
Como continuación al conjunto de artículos dedicados a la aplicación práctica de las tablas numéricas auxiliares, en la actual entrega, al igual que en el anterior artículo, centraremos nuestro objetivo en el tratamiento de los caracteres que actúan como delimitador dentro de un texto, pero en este caso el objetivo consistirá en eliminar los delimitadores sobrantes del mismo, para lo cual, en primer lugar expondremos el escenario de trabajo sobre el que actuaremos.
El escenario de trabajo
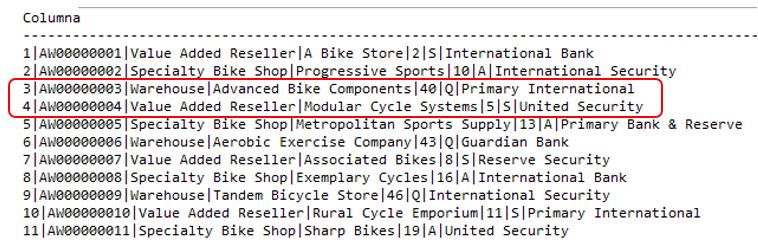
Supongamos que debemos cargar una tabla de una base de datos con el contenido proveniente de un archivo de texto, en el que las columnas vienen determinadas por un carácter delimitador, por ejemplo, el carácter de barra vertical o pipe. La siguiente figura muestra algunas líneas de este archivo, que incluye los nombres de las columnas en su primera fila.
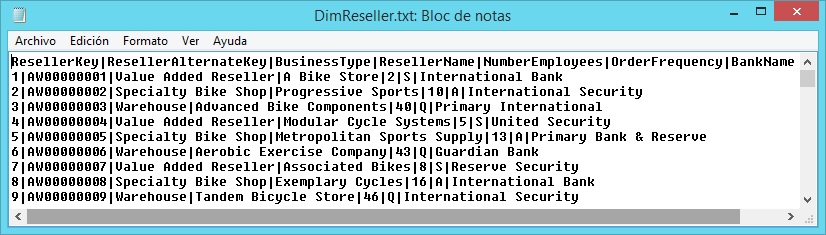
Observando con detalle este archivo comprobaremos que cada fila dispone de seis caracteres delimitadores, que a su vez definen siete campos o columnas, como vemos gráficamente en la siguiente imagen.

Preparación del archivo de datos origen
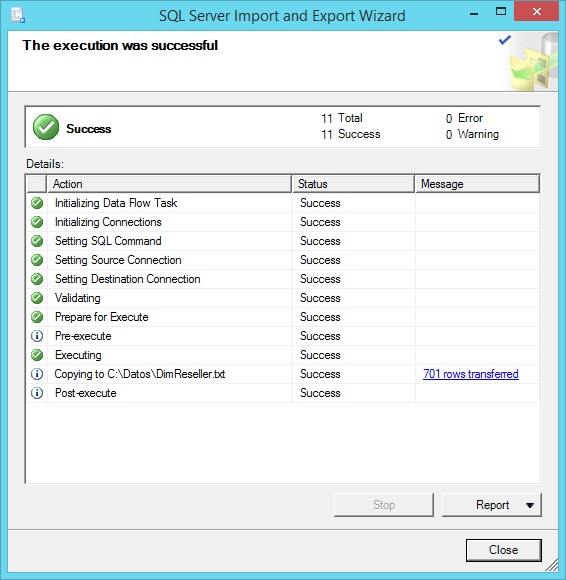
Los datos de este archivo se han obtenido a partir de varias columnas de la tabla DimReseller, perteneciente a la base de datos AdventureWorksDW2012. Para preparar este archivo, desde SQL Server Management Studio haremos clic derecho en dicha base de datos, eligiendo la opción Tasks | Export Data, lo que abrirá el asistente de exportación de datos de SQL Server 2014.

Después de hacer clic en el botón Next para pasar la página de presentación del asistente, en el primer paso del mismo seleccionaremos la fuente de datos desde la que vamos a realizar la exportación.

A continuación seleccionaremos Flat File Destination como tipo de destino de la exportación, así como el nombre del archivo en el que se realizará el volcado de los datos. También habilitaremos la inclusión de los nombres de las columnas de la tabla en la primera fila del archivo.
En el siguiente paso indicaremos que la exportación se realizará mediante una consulta contra la base de datos.
Incluyendo dicha consulta a continuación.
En el próximo paso seleccionaremos el carácter pipe como delimitador de columna.
A partir de este punto avanzaremos hasta el último paso del asistente y haremos clic en el botón Finish para generar el archivo de texto con el resultado de la sentencia.
La carga del archivo en la base de datos
Una vez obtenido el archivo, en la base de datos que estemos utilizando para realizar nuestras pruebas crearemos una tabla con la siguiente estructura.
CREATE TABLE Reseller ( ResellerKey int NOT NULL, ResellerAlternateKey varchar(15) NULL, BusinessType varchar(20) NOT NULL, ResellerName varchar(50) NOT NULL, NumberEmployees int NULL, OrderFrequency char(1) NULL, BankName varchar(50) NULL )
Mientras que para traspasar el contenido del archivo de texto (situado en una supuesta ruta C:\Datos) a esta tabla utilizaremos la instrucción BULK INSERT.
BULK INSERT Reseller FROM 'C:\Datos\DimReseller.txt' WITH (FIELDTERMINATOR = '|', CODEPAGE = 'ACP', FIRSTROW = 2)
¿Y si el archivo de datos no está correctamente normalizado?
En condiciones normales el anterior bloque de código se ejecutaría sin problemas, cargando el contenido del archivo en la tabla. Pero supongamos que los datos que se exportan al archivo se recogen a partir de un formulario en el que el campo correspondiente a la columna ResellerName (columna número cuatro) de la tabla es de texto libre, pudiendo el usuario introducir cualquier carácter, y existiendo, por tal motivo, algunos registros en los que en el contenido de dicho campo podemos encontrarnos con los mismos caracteres pipe que utilizamos como delimitador de columna al exportar los datos al archivo.

Esto es algo que desvirtúa completamente nuestra operación de importación de datos desde el archivo, ya que provoca errores como los siguientes.

Ante una situación como esta resulta necesario desarrollar un proceso que elimine, de los valores que han de traspasarse a la columna ResellerName, los caracteres pipe que están provocando el conflicto en la operación de importación. Por lo que en primer lugar, vamos a tomar el contenido de una de las filas del archivo que producen el error (la fila 3, por ejemplo) y trabajar sobre dicho texto hasta obtener el código que realice la depuración de los caracteres sobrantes. A continuación se muestra la fila seleccionada.
3|AW00000003|Warehouse|Advan|ced Bi|ke Comp|one|nts|40|Q|Primary International
Tabla numérica auxiliar al rescate
Para comenzar, necesitamos averiguar, dentro de la cadena, las posiciones de inicio y fin del campo a depurar, por lo que aquí es donde recurriremos al uso de una tabla numérica auxiliar con base uno (primera fila con valor 1), y compuesta por 100 filas. Como primera aproximación al problema calcularemos las posiciones de todos los delimitadores de la manera que vemos en el siguiente bloque de código.
DECLARE @sTexto AS varchar(100); DECLARE @sDelimitador AS varchar(1); SET @sTexto = '3|AW00000003|Warehouse|Advan|ced Bi|ke Comp|one|nts|40|Q|Primary International'; SET @sDelimitador = '|'; SELECT ROW_NUMBER() OVER(ORDER BY NumeroID) AS NumeroDelimitador, NumeroID AS PosicionDelimitador FROM Numeros WHERE SUBSTRING(@sTexto,NumeroID,1) = @sDelimitador ORDER BY NumeroID OFFSET 0 ROWS FETCH FIRST LEN(@sTexto) ROWS ONLY;
El conjunto de resultados obtenido podemos verlo a continuación.
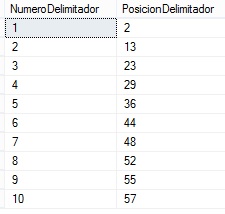
Analizando la cadena asignada a la variable @sTexto observaremos que el valor para el campo ResellerName contiene cuatro caracteres pipe que necesitamos eliminar.

Los números de orden del delimitador de inicio y fin para este campo son el 3 y 8, que corresponden a las posiciones 23 y 52 en el cómputo total de caracteres de la cadena, como muestra el siguiente diagrama.
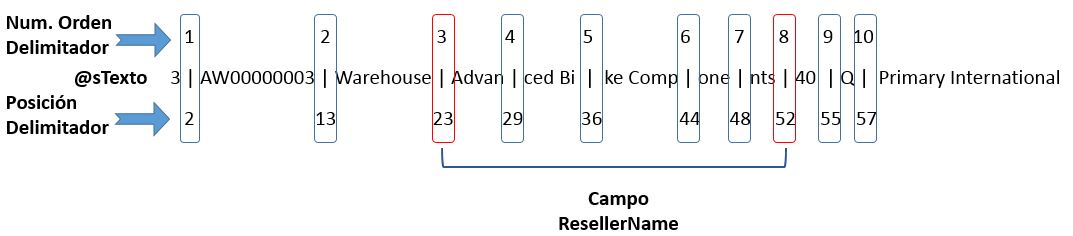
Selección de delimitadores inicial y final
Lo que haremos a continuación será incluir el código que calcula los delimitadores en una expresión común de tabla (cteDelimitadores), seleccionando desde la consulta externa aquellos delimitadores que anteriormente hemos indicado que representan el inicio y fin del campo a depurar. Para facilitar el desarrollo del código asignaremos a variables los datos con los que vamos a trabajar: cadena, carácter delimitador, número de campo sobre el que vamos a realizar la depuración y número total de campos existente en la cadena.
DECLARE @sTexto AS varchar(100);
DECLARE @sDelimitador AS varchar(1);
DECLARE @nCampoDepurar AS int;
DECLARE @nTotalCampos AS int;
SET @sTexto = '3|AW00000003|Warehouse|Advan|ced Bi|ke Comp|one|nts|40|Q|Primary International';
SET @sDelimitador = '|';
SET @nCampoDepurar = 4;
SET @nTotalCampos = 7;
WITH
cteDelimitadores AS
(
SELECT
ROW_NUMBER() OVER(ORDER BY NumeroID) AS NumeroDelimitador,
NumeroID AS PosicionDelimitador
FROM Numeros
WHERE SUBSTRING(@sTexto,NumeroID,1) = @sDelimitador
ORDER BY NumeroID
OFFSET 0 ROWS
FETCH FIRST LEN(@sTexto) ROWS ONLY
)
SELECT
NumeroDelimitador,
PosicionDelimitador
FROM cteDelimitadores
WHERE NumeroDelimitador IN (
@nCampoDepurar - 1),
(
((SELECT MAX(NumeroDelimitador) FROM cteDelimitadores) -
(@nTotalCampos - @nCampoDepurar)) + 1
)
)

Averiguadas las posiciones de la subcadena a obtener, y al igual que hicimos en el paso anterior, situaremos el código para calcular las posiciones de inicio y fin en una expresión de tabla (cteDelimitadoresInicioFin), volviendo a generar el número de orden del delimitador, ya que llegados a este punto, el conjunto de resultados con el que vamos a trabajar estará compuesto únicamente por dos filas, facilitando así el inminente trabajo con SUBSTRING, puesto que de antemano sabremos que la fila con el número de delimitador 1 contendrá la primera posición de la subcadena, y la fila con el delimitador 2 corresponderá a la última posición.
DECLARE @sTexto AS varchar(100);
DECLARE @sDelimitador AS varchar(1);
DECLARE @nCampoDepurar AS int;
DECLARE @nTotalCampos AS int;
SET @sTexto = '3|AW00000003|Warehouse|Advan|ced Bi|ke Comp|one|nts|40|Q|Primary International';
SET @sDelimitador = '|';
SET @nCampoDepurar = 4;
SET @nTotalCampos = 7;
WITH
cteDelimitadores AS
(
SELECT
ROW_NUMBER() OVER(ORDER BY NumeroID) AS NumeroDelimitador,
NumeroID AS PosicionDelimitador
FROM Numeros
WHERE SUBSTRING(@sTexto,NumeroID,1) = @sDelimitador
ORDER BY NumeroID
OFFSET 0 ROWS
FETCH FIRST LEN(@sTexto) ROWS ONLY
),
cteDelimitadoresInicioFin AS
(
SELECT
ROW_NUMBER() OVER(ORDER BY NumeroDelimitador) AS NumeroDelimitador,
PosicionDelimitador
FROM cteDelimitadores
WHERE NumeroDelimitador IN (
(@nCampoDepurar - 1),
(
((SELECT MAX(NumeroDelimitador) FROM cteDelimitadores) -
(@nTotalCampos - @nCampoDepurar)) + 1
)
)
)
SELECT *
FROM cteDelimitadoresInicioFin

Extracción de la subcadena incorrecta
A continuación agregaremos a la consulta una nueva expresión de tabla (cteCampoOriginal) en la que emplearemos la función SUBSTRING para extraer la subcadena a depurar. Los parámetros start y length de SUBSTRING los obtendremos a partir de los valores de la expresión de tabla anterior, encargada de calcular las posiciones inicial y final de los delimitadores.
DECLARE @sTexto AS varchar(100);
DECLARE @sDelimitador AS varchar(1);
DECLARE @nCampoDepurar AS int;
DECLARE @nTotalCampos AS int;
SET @sTexto = '3|AW00000003|Warehouse|Advan|ced Bi|ke Comp|one|nts|40|Q|Primary International';
SET @sDelimitador = '|';
SET @nCampoDepurar = 4;
SET @nTotalCampos = 7;
WITH
cteDelimitadores AS
(
SELECT
ROW_NUMBER() OVER(ORDER BY NumeroID) AS NumeroDelimitador,
NumeroID AS PosicionDelimitador
FROM Numeros
WHERE SUBSTRING(@sTexto,NumeroID,1) = @sDelimitador
ORDER BY NumeroID
OFFSET 0 ROWS
FETCH FIRST LEN(@sTexto) ROWS ONLY
),
cteDelimitadoresInicioFin AS
(
SELECT
ROW_NUMBER() OVER(ORDER BY NumeroDelimitador) AS NumeroDelimitador,
PosicionDelimitador
FROM cteDelimitadores
WHERE NumeroDelimitador IN (
(@nCampoDepurar - 1),
(
((SELECT MAX(NumeroDelimitador) FROM cteDelimitadores) -
(@nTotalCampos - @nCampoDepurar)) + 1
)
)
),
cteCampoOriginal AS
(
SELECT
SUBSTRING(
@sTexto,
(SELECT PosicionDelimitador + 1 FROM cteDelimitadoresInicioFin WHERE NumeroDelimitador = 1),
(
(SELECT PosicionDelimitador FROM cteDelimitadoresInicioFin WHERE NumeroDelimitador = 2) -
(SELECT PosicionDelimitador FROM cteDelimitadoresInicioFin WHERE NumeroDelimitador = 1)
) - 1
) AS CampoOriginal
)
SELECT *
FROM cteCampoOriginal
![]()
Depurando el exceso de delimitadores
Para eliminar los caracteres pipe de la subcadena que acabamos de obtener utilizaremos la función REPLACE dentro de una última expresión de tabla (cteCampoDepurado), la cual devolverá tanto la subcadena original como la ya depurada sin delimitadores. En la siguiente sentencia vemos el código al completo, donde podemos observar la evolución de nuestro proceso, desde el texto completo original al depurado, pasando por la subcadena original y la depurada.
DECLARE @sTexto AS varchar(100);
DECLARE @sDelimitador AS varchar(1);
DECLARE @nCampoDepurar AS int;
DECLARE @nTotalCampos AS int;
SET @sTexto = '3|AW00000003|Warehouse|Advan|ced Bi|ke Comp|one|nts|40|Q|Primary International';
SET @sDelimitador = '|';
SET @nCampoDepurar = 4;
SET @nTotalCampos = 7;
WITH
cteDelimitadores AS
(
SELECT
ROW_NUMBER() OVER(ORDER BY NumeroID) AS NumeroDelimitador,
NumeroID AS PosicionDelimitador
FROM Numeros
WHERE SUBSTRING(@sTexto,NumeroID,1) = @sDelimitador
ORDER BY NumeroID
OFFSET 0 ROWS
FETCH FIRST LEN(@sTexto) ROWS ONLY
),
cteDelimitadoresInicioFin AS
(
SELECT
ROW_NUMBER() OVER(ORDER BY NumeroDelimitador) AS NumeroDelimitador,
PosicionDelimitador
FROM cteDelimitadores
WHERE NumeroDelimitador IN (
(@nCampoDepurar - 1),
(
((SELECT MAX(NumeroDelimitador) FROM cteDelimitadores) -
(@nTotalCampos - @nCampoDepurar)) + 1
)
)
),
cteCampoOriginal AS
(
SELECT
SUBSTRING(
@sTexto,
(SELECT PosicionDelimitador + 1 FROM cteDelimitadoresInicioFin WHERE NumeroDelimitador = 1),
(
(SELECT PosicionDelimitador FROM cteDelimitadoresInicioFin WHERE NumeroDelimitador = 2) -
(SELECT PosicionDelimitador FROM cteDelimitadoresInicioFin WHERE NumeroDelimitador = 1)
) - 1
) AS CampoOriginal
),
cteCampoDepurado AS
(
SELECT
CampoOriginal,
REPLACE(CampoOriginal,@sDelimitador,'') AS CampoDepurado
FROM cteCampoOriginal
)
SELECT
@sTexto AS TextoOriginal,
CampoOriginal,
CampoDepurado,
REPLACE(@sTexto,CampoOriginal,CampoDepurado) AS TextoDepurado
FROM cteCampoDepurado

Organizar el código para su reutilización
Para poder reutilizar todo este código en diferentes escenarios de trabajo vamos a situarlo en una función de tipo escalar que llamaremos DepurarDelimitadores. En los parámetros a pasar a esta función encontramos la cadena que contiene el valor a depurar, el carácter delimitador del texto, el número del campo a depurar y el número total de campos a tratar. El valor de retorno de la función, cuyo código vemos a continuación, será la cadena pasada en el primer parámetro una vez quitados los delimitadores sobrantes de la subcadena correspondiente al campo a depurar.
CREATE FUNCTION DepurarDelimitadores(@sTexto AS varchar(100),
@sDelimitador AS char(1),
@nCampoDepurar AS int,
@nTotalCampos AS int
)
RETURNS varchar(100)
AS
BEGIN
DECLARE @sTextoDepurado AS varchar(100);
WITH
cteDelimitadores AS
(
SELECT
ROW_NUMBER() OVER(ORDER BY NumeroID) AS NumeroDelimitador,
NumeroID AS PosicionDelimitador
FROM Numeros
WHERE SUBSTRING(@sTexto,NumeroID,1) = @sDelimitador
ORDER BY NumeroID
OFFSET 0 ROWS
FETCH FIRST LEN(@sTexto) ROWS ONLY
),
cteDelimitadoresInicioFin AS
(
SELECT
ROW_NUMBER() OVER(ORDER BY NumeroDelimitador) AS NumeroDelimitador,
PosicionDelimitador
FROM cteDelimitadores
WHERE NumeroDelimitador IN (
(@nCampoDepurar - 1),
(
((SELECT MAX(NumeroDelimitador) FROM cteDelimitadores) -
(@nTotalCampos - @nCampoDepurar)) + 1
)
)
),
cteCampoOriginal AS
(
SELECT
SUBSTRING(
@sTexto,
(SELECT PosicionDelimitador + 1 FROM cteDelimitadoresInicioFin WHERE NumeroDelimitador = 1),
(
(SELECT PosicionDelimitador FROM cteDelimitadoresInicioFin WHERE NumeroDelimitador = 2) -
(SELECT PosicionDelimitador FROM cteDelimitadoresInicioFin WHERE NumeroDelimitador = 1)
) - 1
) AS CampoOriginal
),
cteCampoDepurado AS
(
SELECT
CampoOriginal,
REPLACE(CampoOriginal,@sDelimitador,'') AS CampoDepurado
FROM cteCampoOriginal
)
SELECT
@sTextoDepurado = REPLACE(@sTexto,CampoOriginal,CampoDepurado)
FROM cteCampoDepurado;
RETURN @sTextoDepurado;
END
Una vez creada la función vamos a probar su funcionamiento utilizando la cadena con la que hemos experimentado a lo largo del desarrollo de todo el proceso.

Limpieza de los datos origen
Finalizado el desarrollo del código encargado de eliminar los delimitadores sobrantes, la siguiente tarea consistirá en importar el archivo de texto a una tabla formada por una sola columna, realizando la depuración del excedente de caracteres delimitadores sobre esta nueva tabla. A continuación vemos las sentencias encargadas de la creación y carga de datos para dicha tabla.
CREATE TABLE ColumnaTexto
(
Columna varchar(200) NULL
)
BULK INSERT ColumnaTexto
FROM ‘C:\Datos\DimReseller.txt’
WITH (CODEPAGE = ‘ACP’, FIRSTROW = 2)
Analicemos ahora cómo aplicar la función DepurarDelimitadores para eliminar los delimitadores innecesarios en la tabla ColumnaTexto. Recordemos que cada fila de esta tabla tiene seis caracteres delimitadores (exceptuando aquellas con exceso de dicho carácter), que a su vez definen siete campos.
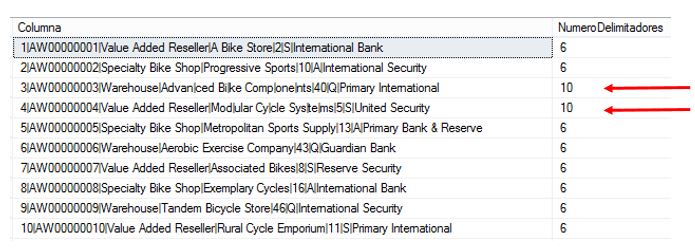
Si queremos averiguar, por lo tanto, las filas de la tabla a las que hay que aplicar la depuración, tenemos que encontrar aquellas que contengan más de seis delimitadores; lo que conseguiremos calculando la diferencia entre la longitud total de caracteres de cada fila menos dicha longitud sin los caracteres delimitadores. Para realizar estos cálculos emplearemos de forma combinada las funciones LEN y REPLACE, tal y como muestra la siguiente sentencia.
SELECT
Columna,
(LEN(Columna) – LEN(REPLACE(Columna,’|’,»))) AS NumeroDelimitadores
FROM ColumnaTexto
Adaptando el código anterior dentro de una sentencia de actualización que utilice una expresión de tabla para seleccionar aquellas filas con exceso de delimitadores, la operación de modificación sobre la tabla ColumnaTexto empleando la función DepurarDelimitadores quedaría de la siguiente manera para depurar el cuarto campo de los siete existentes en cada fila.
WITH cteColumnaTexto AS ( SELECT Columna FROM ColumnaTexto WHERE (LEN(Columna) - LEN(REPLACE(Columna,'|',''))) > 6 ) UPDATE cteColumnaTexto SET Columna = dbo.DepurarDelimitadores(Columna,'|',4,7);
Tras la ejecución de la anterior sentencia, las filas con la cantidad incorrecta de delimitadores habrán sido corregidas.
Traslado de los datos depurados a la tabla definitiva
Hemos llegado prácticamente al final del proceso. Tan sólo resta traspasar los valores separados por delimitadores de cada fila de la tabla ColumnaTexto a la tabla Reseller, siendo esta una tarea que realizaremos en dos fases.
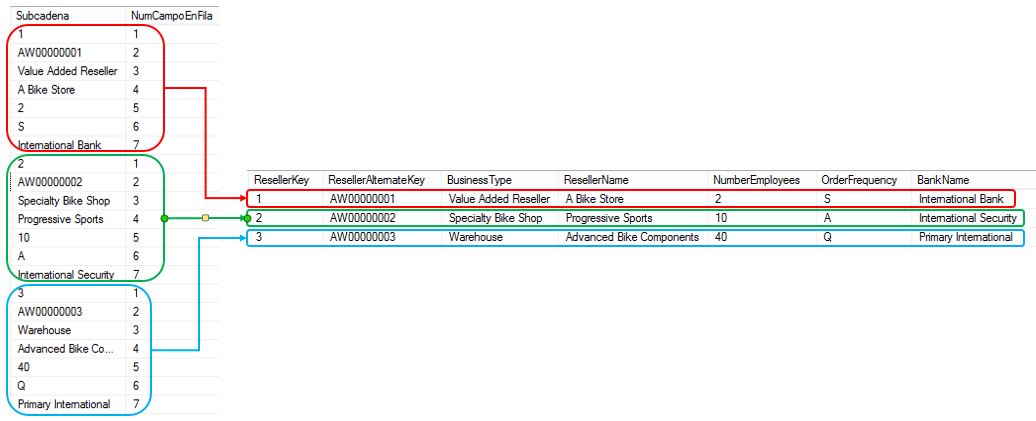
En la primera fase, ayudándonos de la función ParticionarCadena que creamos en el artículo anterior y de la instrucción CROSS APPLY, generaremos un conjunto de resultados a partir de la tabla ColumnaTexto, donde cada fila de dicha tabla se subdividirá en siete filas. De cada una de estas nuevas filas, la columna Subcadena contendrá el valor de uno de los campos de una fila de la tabla ColumnaTexto, y la columna NumCampoEnFila servirá de identificador del número de columna de la tabla Reseller, a la que más adelante traspasaremos el valor. A continuación se muestra la sentencia que debemos utilizar.
SELECT
C.Columna,
SubC.Subcadena,
ROW_NUMBER() OVER(PARTITION BY C.Columna ORDER BY C.Columna) AS
NumCampoEnFila
FROM ColumnaTexto AS C
CROSS APPLY dbo.ParticionarCadena(C.Columna,’|’) AS SubC
El siguiente diagrama ilustra esta parte del proceso.

En la segunda fase situaremos la sentencia anterior en una expresión de tabla y pivotaremos el conjunto de resultados obtenido a partir de la misma.
WITH cteColumnaTexto AS
(
SELECT
C.Columna,
SubC.Subcadena,
ROW_NUMBER() OVER(PARTITION BY C.Columna ORDER BY C.Columna) AS
NumCampoEnFila
FROM ColumnaTexto AS C
CROSS APPLY dbo.ParticionarCadena(C.Columna,'|') AS SubC
)
SELECT
[1] AS ResellerKey,
[2] AS ResellerAlternateKey,
[3] AS BusinessType,
[4] AS ResellerName,
[5] AS NumberEmployees,
[6] AS OrderFrequency,
[7] AS BankName
FROM
(
SELECT
Columna,
Subcadena,
NumCampoEnFila
FROM cteColumnaTexto
) AS tblOrigen
PIVOT
(
MAX(Subcadena)
FOR NumCampoEnFila IN (
[1],
[2],
[3],
[4],
[5],
[6],
[7]
)
) AS tblPivot;
La siguiente figura muestra gráficamente la operación de transposición de filas a columnas conseguida mediante la instrucción PIVOT.
Añadiendo una instrucción INSERT INTO sobre la tabla Reseller a la sentencia anterior habremos logrado nuestro objetivo.
WITH cteColumnaTexto AS
(
SELECT
C.Columna,
SubC.Subcadena,
ROW_NUMBER() OVER(PARTITION BY C.Columna ORDER BY C.Columna) AS
NumCampoEnFila
FROM ColumnaTexto AS C
CROSS APPLY dbo.ParticionarCadena(C.Columna,'|') AS SubC
)
INSERT INTO Reseller (
ResellerKey,
ResellerAlternateKey,
BusinessType,
ResellerName,
NumberEmployees,
OrderFrequency,
BankName
)
SELECT
[1],
[2],
[3],
[4],
[5],
[6],
[7]
FROM
(
SELECT
Columna,
Subcadena,
NumCampoEnFila
FROM cteColumnaTexto
) AS tblOrigen
PIVOT
(
MAX(Subcadena)
FOR NumCampoEnFila IN (
[1],
[2],
[3],
[4],
[5],
[6],
[7]
)
) AS tblPivot;
Una vez ejecutada esta sentencia, las columnas de cada una de las filas de la tabla Reseller contendrán los datos que anteriormente se encontraban unidos en la columna única de la tabla ColumnaTexto.
Resumiendo a modo de conclusión, en el presente artículo hemos mostrado una más de las variadas aplicaciones que podemos dar a las tablas numéricas auxiliares, consistente en este caso en permitirnos depurar un archivo de datos con valores separados por un delimitador. Confío en que esta técnica pueda resultar de utilidad al lector en alguna ocasión.


kiquenet
Grandioso !!
lmblanco
Hola Enrique
Muchas gracias, me alegra que te haya gustado 🙂
Un saludo
Luismi
mposadas
Exhaustivo, claro y muy completo, como siempre. Gran trabajo, Luismi.
lmblanco
Hola Marino
Muchas gracias, celebro que te haya gustado 🙂
Un saludo
Luismi