
Después de desarrollar la carga de datos para las tablas de dimensión (Cliente, Cliente optimizado y Producto), en la entrega actual nos ocuparemos de crear un proceso equivalente para Ventas, la tabla de hechos del modelo. Tal y como indicábamos en la primera parte de esta serie, ahora intervendrán los archivos de microdatos que hemos descargado desde la web del INE. En este caso se trata de una carga peculiar, en tanto que no vamos a utilizar realmente los datos contenidos en dichos archivos.
La finalidad de esta parte del desarrollo consiste en la obtención, para cada uno de los años de datos a manejar, de un número lo suficientemente elevado de registros. Con la técnica que vamos a emplear, lograremos ese volumen de datos sin necesidad de tener que implementar una rutina de generación aleatoria de registros desde cero; si bien es cierto, que existirá un componente de aleatoriedad en los valores a generar para ciertas columnas.
La técnica de la que hablamos, y que se explicó en el artículo sobre creación de tablas numéricas auxiliares, publicado en este blog, se basa en la presencia de filas en una tabla, para, de esa forma, realizar la inserción de nuevas filas en otra. Puesto que en el mencionado artículo se explican los pormenores de dicho escenario de trabajo, recomendamos al lector su consulta, a fin de comprender mejor el proceso de carga cuando lo apliquemos en el ejemplo actual.
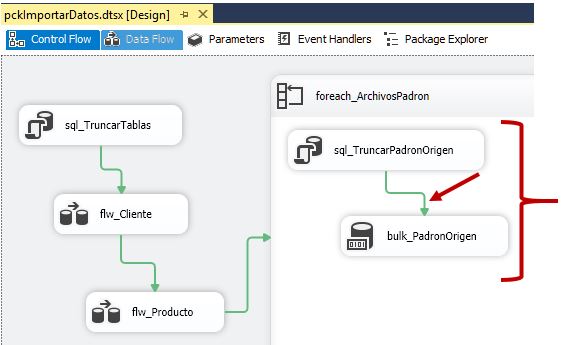
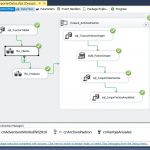
Como complejidad añadida, tendremos que recorrer todos los archivos de microdatos existentes en la ruta donde los hayamos posicionado, repitiendo la operación de inserción en la base de datos para cada uno de ellos. Este particular lo resolveremos mediante un contenedor de tipo Foreach Loop, que configuraremos para que realice una iteración sobre la ubicación de los archivos, devolviendo, en cada pasada, la ruta y nombre del archivo en curso, que recogeremos mediante una variable.
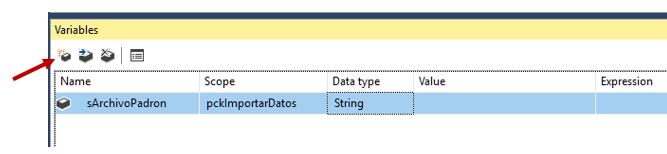
Respecto a la creación de la variable, en el caso de que el panel Variables no se encuentre visible en el entorno de Visual Studio, lo activaremos mediante la opción de menú View | Other Windows | Variables, haciendo a continuación clic en el botón Add Variable, para crear una nueva variable a la que daremos el nombre sArchivoPadron, con una visibilidad (Scope) a nivel del paquete, y tipo de dato String.
A continuación, añadiremos al paquete el contenedor Foreach Loop, al que daremos el nombre foreach_ArchivosPadron.
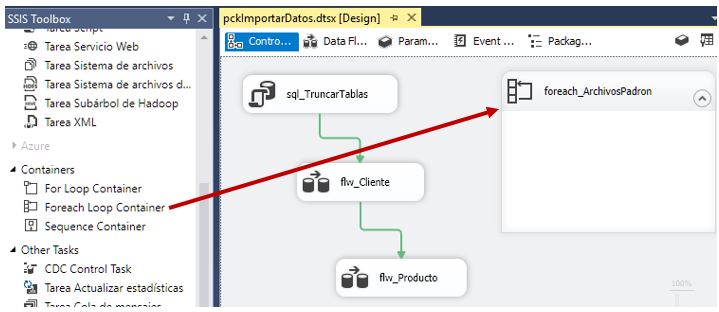
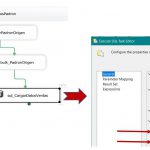
Comenzaremos a editar (clic derecho, opción Edit) este contenedor situándonos en el apartado Collection, donde, para la propiedad Enumerator seleccionaremos el valor Enumerador de archivos Foreach. En la propiedad Folder haremos clic en el botón Browse, para seleccionar la carpeta en la que se encuentran los archivos. Dentro del cuadro de texto Files, debemos escribir el nombre del archivo a manejar, pero como en nuestro caso se trata de varios archivos, utilizaremos un nombre que incluya caracteres comodín. Podríamos emplear el valor * . * , pero dado que los archivos que vamos a cargar comienzan por el nombre micro, escribiremos micro*.txt, por si se diera la circunstancia de que en la ruta utilizada hubiera más archivos. Para terminar este apartado, en la propiedad Retrieve file name tenemos que especificar el modo en el que el contenedor devuelve el nombre del archivo en cada iteración; en este ejemplo seleccionaremos el valor Fully qualified, para obtener una cadena que incluya tanto el nombre como la ruta en la que reside el archivo.
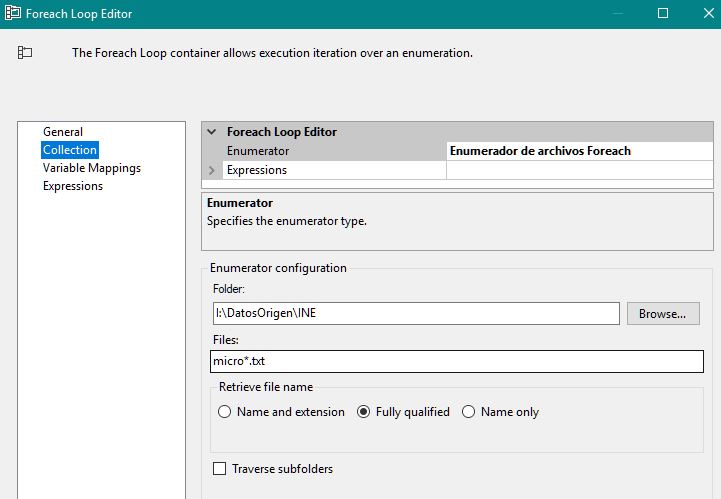
En tiempo de ejecución, mediante la variable sArchivoPadron, recogeremos el nombre del archivo que el contenedor devuelve en cada una de sus iteraciones. Para ello, en el apartado Variable Mappings, abriremos la lista desplegable Variable, seleccionando User::sArchivoPadron.
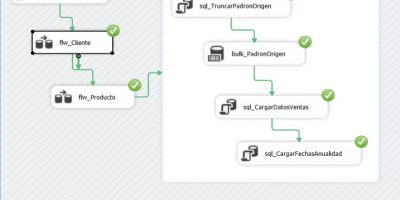
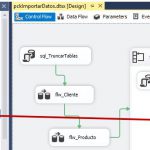
Para cada archivo de datos de Padrón, el contenedor Foreach Loop necesitará ejecutar las siguientes acciones: truncar la tabla PadronOrigen; cargar el archivo correspondiente en la tabla PadronOrigen; añadir a la tabla Ventas los registros de la tabla PadronOrigen; e insertar en la tabla fechas una cantidad de filas equivalente a los días del año del archivo cargado. Seguidamente, procederemos a configurar el contenedor para lograr dicho comportamiento.
En primer lugar, agregaremos una tarea Ejecutar SQL, que se ocupará de truncar la tabla PadronOrigen.

A continuación, haremos clic derecho en el panel Connection Managers, eligiendo la opción New File Connection, que abrirá la ventana File Connection Manager Editor, desde la que navegaremos a la ruta en la que se hallan los archivos a cargar, seleccionando uno cualquiera.
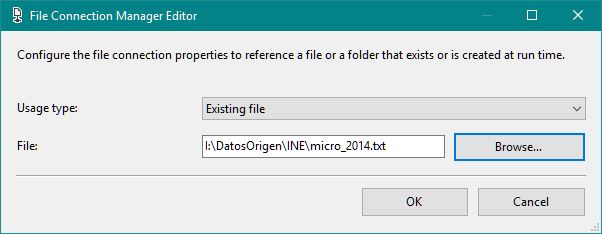
Aceptando esta ventana, habremos creado una conexión contra uno de los archivos. Sin embargo, son varios los archivos que necesitan ser incorporados a la base de datos, ¿Debemos crear una conexión independiente para cada uno de ellos?, Evidentemente no, ya que podemos configurar la conexión que acabamos de crear para que sea reutilizada, pudiendo así cargar con ella todos los archivos.
Continuando en el panel Connection Managers, y con esta conexión seleccionada, pulsaremos F4 para abrir el panel Properties, donde cambiaremos el nombre de la conexión por cnArchivoPadron. Después haremos clic en el botón de puntos suspensivos de la propiedad Expressions, para abrir la ventana Property Expressions Editor, en la que abriremos la lista desplegable Property, eligiendo ConnectionString.
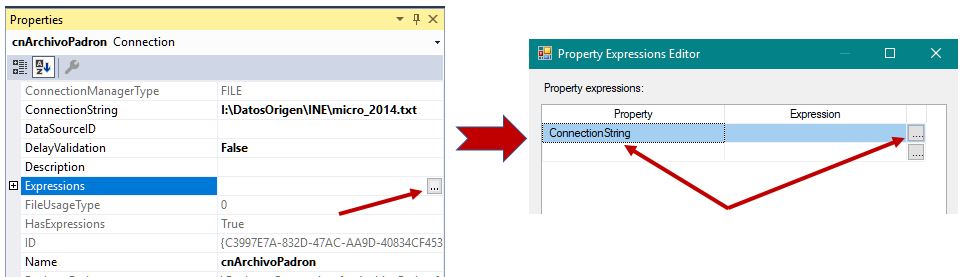
Para asignar valor a ConnectionString, haremos clic en el botón de puntos suspensivos de la columna Expression, que nos llevará a la ventana Expression Builder, donde desplegaremos el nodo Variables and Parameters. Desde aquí arrastraremos la variable sArchivoPadron al panel Expression.
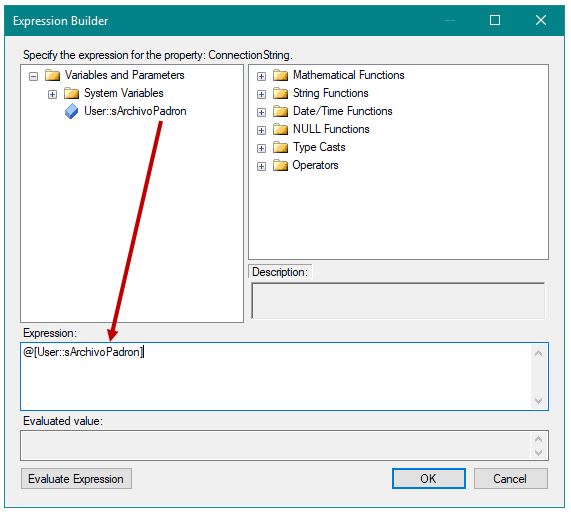
Aceptaremos todo hasta volver al panel Properties, donde borraremos el contenido de la propiedad ConnectionString, ya que, a partir de ahora, dicha propiedad será asignada en cada iteración del Foreach Loop, a través de la expresión que acabamos de crear.
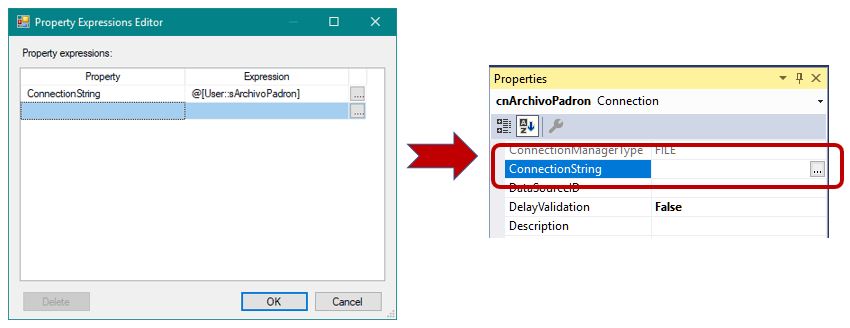
Regresando al contenedor Foreach Loop, ahora añadiremos una tarea de tipo Inserción masiva (Bulk Insert Task), cuya finalidad consiste en insertar el contenido de un archivo en una tabla de la base de datos. Una de las características de esta tarea, es que se encuentra optimizada para proporcionar el mejor rendimiento durante el proceso de carga de archivos de gran tamaño. Como habrá podido deducir el lector, esta será la tarea que cargará en la tabla PadronOrigen, los archivos de población del Padrón de habitantes, que hemos descargado de la web del INE.
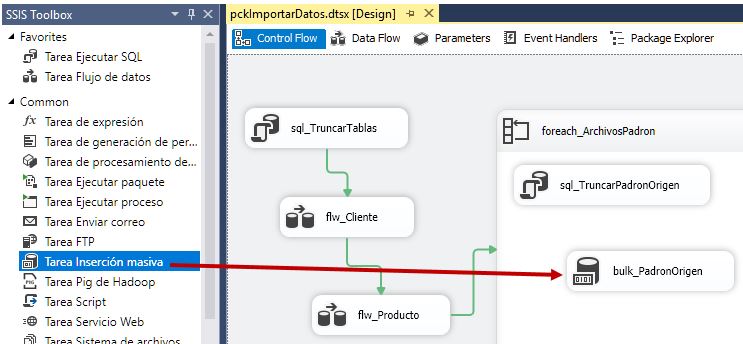
Tras asignar el nombre bulk_PadronOrigen a la tarea, abriremos su ventana de edición (Bulk Insert Task Editor), y en el apartado Connection, asignaremos a la propiedad Connection la conexión cnVentasAnuales. En la propiedad DestinationTable seleccionaremos la tabla PadronOrigen, y en la propiedad File elegiremos la conexión cnArchivoPadron.
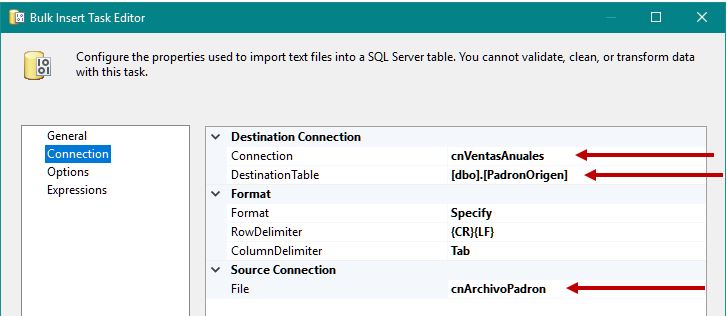
En el apartado Options, dejaremos los valores predeterminados excepto en la propiedad Options, donde seleccionaremos Table lock; con ello, la tarea bloqueará la tabla en tiempo de ejecución, proporcionando una mayor velocidad durante la operación de volcado de los datos.

Aceptaremos esta ventana de edición, y conectaremos la flecha de restricción de precedencia de sql_TruncarPadronOrigen con bulk_PadronOrigen.
Cuando la tarea de tipo Inserción masiva termine de ejecutarse, las filas de uno de los archivos se habrán copiado en la tabla PadronOrigen. La siguiente operación que debemos implementar consiste en insertar, en la tabla Ventas, una cantidad de registros igual a la que actualmente existe en la tabla PadronOrigen, pero cuyo contenido corresponda a datos de ventas de productos, simulando de esta manera las ventas realizadas durante un año.
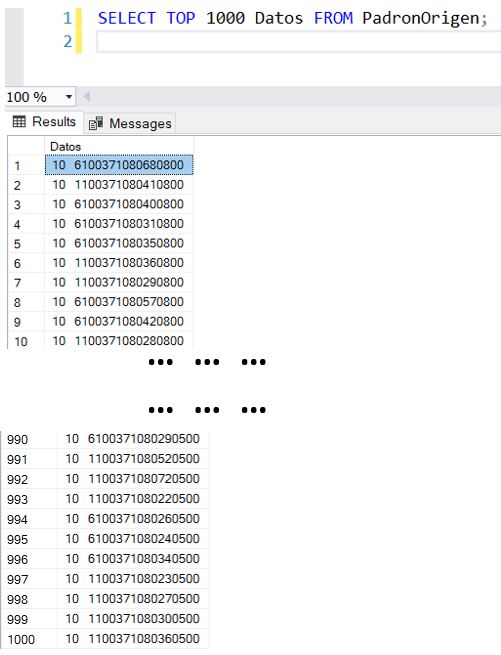
Aquí es donde entra en juego la técnica de presencia de filas aplicada a la tabla PadronOrigen, que nos permitirá añadir el volumen de registros necesario a la tabla Ventas. Veamos en qué consiste, a través de una pequeña demostración, paso a paso, de su aplicación. Empecemos ejecutando la siguiente sentencia.
SELECT TOP 1000 Datos FROM PadronOrigen;
Como el lector habrá podido suponer, obtenemos los mil primeros registros de la tabla.
Sustituyamos ahora, la columna Datos por una columna dinámica que devuelva un número.
SELECT TOP 1000 1 AS ColumnaNueva FROM PadronOrigen;

El mero hecho de invocar el nombre de la tabla PadronOrigen en la consulta, genera el número de filas indicado en la cláusula TOP, con el valor 1 para la columna dinámica a la que hemos llamado ColumnaNueva. Este comportamiento sería lo que calificaríamos como presencia de filas de la tabla en la consulta, ya que en este ejemplo concreto no ha sido necesario especificar la columna Datos, perteneciente a la tabla Producto.
Traslademos ahora esta situación a la creación de los valores para las columnas de la tabla Ventas. Como ya sabemos, la tabla PadronOrigen contiene datos poblacionales, pero nosotros necesitamos añadir registros de ventas, por lo que vamos a generarlos de forma aleatoria, empleando para ello la combinación de funciones NEWID, CHECKSUM y ABS, tal y como se expone en el artículo de este blog sobre fechas aleatorias. Mientras, la tabla PadronOrigen proporcionará el número de filas que se necesita insertar en la tabla Ventas, gracias a la técnica explicada anteriormente.
Abordemos, a continuación, la creación de valores para cada columna de Ventas por separado, de forma que el lector pueda apreciar mejor las particularidades que encierra cada una. Posteriormente, y como es lógico, aglutinaremos en una sentencia única la inserción sobre esta tabla.
Comencemos por la columna ClienteID de la tabla Ventas. Para esta columna, debemos generar valores que se encuentren en el rango de 11000 a 29483, ya que se trata del mismo intervalo existente en la columna de idéntico nombre de la tabla Cliente, con la que estableceremos una relación en la próxima fase de construcción del modelo tabular.
Para generar un valor aleatorio, dentro del rango indicado en el anterior párrafo, calcularemos el módulo (resto) resultante de dividir, el valor devuelto por las funciones ABS, CHECKSUM y NEWID, entre el número de filas de la tabla Cliente. Al resultado de todo lo anterior, le sumaremos el primer valor (valor más inferior) de la columna ClienteID de la tabla Cliente.
DECLARE @nNumFilasClientes AS int; DECLARE @nPrimerClienteID AS int; SELECT @nNumFilasClientes = COUNT(*), @nPrimerClienteID = MIN(ClienteID) FROM Cliente; SELECT (ABS(CHECKSUM(NEWID())) % (@nNumFilasClientes)) + @nPrimerClienteID;
Modifiquemos el cálculo del valor aleatorio en el bloque de código anterior, convirtiéndolo en una sentencia de inserción sobre la tabla Ventas, basada en una consulta contra la tabla PadronOrigen, en la que cada fila devuelva dicho cálculo aleatorio.
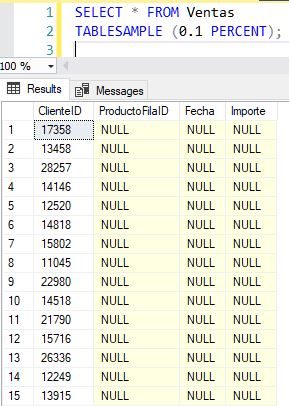
DECLARE @nNumFilasClientes AS int; DECLARE @nPrimerClienteID AS int; SELECT @nNumFilasClientes = COUNT(*), @nPrimerClienteID = MIN(ClienteID) FROM Cliente; TRUNCATE TABLE Ventas; INSERT INTO Ventas WITH (TABLOCK) (ClienteID) SELECT (ABS(CHECKSUM(NEWID())) % (@nNumFilasClientes)) + @nPrimerClienteID FROM PadronOrigen;
Como resultado, obtendremos la tabla Ventas, con los valores rellenos para la columna ClienteID.
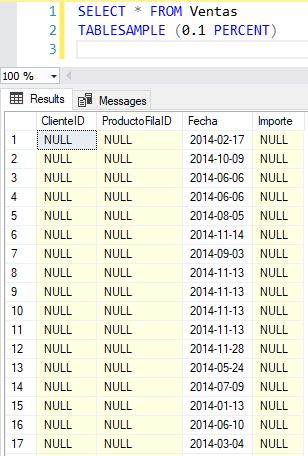
Pasemos ahora a la columna Fecha, para la cual, las fechas a generar, deberán estar comprendidas dentro del año correspondiente al mismo periodo de datos del archivo de Padrón que hemos cargado en la tabla PadronOrigen.
Utilicemos el año 2014 como ejemplo para esta demostración. Comenzaremos calculando la primera fecha, que obtenemos mediante la asignación de una cadena con el año a una variable de tipo date. A continuación, calcularemos la última fecha utilizando la variable que contiene la fecha de inicio y la función EOMONTH. La función DATEDIFF nos ayudará a obtener la cantidad de días de que consta el año, pasándole como parámetro las variables con los intervalos de fecha. Con toda la información anterior, en la sentencia de inserción de la tabla Ventas, calcularemos un número de día aleatorio, empleando una técnica similar a la utilizada para la columna ClienteID. Sumando dicho número de día a la primera fecha del año con la función DATEADD obtendremos nuestra fecha, pero como tipo datetime, por lo que aplicaremos la función CONVERT para transformarla a date.
DECLARE @sAnualidad varchar(4); DECLARE @dtFechaInicio AS date; DECLARE @dtFechaFin AS date; DECLARE @nNumDiasAnualidad AS int; SET @sAnualidad = '2014'; SET @dtFechaInicio = @sAnualidad; SET @dtFechaFin = EOMONTH(@dtFechaInicio,11); SET @nNumDiasAnualidad = DATEDIFF(day,@dtFechaInicio,@dtFechaFin) + 1; TRUNCATE TABLE Ventas; INSERT INTO Ventas WITH (TABLOCK) (Fecha) SELECT CONVERT(date,DATEADD(day,(ABS(CHECKSUM(NEWID())) % @nNumDiasAnualidad),@dtFechaInicio)) FROM PadronOrigen;
Para terminar con el cálculo de valores de la tabla Ventas, llega el turno de las columnas ProductoFilaID e Importe.
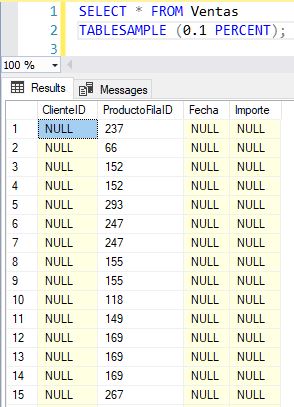
Respecto a ProductoFilaID, calcularemos el valor máximo de la columna del mismo nombre de la tabla Producto; y en la sentencia de inserción de la tabla Ventas, al aplicar la expresión de cálculo del valor aleatorio, sumaremos 1 a dicho resultado.
DECLARE @nNumFilasProductos AS int; SET @nNumFilasProductos = (SELECT MAX(ProductoFilaID) FROM Producto); TRUNCATE TABLE Ventas; INSERT INTO Ventas WITH (TABLOCK) (ProductoFilaID) SELECT (ABS(CHECKSUM(NEWID())) % @nNumFilasProductos) + 1 FROM PadronOrigen;
Para lograr el valor a insertar en la columna Importe, tomaremos el resultado aleatorio que acabamos de calcular y lo cruzaremos con la columna ProductoFilaID de la tabla Producto. Modificaremos para ello la sentencia de inserción anterior, de forma que dentro de una expresión común de tabla, situaremos el cálculo aleatorio, cruzando a continuación dicha expresión de tabla con la tabla Producto, para insertar en la tabla Ventas los valores tanto para la columna ProductoFilaID, como para Importe.
DECLARE @nNumFilasProductos AS int; SET @nNumFilasProductos = (SELECT MAX(ProductoFilaID) FROM Producto); TRUNCATE TABLE Ventas; WITH cteCalcularProducto AS ( SELECT (ABS(CHECKSUM(NEWID())) % @nNumFilasProductos) + 1 AS ProductoFilaID FROM PadronOrigen ) INSERT INTO Ventas WITH (TABLOCK) ( ProductoFilaID, Importe ) SELECT cp.ProductoFilaID, p.Precio FROM cteCalcularProducto AS cp LEFT JOIN Producto AS p ON cp.ProductoFilaID = p.ProductoFilaID;

Nuestro siguiente paso, una vez expuestas cada una de las técnicas que calculan los valores para las columnas de la tabla Ventas, consistirá en la creación de un procedimiento almacenado que aúne todas estas operaciones, y que sea ejecutado a cada iteración del contenedor Foreach Loop. No obstante, esta será una tarea que trataremos en el próximo artículo de la serie, por lo que llegados al punto actual, damos por finalizada la actual entrega.


Deja un comentario