
Una tabla numérica auxiliar (denominada también tabla de conteo, tally table o simplemente tabla de números) es una tabla compuesta por una única columna, que almacena una cantidad variable de registros con valores numéricos consecutivos, y que se emplea como herramienta de soporte en operaciones tales como la generación de registros en otras tablas y la manipulación de cadenas en escenarios en los que tradicionalmente se recurre a algún tipo de estructura repetitiva, como pueda ser un cursor o bucle WHILE.
A lo largo de las dos entregas de que consta este artículo abordaremos algunas de las principales técnicas utilizadas en la creación de este tipo de tabla, dejando para un próximo artículo su aplicación práctica en diversos escenarios de uso.
Bucle WHILE
Si se trata de rellenar una tabla con una serie de números consecutivos, es probable que lo primero en lo que pensemos sea en utilizar un bucle WHILE, que se ejecute tantas veces como números necesitemos añadir a la tabla, de una forma parecida a la que mostramos a continuación (nótese que a lo largo de los ejemplos incluimos también diversas sentencias para evaluar los tiempos de ejecución de las técnicas presentadas y comparar así su rendimiento).
IF OBJECT_ID('Numeros','U') IS NOT NULL
BEGIN
DROP TABLE Numeros;
END
CREATE TABLE Numeros
(
NumeroID int NOT NULL
);
DECLARE @nContador AS INT;
DECLARE @dtInicio AS DATETIME;
DECLARE @dtFin AS DATETIME;
SET @dtInicio = CURRENT_TIMESTAMP;
SET @nContador = 1;
WHILE(@nContador <= 30000)
BEGIN
INSERT INTO Numeros (NumeroID)
VALUES (@nContador);
SET @nContador += 1;
END
SET @dtFin = CURRENT_TIMESTAMP;
SELECT DATEDIFF(millisecond,@dtInicio,@dtFin);
ALTER TABLE Numeros
ADD CONSTRAINT PK_Numeros
PRIMARY KEY (NumeroID)
El anterior bloque de código utiliza el operador compuesto += para incrementar la variable @nContador. Si nuestra versión de SQL Server no soporta dicho operador, emplearemos la construcción clásica:
SET @nContador = @nContador + 1;
Aunque el código del ejemplo funciona correctamente y cumple su cometido de rellenar la tabla Numeros con un conjunto de registros cuyos valores están comprendidos entre 1 y 30000, no estamos empleando la potencia de la programación basada en conjuntos, tal y como Jeff Moden, uno de los grandes especialistas en SQL Server, explica en «The ‘Numbers’ or ‘Tally’ Table: What it is and how it replaces a loop» [1]. Es por ello que en los siguientes apartados veremos cómo podemos corregir dicha situación.
Expresión Común de Tabla (Common Table Expression – CTE) recursiva
Una expresión común de tabla (CTE a partir de ahora) según detalla Itzik Ben-Gan en su obra «Microsoft SQL Server 2012 T-SQL Fundamentals» [2], es una construcción del lenguaje SQL, que según la consulta a abordar, nos permite crear expresiones de tabla organizando el código de la consulta de una forma más limpia y legible que mediante el uso de tablas derivadas o subconsultas.
Para crear una CTE utilizaremos la palabra clave WITH, seguida del nombre que damos a la CTE, la partícula AS, y entre paréntesis, el código de la consulta propio de la CTE o consulta interna (inner query). A continuación escribiremos el código de la consulta externa (outer query) que se ejecuta contra la CTE. Todo ello lo vemos seguidamente en un ejemplo que hace un cruce entre el resultado de una CTE basada en la tabla DimCustomer y la tabla FactInternetSales, de la base de datos AdventureWorksDW2012.

Esta explicación introductoria sobre CTEs viene motivada por el hecho de que es un elemento del lenguaje SQL dotado de una funcionalidad recursiva, que vamos a aplicar como otro de los medios para la creación de tablas numéricas; de ahí que para aquellos lectores que todavía no han trabajado con CTEs resulte un requisito imprescindible conocer su funcionamiento aunque sea de un modo somero.
Para construir una CTE recursiva, que nos evite el uso de un bucle WHILE, debemos utilizar al menos dos consultas. La primera, denominada elemento ancla, que se ejecuta una sola vez, devolverá un resultado simple que será utilizado como valor inicial por la segunda consulta, denominada elemento recursivo, que hace que la CTE se llame a sí misma, consiguiendo de esta manera la capacidad recursiva
El límite de llamadas recursivas lo establecemos en el elemento recursivo mediante una cláusula WHERE, como muestra el siguiente código, que genera un conjunto de números del 1 al 50.

En el anterior ejemplo, al llamar a la CTE desde la consulta externa (1) se ejecuta una única vez el elemento ancla (2) de la CTE, que devuelve el valor 1 con el alias de columna Num.
A continuación se produce, dentro de la CTE, una llamada a sí misma desde el elemento recursivo (3). Como la columna Num ya tiene el valor 1, fruto de la primera ejecución contra el elemento ancla, se suma 1 a dicha columna, por lo que ahora devuelve el valor 2.
Las sucesivas llamadas continúan ejecutando el elemento recursivo (3), incrementando la columna Num, hasta que se cumple la condición de la cláusula WHERE.
La cantidad de llamadas recursivas que pueden hacerse por defecto es de 100. No obstante, podemos cambiar este valor mediante el modificador OPTION (MAXRECURSION NumLlamadas), donde NumLlamadas representa la cantidad de ejecuciones recursivas que puede realizar la CTE, estando su valor comprendido entre 0 y 32767.
En el siguiente código, gracias al uso de dicho modificador, obtenemos una lista de números comprendida entre los valores 1 y 5000.
WITH cteContador AS ( SELECT 1 AS Num UNION ALL SELECT Num + 1 FROM cteContador WHERE Num < 5000 ) SELECT Num FROM cteContador OPTION (MAXRECURSION 5000);
En caso de necesitar un número de llamadas recursivas mayor que el límite de 32767, utilizaremos cero como parámetro de MAXRECURSION.
WITH cteContador AS ( SELECT 1 AS Num UNION ALL SELECT Num + 1 FROM cteContador WHERE Num < 39500 ) SELECT Num FROM cteContador OPTION (MAXRECURSION 0);
Una vez visto el funcionamiento de las CTEs recursivas volvemos a retomar nuestro objetivo inicial sobre creación de tablas numéricas, utilizando la técnica que acabamos de explicar, para lo cual emplearemos el siguiente código.
IF OBJECT_ID('Numeros','U') IS NOT NULL
BEGIN
DROP TABLE Numeros;
END
CREATE TABLE Numeros
(
NumeroID int NOT NULL
);
DECLARE @dtInicio AS DATETIME;
DECLARE @dtFin AS DATETIME;
SET @dtInicio = CURRENT_TIMESTAMP;
WITH cteContador AS
(
SELECT 1 AS Num
UNION ALL
SELECT Num + 1
FROM cteContador
WHERE Num < 30000
)
INSERT INTO Numeros (NumeroID)
SELECT Num
FROM cteContador
OPTION (MAXRECURSION 30000);
SET @dtFin = CURRENT_TIMESTAMP;
SELECT DATEDIFF(millisecond,@dtInicio,@dtFin);
ALTER TABLE Numeros
ADD CONSTRAINT PK_Numeros
PRIMARY KEY (NumeroID);
Si comparamos los tiempos de ejecución, comprobaremos que este último método para cargar la tabla numérica es, con diferencia, mucho más rápido que el utilizado con el bucle WHILE, por lo que aparentemente parece una solución más recomendable, ya que esta mayor velocidad en su funcionamiento puede llevarnos a pensar que también proporciona un mejor rendimiento en ejecución.
Sin embargo, como acabamos de decir, esta ventaja es sólo aparente, ya que el análisis de la mecánica interna utilizada por una CTE recursiva revela que su funcionamiento no es tan óptimo como podría pensarse en un principio, tal y como explica detalladamente Jeff Moden en su interesante artículo «Hidden RBAR: Counting with Recursive CTE’s» [3].
Ha llegado, por lo tanto, la hora de mostrar una técnica para crear una tabla numérica, que ofrezca una velocidad todavía mayor que los ejemplos anteriormente explicados, y un rendimiento en ejecución que sea realmente bueno.
Pseudo Cursor
Según se expone en [3], un pseudo cursor es un bucle basado en un conjunto de resultados obtenidos a partir de una consulta contra una tabla. También podría describirse como el producto de una consulta contra una tabla o combinación de tablas, pero utilizando solamente la presencia de filas de la tabla(s) involucrada(s) en la consulta. Puesto que es probable que estas explicaciones no resulten muy reveladoras para el lector, veamos lo que es un pseudo cursor a través de un ejemplo.
Si ejecutamos la siguiente consulta en alguna de nuestras bases de datos.
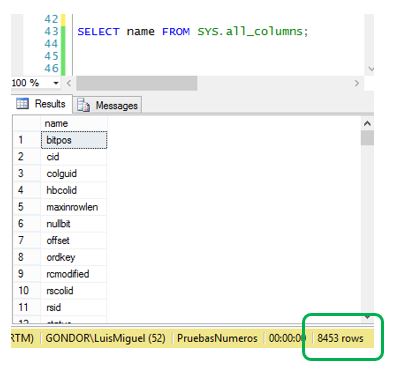
SELECT name FROM sys.all_columns;
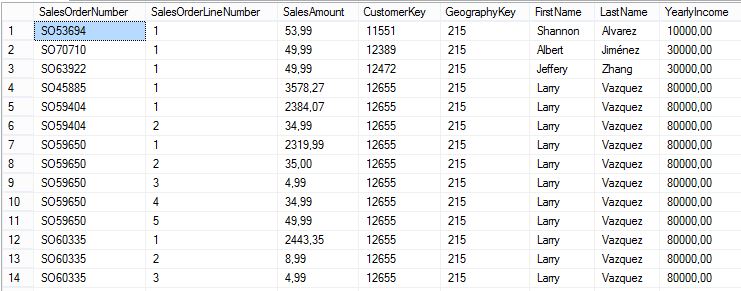
Nos devolverá un conjunto de resultados con los nombres de las columnas de las tablas que componen la base de datos, en un número que variará dependiendo de la cantidad de tablas existentes. En mi caso obtengo 8453 filas como puede apreciarse en la siguiente imagen.
Supongamos ahora que aprovechamos este conjunto de resultados para generar, además, una nueva columna con numeración secuencial mediante la función ROW_NUMBER().
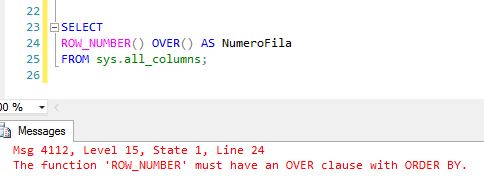
SELECT name, ROW_NUMBER() OVER(ORDER BY name) AS NumeroFila FROM sys.all_columns;

Como el objetivo que realmente perseguimos es la creación, única y exclusivamente, del intervalo de números, en el anterior bloque de código sobraría la columna name de la tabla sys.all_columns, pero si quitamos de la consulta dicha columna nos encontraremos con un error en ROW_NUMBER(), ya que la cláusula OVER(ORDER BY <cláusula>) es obligatoria.
Sin embargo, si en la cláusula ORDER BY empleamos la expresión SELECT NULL, conseguiremos un doble propósito: por un lado solucionaremos el error que se producía en ROW_NUMBER(); y por otro, lograremos nuestro objetivo de crear el rango de valores numéricos.
SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS NumeroFila FROM sys.all_columns;
La clave reside en la presencia de filas de la tabla sys.all_columns (obsérvese que no se hace uso de ninguna de las columnas de la tabla) que forma parte de la consulta, y que aquí actúa como fuente de datos en la generación de las filas para el intervalo, mientras que ROW_NUMBER() proporciona la lógica de la asignación del número correspondiente a cada fila.
Este funcionamiento combinado de ambos elementos: tabla y ROW_NUMBER(), para obtener un conjunto secuencial de números, que tradicionalmente requeriría el uso de un cursor o bucle WHILE, es lo que recibe el nombre de pseudo cursor. Si aplicamos esta técnica a la creación de la tabla numérica, nuestro código quedaría como vemos a continuación.
IF OBJECT_ID('Numeros','U') IS NOT NULL
BEGIN
DROP TABLE Numeros;
END
CREATE TABLE Numeros
(
NumeroID int NOT NULL
);
INSERT INTO Numeros (NumeroID)
SELECT
ROW_NUMBER() OVER(ORDER BY (SELECT NULL))
FROM sys.all_columns;
Aquí nos encontramos con una pequeña contrariedad: dado que la lista de números está limitada al número de filas de la tabla fuente (sys.all_columns en este caso) ¿qué podemos hacer si necesitamos crear una tabla numérica mayor? Una táctica sería recurrir al empleo de una tabla fuente con un mayor número de registros, pero si la tabla numérica a crear necesita un rango de valores muy elevado, puede que no dispongamos de una tabla fuente lo bastante grande, por lo que una técnica más recomendable consiste en hacer una CROSS JOIN de la tabla fuente consigo misma de la siguiente manera.
IF OBJECT_ID('Numeros','U') IS NOT NULL
BEGIN
DROP TABLE Numeros;
END
CREATE TABLE Numeros
(
NumeroID int NOT NULL
);
DECLARE @dtInicio AS DATETIME;
DECLARE @dtFin AS DATETIME;
SET @dtInicio = CURRENT_TIMESTAMP;
INSERT INTO Numeros (NumeroID)
SELECT
ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS Num
FROM sys.all_columns AS tbl1
CROSS JOIN sys.all_columns AS tbl2
ORDER BY Num
OFFSET 0 ROWS
FETCH FIRST 30000 ROWS ONLY;
SET @dtFin = CURRENT_TIMESTAMP;
SELECT DATEDIFF(millisecond,@dtInicio,@dtFin);
ALTER TABLE Numeros
ADD CONSTRAINT PK_Numeros
PRIMARY KEY (NumeroID);
Dado que el producto cartesiano de la tabla sys.all_columns al hacer la CROSS JOIN proporciona un número de filas abundante (71.453.209 en mi caso), y que gracias a los modificadores OFFSET…FETCH de la cláusula ORDER BY controlamos la cantidad de registros generados para la tabla numérica, se podría decir que esta técnica abarca prácticamente todas las situaciones que podamos necesitar.
Si la versión de SQL Server con la que trabajamos no soporta el uso de OFFSET…FETCH, emplearemos la cláusula TOP para limitar el número de filas devueltas por la consulta.
.......... .......... INSERT INTO Numeros (NumeroID) SELECT TOP (30000) ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) FROM sys.all_columns AS tbl1 CROSS JOIN sys.all_columns AS tbl2; .......... ..........
Y llegados a este punto finalizamos la primera parte de este artículo en donde hemos realizado una introducción a las tablas numéricas auxiliares tanto en el aspecto conceptual como en su forma de creación. En la segunda entrega continuaremos profundizando en las técnicas de construcción de este tipo de tabla, las cuales pueden resultar de gran ayuda al desarrollador de bases de datos para resolver problemas de muy diverso tipo.
Referencias
[1] Jeff Moden. «The «Numbers» or «Tally» Table: What it is and how it replaces a loop». http://www.sqlservercentral.com/articles/T-SQL/62867/
[2] Itzik Ben-Gan. «Microsoft SQL Server 2012 T-SQL Fundamentals». http://blogs.msdn.com/b/microsoft_press/archive/2012/07/16/new-book-microsoft-sql-server-2012-t-sql-fundamentals.aspx
[3] Jeff Moden. «Hidden RBAR: Counting with Recursive CTE’s». http://www.sqlservercentral.com/articles/T-SQL/74118/


anonymous
En la primera parte de este artículo explicábamos en qué consiste una tabla numérica
anonymous
Después de los artículos dedicados a la creación de tablas numéricas auxiliares
anonymous
Después de explicar en el anterior artículo el modo de creación de tablas de dimensión
anonymous
Como continuación al conjunto de artículos dedicados a la aplicación práctica
anonymous
Una de las operaciones a las que con mayor frecuencia se enfrenta cualquier desarrollador de bases de
anonymous
Tal y como apuntábamos al finalizar la primera parte del artículo, en esta segunda entrega