

AENOR is an entity dedicated to the development of standardization and certification in all Spanish industrial and service sectors and is responsible for the development and dissemination of UNE standards. At present, AENOR certifies more than 50,000 UNE standards, in addition to those published by all standardization bodies.
In order to provide every user access to the most appropriate standards, AENOR was interested in adopting processes based on Artificial Intelligence, thus providing a useful tool for all those not accustomed to the specialized language of the standardization industry.
Given the high number of standards managed by the recognized certifier, which covers all industrial sectors, so that each one has the corresponding terminology, concepts and expressions, it was necessary to start the project focusing on the development of a pilot ready for a final version.
As such, it was decided to start with the implementation of a single use case focused on the health sector, which would allow the new technology to be used, analyse its behaviour and improve it, and with everything combined, be able to value the cost vs. benefits that the complete development of the project would entail.
Specifically, the use case chosen to kick the project off focused on developing an intelligent search engine for the 1,500 documents corresponding to the health sector.
An effective search based on AI techniques
Information retrieval processes traditionally consist of exploiting information system resources relevant to a specific need. And searches are open based on indexing text or other content. But the results do not always give what you want especially when the collection of documents is very broad. Therefore, it is necessary to take another step…
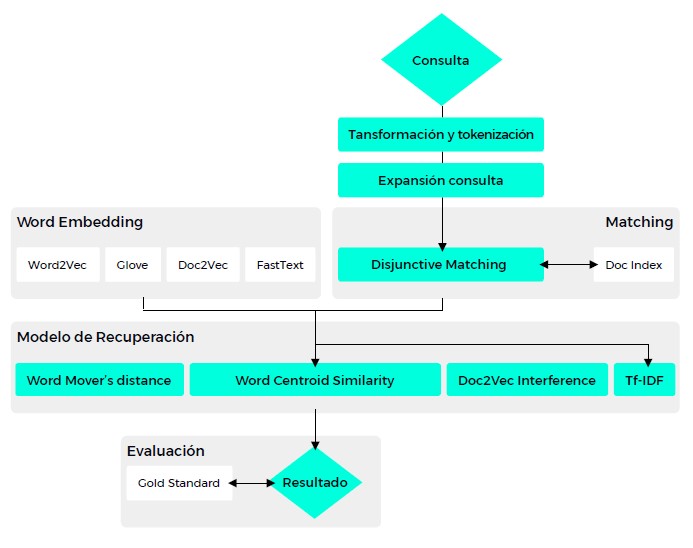
The main feature of this search engine consists of using Artificial Intelligence (AI) and Machine Learning techniques in order to expand the vocabulary with the help of Wikipedia articles in order to offer users the possibility of performing both searches by cross-matching terms and semantic searches.
Firstly, the query is transformed and tokenized in such a way that once introduced, words what are known as stop words are eliminated. Eg, articles, pronouns or prepositions.
When the collection of documents is quite large, as was the case with this project, a process called Disjunctive Matching is usually carried out, which consists of preselecting a set of data on which the final search will be carried out. In order to carry out this process, we simply select those documents in which one of the words that have been entered in the query appears, aRer carrying out the aforementioned transformation.
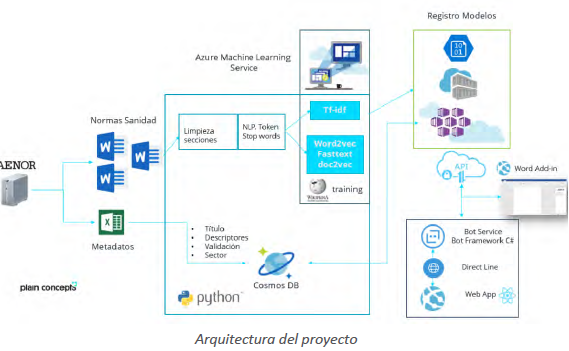
Subsequently, the semantic search comes into play integrating different business services in MicrosoR’s cloud, which include Azure Machine Learning, Azure Service Fabric and Cosmos DB. In the development of the project, different word embedding models were used to facilitate a semantic recovery.
The methods used to establish the ranking of documents are firstly based on the frequency of the use of terms in each document, comparing it with its absence in the rest of the documents in the collection (a technique known as TF-Idf). And secondly, through a learning process achieved by expanding the semantic relationships between words, while measuring the weight of articles in the Spanish Wikipedia (Word2Vec).
An automated procedure is added to this to value or weigh up the search results, in order to prioritize and show the user those that contain the searched term in the title or in the description of the document.
A simple and integrated user interface
To act as a helpful interface in the search process, a Virtual Assistant or Bot was developed that guides the user in their search for documents, showing them a list of related norms based on their needs.
Additionally, a Microso4 Office add-in was implemented which allows users to find the rules related to the context of the document that is being written from Microsoft Word in real time. This provides all the necessary help to create content while writing without changing the work environment.
Results that encourage expansion
Twenty AENOR expert health auditors and business regulators participated in the pilot to develop the proof of concept in just three months.
The results have been extremely satisfactory and the scope of the project will be extended in 2019 enabling the service to support a greater volume of internal users and customers.
Among others, possible agreements with universities and other educational institutions are envisioned so that teachers and students can also use it, so that more feedback can be received in order to enhance the tool.
Benefits of AI and possible applications
By 2020, companies are expected to spend a total of 47 billion dollars in Artificial Intelligence (AI). As such, various aspects of our everyday lives will change forever as programs begin to use all the information that is generated, providing users with fully customized services.
Thanks to AI solutions, we have been able to help companies improve their decision-making processes and increase their efficiency by applying Machine Learning techniques, Visual Computing, text analysis and emotion analysis.
Any company that handles large amounts of information can benefit from Artificial Intelligence to offer their customers the best user experience, show products adapted to their needs, offer the most relevant information, as well as suggest ideas for improvements that help them to carry out their work more efficiently.
With recruitment companies that constantly look for talent among countless profiles, legal firms which need to analyse millions of documents, shopping centres and hotels which receive thousands of visits per month and want to offer the best user experience to their clients or doctors who need to analyse patient tests daily among many other sectors, artificial intelligence has many applications which are still yet to be discovered. The possibilities are endless.
Deja un comentario