


Infojobs Brazil was interested in adopting processes based on Artificial Intelligence (AI) in order to classify applicants of job offers in two groups: suitable and not suitable candidates for the job. This will ease the work done by Human Resources teams as a first preselection of candidates will be done automatically using AI.
Project features

Data classification
The algorithm selected to do this project was a multilayer neural network, which makes possible the re-training. Other AI techniques used were TF-IDF, One Hot Encoder and Feature Hashing, that will be mentioned in the next sections.
The variables used to do this classification were of different nature, having special interest variables as the abstract, experience and studies of the candidates due to its relationship with the topic of the problem.
We have also developed a UI interface to improve the user experience when re-training the model.wsa
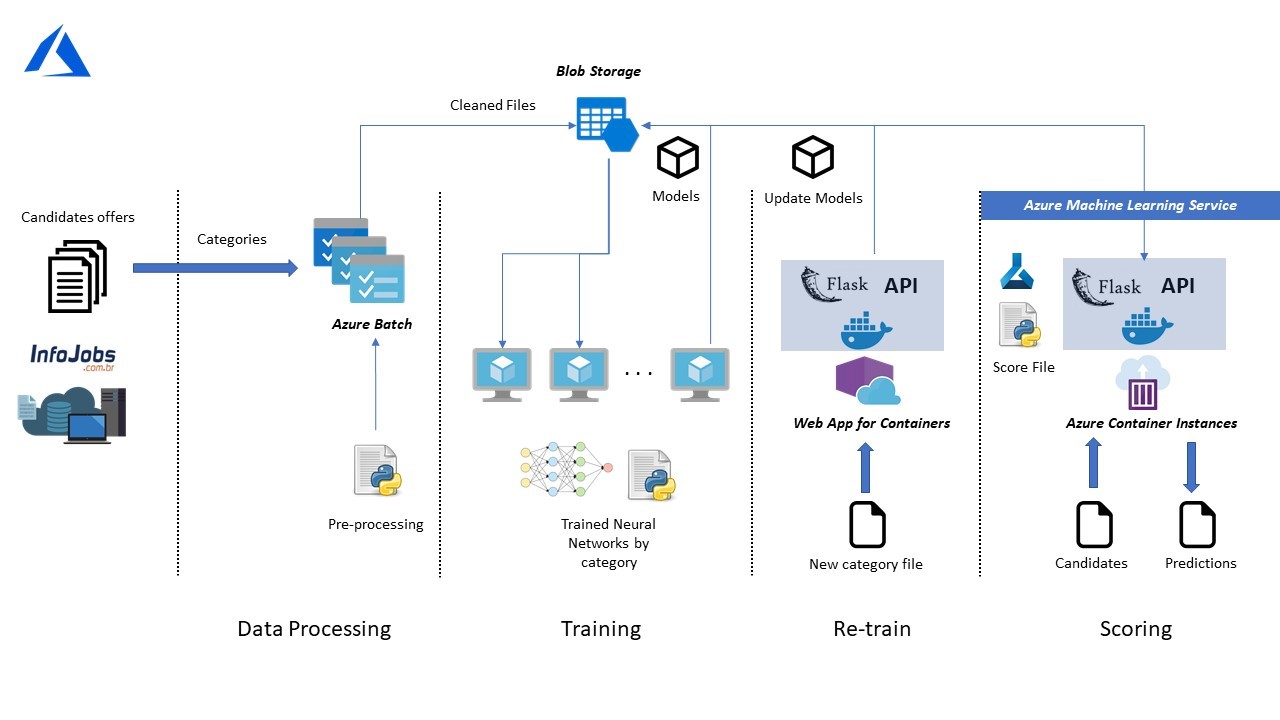
Project phases and used technologies
In AI, a classification problem consists of identify to which category a new observation belongs, based on a training set of data which contains observations whose category membership is already known.
To achieve so, a dataset of 180Gb was used. In this dataset, there was data corresponding to different categories, such as: logistic, administration, arts, fashion, and so on. To deal with this, we have created as many models as different categories are. This makes sense as it makes the models more specific, which led to a better performance for candidates’ classification.
Another aspect to consider in this dataset is the existence of different type of variables: numerical, such as the age; categorical, such as the languages spoken; and text such as the studies, experience and abstract of each of the candidates. These last types of variables are very relevant because in the context where we are trying to do the classification, job offers, variables as the mentioned above, are determinant to achieve a good result, as they held most of the information need.
AI algorithms only work with numbers, therefore, we had to cleaned and transformed our dataset. In order to do that, categorical variables needed to be converted to numerical, to do so both One Hot Encoder and Feature Hashing techniques were used. Text variables were also transformed to numerical using TF-IDF technique, which works as follows: given a collection of documents, TF-IDF technique is based in the frequency of terms in each of the documents, being its aim to reflect how important a term is to a document in the collection.
To do this preprocessing of the data and given the dimensionality of our dataset we used Azure Batch in order to make this cleaning process scalable and save time.
To fulfill the aim of the project, different algorithms were analyzed. Finally, a multilayer neural network was selected, as it was obtaining the best results between the ones allowing re-training. As stated before, not only one neural network was trained, but as many as different categories were in our dataset, a total of 34. These neural networks were trained with the data cleaned in the previous step. Each of them was stored in Azure Blob Storage, making them accessible when doing both re-training and prediction.
When someone applies to a job offer and feedback of the company he or she is applying to is received, the data related to this candidate will be collected and can be useful to improve predictions as newer information is added. Therefore, re-training is necessary.
Re-training is done using our UI interface, which will be integrated in Infojobs platform. This process starts when the user enters new candidates in the system, which will be data with information about different applicants and different job offers. Once the data is uploaded and cleaned, the models corresponding to the categories seen in the new dataset provided, will be downloaded and their weights will be updated, the updated model overwrites the last version of the model present in the storage.
The last phase of the project is prediction. When someone applies to a job offer, the data related to this candidate can be passed to its corresponding neural network, which will process it and depending on it, the algorithm will make a prediction classifying the candidate in one of the two classes described earlier: suitable and not suitable candidate for the job.
To accomplish this last task, we have used Azure Machine Learning Service Workspace to create the docker images and to deploy it with Azure Container Instances.


 AI Benefits and its possible applications
AI Benefits and its possible applications
By 2020, it is expected that companies will spend a total of 47,000 million dollars in AI, this will change our lives forever as the programs begin to use all the information that is generated, providing users with fully customized services.
Thanks to AI solutions, we managed to help companies improve their decision-making processes and make processes more efficient by applying Machine Learning techniques, Visual Computing, text analysis and feeling analysis among others.
Any company that handles a large volume of information can benefit from Artificial Intelligence to offer its customers the best user experience, showing the user products adapted to their needs, offering the most relevant information always, as well as suggesting ideas for improvements that help them to carry out their work more efficiently.
For instance, recruitment companies that constantly seek talent among countless profiles, lawyers’ buffets that need to analyze millions of documents, shopping centers and hotels that receive thousands of visits per month and want to offer the best user experience to their clients. Artificial intelligence has many applications that are yet to be discovered.
Deja un comentario