de moneda con el que se realizó el pago del pedido. Haciendo clic derecho en el nodo Dimensions del Explorador de Soluciones seleccionaremos la opción New Dimension, iniciándose el consabido asistente, cuyo primer paso, Select Creation Method, dejaremos con la opción predeterminada Use an existing table. Al entrar en el paso Specify Source Information, tres listas desplegables nos permitirán configurar la información a obtener para la dimensión: con Main table elegiremos la tabla que utilizaremos en la dimensión: DimCurrency; con Key columns indicaremos la clave primaria; y finalmente, con Name column seleccionaremos el campo CurrencyName, que identificará el atributo a visualizar.
En el paso Select Dimension Attributes, el asistente nos ofrecerá Currency Key como atributo de la dimensión, el cual utilizaremos, pero cambiando su nombre a Currency. Un atributo es un campo, normal o calculado, perteneciente a la tabla de dimensión, que se mostrará como una etiqueta en cualquier lugar en el que la dimensión participe como parte de una consulta contra el cubo de datos.
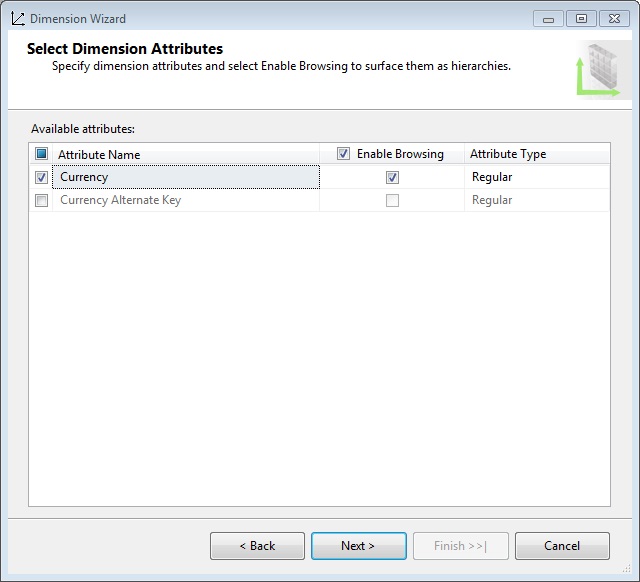
Al llegar al último paso daremos el nombre Currency a la dimensión y finalizaremos el asistente, mostrándose el diseñador de dimensiones con la estructura que acabamos de crear. Observando las propiedades del atributo Currency, las más importantes son Name, que contiene el nombre que aparecerá en las consultas contra el cubo; KeyColumns, que contiene el campo clave de la tabla que se relacionará con la tabla de hechos; y NameColumn, que contiene el campo de la tabla que mostrará el valor del atributo.

En el caso de que necesitemos añadir más atributos a la dimensión, simplemente tendremos que arrastrar y soltar los campos desde la tabla del panel Data Source View hasta el panel Attributes de este diseñador.
Una vez creados todos los atributos procesaremos la dimensión haciendo clic en el botón Process de la barra de herramientas del diseñador, o mediante el menú de Visual Studio Build | Process. Completado el proceso de la dimensión, haremos clic en la pestaña Browser del diseñador, donde podremos examinar cómo ha quedado construida.
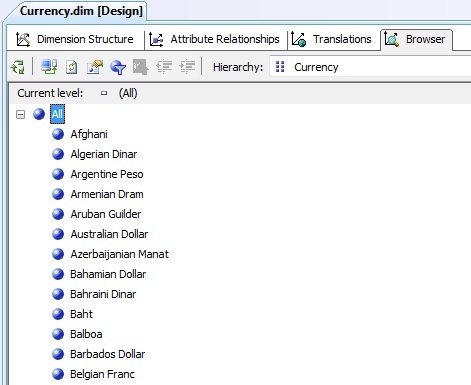
Creación de dimensiones. Dimensión jerárquica
Además de las dimensiones de un único nivel, como la que acabamos de ver en el apartado anterior, es posible crear dimensiones que agrupen los datos en varios niveles, lo que proporcionará una mayor capacidad de desagregación sobre la información del cubo cuando éste sea consultado a través de una dimensión de este tipo. A este elemento de una dimensión se le denomina jerarquía.
Pongamos como ejemplo la tabla DimSalesTerritory, incluida en el Data Source View de nuestro proyecto de ejemplo. En la misma podemos ver que la combinación de los campos SalesTerritoryGroup, SalesTerritoryCountry y SalesTerritoryRegion permite establecer varios niveles de agrupamiento para los datos.
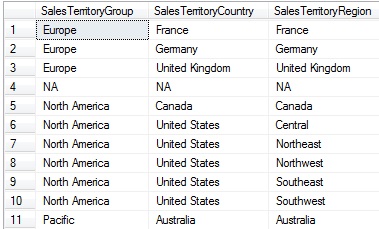
Supongamos que necesitamos crear una dimensión basada en esta tabla que permita, partiendo del campo SalesTerritoryGroup, un efecto similar de «despliege» jerárquico por niveles.
Para ello, crearemos en primer lugar la dimensión utilizando el asistente en la forma explicada en el anterior apartado. El atributo seleccionado por defecto por el asistente será el correspondiente al campo SalesTerritoryKey, clave primaria de la tabla.
Una vez situados en el diseñador de dimensiones, arrastraremos desde la tabla del panel Data Source View los campos SalesTerritoryGroup, SalesTerritoryCountry y SalesTerritoryRegion, y los soltaremos en el panel Attributes de este mismo diseñador.
A continuación arrastraremos el atributo Sales Territory Group hasta el panel Hierarchies, lo cual creará una nueva jerarquía a la que cambiaremos el nombre predeterminado por Sales Territory. También depositaremos en esta jerarquía los atributos Sales Territory Country y Sales Territory Region, observando que junto al nombre de la jerarquía aparece un icono de advertencia que nos informa de que las relaciones entre los atributos de la jerarquía no están adecuadamente creadas, lo que puede afectar negativamente al proceso de la dimensión.
Para solucionar este inconveniente haremos clic en la pestaña Attribute Relationships, donde veremos las relaciones entre los atributos que automáticamente ha creado el diseñador.

Estas relaciones, sin embargo, no son válidas para nuestros propósitos, por lo que seleccionaremos las flechas del diagrama que las representan y las eliminaremos. Para crear las nuevas relaciones arrastraremos desde el atributo origen hasta el destino, hasta dejarlas tal y como apreciamos en la siguiente figura.

Antes de procesar la dimensión volveremos a la pestaña Dimension Structure para comprobar que la advertencia ha desaparecido. Por otro lado seleccionaremos todos los atributos del panel Attributes, asignando el valor False en su propiedad AttributeHierarchyVisible, con lo que conseguiremos que los atributos independientes no se muestren, ya que lo que nos interesa en este caso es explorar solamente la jerarquía. A continuación vemos el resultado de esta dimensión, con todos los elementos de la jerarquía expandidos.
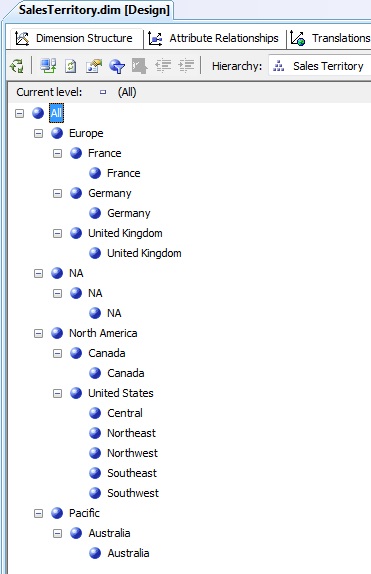
Creación del cubo
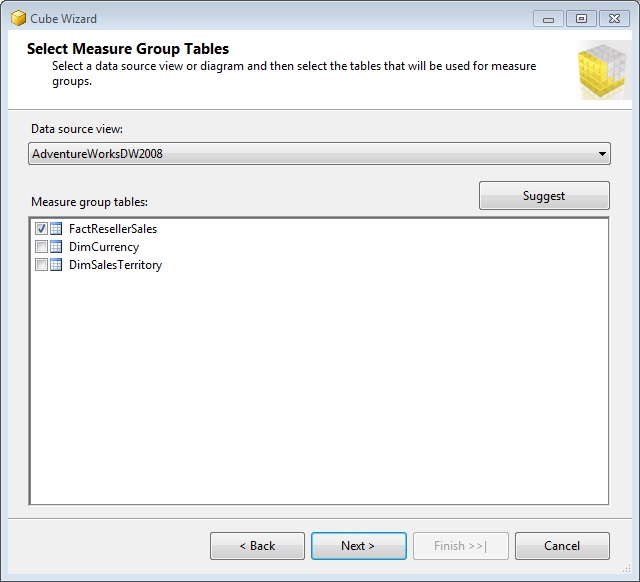
Llegamos a la fase final en el desarrollo de nuestro proyecto de ejemplo: la construcción del cubo de datos. Empezaremos haciendo clic derecho en el nodo Cubes del Explorador de Soluciones, y seleccionando la opción Add Cube, lo que abrirá el asistente de creación, en el que dejaremos sus valores predeterminados hasta llegar al paso Select Measure Group Tables, que como su nombre indica, nos pide seleccionar la tabla que contendrá los campos que usaremos como medidas para el cubo, es decir, la tabla de hechos, que en este caso será FactResellerSales.
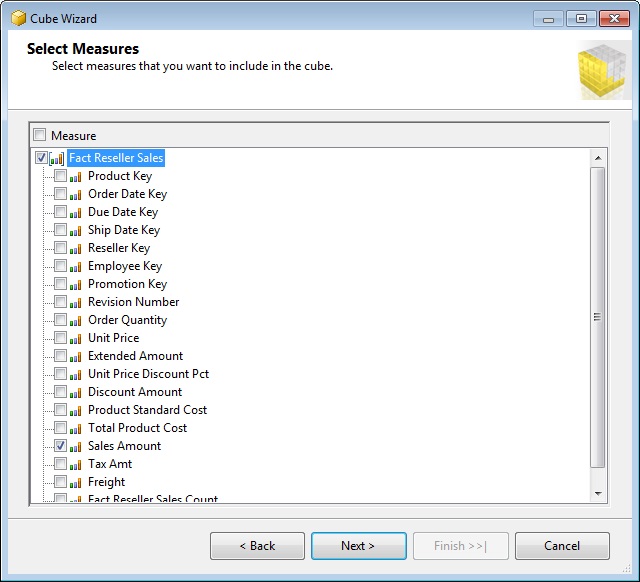
Haciendo clic en Next entraremos en el paso Select Measures, donde tendremos que seleccionar los campos que actuarán como medidas del cubo. El objetivo de este cubo consiste en averiguar el importe de las ventas realizadas por los distribuidores, por lo tanto, seleccionaremos solamente el campo SalesAmount.
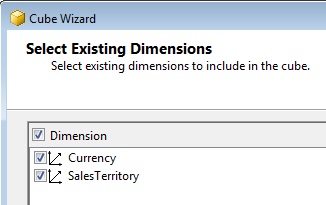
El siguiente paso nos solicita la selección de las dimensiones que van a formar parte del cubo. Automáticamente se han detectado las dimensiones creadas por nosotros con anterioridad, las cuales ya se ofrecen seleccionadas por defecto.
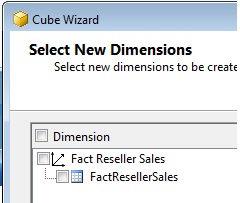
A continuación, el asistente realiza una búsqueda en la tabla de hechos, por si algún campo pudiera ser susceptible de ser también tratado como una dimensión. Dado que no necesitamos esta característica, desmarcaremos la selección de la tabla de hechos como fuente de origen para la creación de dimensiones.
Y llegamos al paso final, donde daremos al cubo el nombre de VentasDistribuidores, finalizando así el asistente.
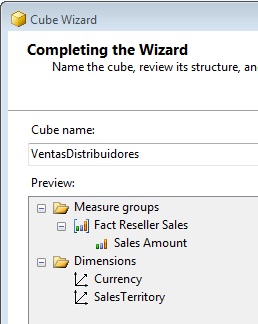
Como resultado obtendremos la pantalla correspondiente al diseñador de cubos, que muestra diversos elementos de importancia, tales como el panel de dimensiones, diagrama de tablas, medidas (Measures), etc.

Es precisamente en el panel de medidas donde aparece la medida que hemos seleccionado en el asistente, pero a la cual cambiaremos su nombre por Importe Ventas desde la ventana de propiedades. En esta misma ventana podemos observar el nombre, la función de agregado que se usa para calcular la medida, el campo de la tabla utilizado, cadena de formato, etc.
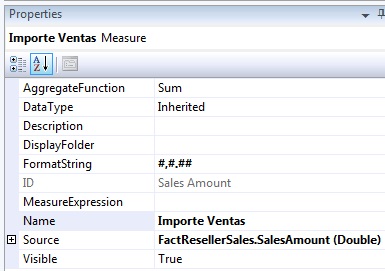
Para que la medida aparezca correctamente formateada, además de asignar la cadena de formato a su propiedad FormatString, en las propiedades del cubo tenemos que asignar el valor Spanish (Spain) a la propiedad Language.
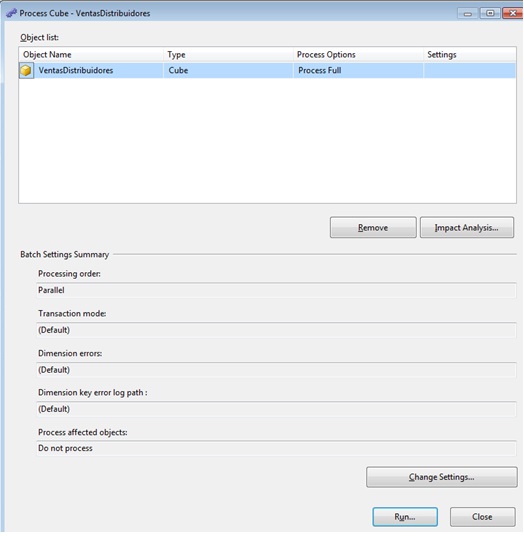
Finalmente, antes de poder consultar el cubo, al igual que hicimos con las dimensiones, debemos procesarlo haciendo clic en el botón Process, que abrirá el cuadro de diálogo de procesamiento del cubo, en el que haremos clic en su botón Run.
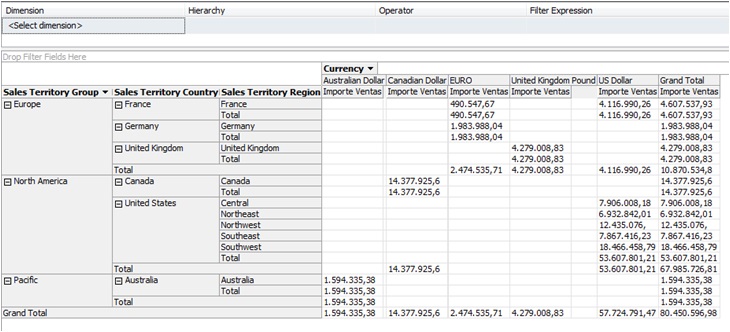
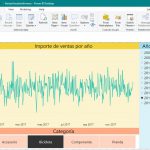
Una vez que el cubo ha sido procesado, podemos consultar su contenido haciendo clic en la pestaña Browser. En el panel Measure Group expandiremos el nodo Measures hasta llegar a la medida Importe Ventas, que arrastraremos hasta la zona central del visualizador. A continuación arrastraremos la dimensión SalesTerritory hasta el margen izquierdo del visualizador. Podemos hacer clic derecho sobre esta dimensión, seleccionando la opción Expand Items, lo que producirá un despliegue de los elementos de la dimensión. Para terminar arrastraremos la dimensión Currency hasta el margen superior. Como resultado obtendremos una cuadrícula de datos en la que cada celda mostrará el valor de la medida para la intersección de las dimensiones situadas en las columnas y filas del visualizador de datos.
Conclusiones
En el presente artículo hemos realizado una introducción al desarrollo de cubos de datos con SQL Server 2008 Analysis Services, un componente de la familia SQL Server destinado a proporcionar soluciones de inteligencia de negocio con las que explotar el potencial de análisis que reside en los datos de las organizaciones. Las posibilidades y potencia de esta herramienta son enormes, y confiamos en que este artículo anime al lector a llevarlas a la práctica.


anonymous
La obtención de detalles (drillthrough) es una característica de los cubos de datos multidimensionales
anonymous
(Artículo publicado previamente en dNM+ número 83) PowerPivot (proyecto también
anonymous
(Artículo publicado previamente en el número 93 de dNM+, junio 2012) La reciente aparición