
La creación de datos de prueba representa una situación a la que muy probablemente nos habremos enfrentado en algún momento durante la construcción de un sistema de inteligencia de negocio (BI), bien porque los datos de la organización destinataria del proyecto no estaban disponibles, la calidad del conjunto de datos de prueba no era la adecuada, su volumen era insuficiente, etc.
Y es este último supuesto, el volumen de los datos a tratar, el que utilizaremos como argumento en el presente y próximos artículos sobre generación aleatoria de fechas, para abordar una serie de técnicas en las que emplearemos SQL Server como herramienta de desarrollo para la tabla de hechos de un modelo de datos de gran volumen.
El Padrón de habitantes del INE como fuente de datos
Al igual que en el artículo de introducción a Power BI publicado en este blog, también aquí emplearemos los archivos de microdatos relativos al Padrón de habitantes del Instituto Nacional de Estadística (INE), en esta ocasión el correspondiente al año 2017.
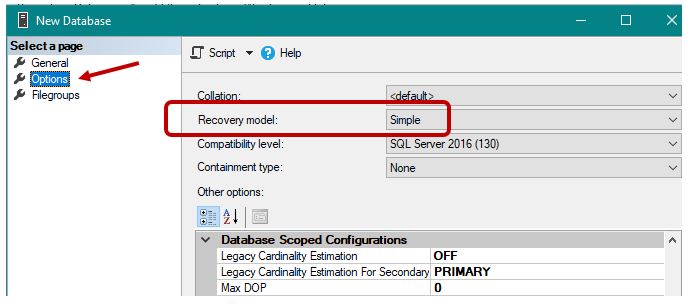
Una vez descargados y descomprimidos, tanto el archivo de texto plano con los datos de población, como el Excel con el diseño de registro, desde SQL Server Management Studio crearemos una base de datos llamada FechasAleatorias. Con el fin de optimizar el tamaño del registro de transacciones durante las diversas operaciones de carga de sus tablas, en el asistente de creación (apartado Options) estableceremos el modelo de recuperación a Simple.
Creada la base de datos, desde el editor de consultas crearemos la tabla INEPadronOrigen, sobre la que volcaremos el contenido del archivo de texto (micro_2017.txt) del Padrón de habitantes en su formato original mediante la instrucción BULK INSERT, a la que deberemos especificar en su cláusula FROM la ruta y nombre del archivo a cargar. Como resultado obtendremos una tabla con algo más de 46 millones de registros.
DROP TABLE IF EXISTS INEPadronOrigen; CREATE TABLE INEPadronOrigen ( Datos varchar(25) NULL ); --////// BULK INSERT INEPadronOrigen FROM 'F:\DatosOrigen\INE\micro_2017.txt'; --////// SELECT COUNT(*) FROM INEPadronOrigen; ----> 46572132
Optimizando los tiempos de carga de las tablas
La ejecución de las anteriores sentencias en una máquina dotada de un procesador i5, a 3.40GHz, con 32 GB de RAM, sobre SQL Server 2016 de 64 bits, es llevada a cabo en un plazo de 9 minutos 48 segundos (estos tiempos variarán en función de la configuración que el lector tenga en su sistema), y produce un notable aumento en el log de transacciones de la base de datos.

A pesar de que estamos manejando un elevado volumen de registros, podemos mejorar tanto el tiempo de carga de la tabla, como evitar que el log de transacciones crezca de forma desmesurada, aplicando para ello la sugerencia de tabla (table hint) TABLOCK a la sentencia BULK INSERT.
En primer lugar, reduciremos el registro de transacciones con la instrucción DBCC SHRINKFILE.
DBCC SHRINKFILE(FechasAleatorias_log, 1);
Y a continuación volveremos a ejecutar BULK INSERT incluyendo TABLOCK.
BULK INSERT INEPadronOrigen FROM 'F:\DatosOrigen\INE\micro_2017.txt' WITH (TABLOCK);
Con este simple cambio, la sentencia pasa a ejecutarse en tan solo 38 segundos, mientras que el tamaño del log de transacciones resultante tras la operación es mucho menor.

Identificación de los campos de la fuente de datos original
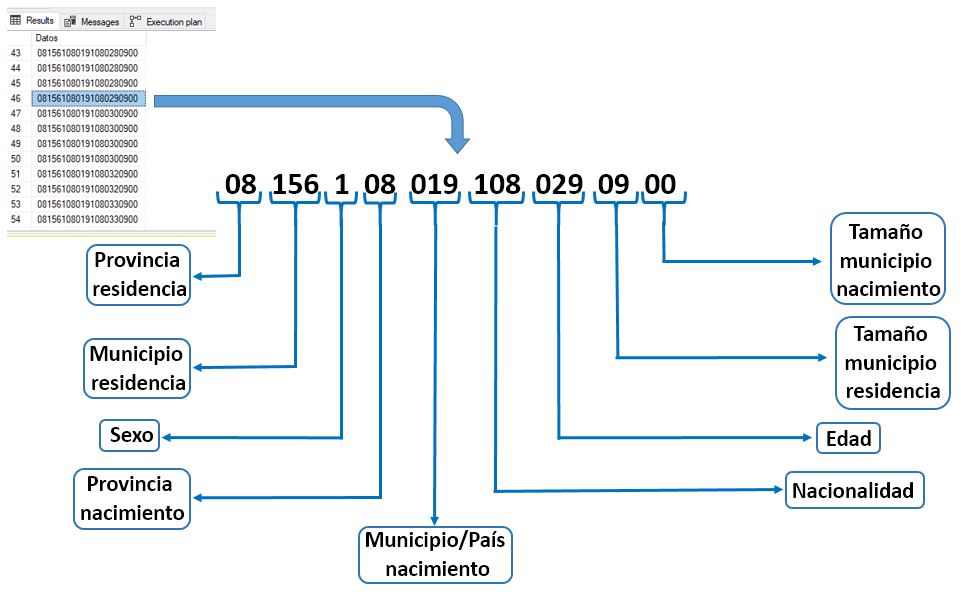
Cada registro de la tabla INEPadronOrigen representa, convenientemente anonimizado, a un individuo de los que conforman el Padrón de población, donde las diferentes posiciones y longitudes de la cadena de valores numéricos contenida en el registro identifican atributos de la persona tales como la edad, lugar de residencia, sexo, nacionalidad, etc. Toda esta información acerca del diseño de registro se recoge en el archivo Excel descargado anteriormente.

Tomemos un registro cualquiera de la tabla INEPadronOrigen, y siguiendo la información contenida en la hoja Diseño de este archivo Excel, los campos identificativos del individuo quedarán repartidos como muestra el siguiente esquema.
Carga de datos en la tabla destino
Esta nueva disposición de los datos requiere igualmente una nueva tabla, que llamaremos INEPadron, y que crearemos mediante la siguiente sentencia. El último campo, Fecha, lo reservaremos para almacenar la fecha que generaremos aleatoriamente más adelante.
CREATE TABLE INEPadron ( ProvinciaResidenciaID varchar(2) NULL, MunicipioResidenciaID varchar(5) NULL, SexoID int NULL, ProvinciaNacimientoID varchar(2) NULL, MunicipioPaisNacimientoID varchar(5) NULL, NacionalidadID varchar(3) NULL, Edad int NULL, TamMunicipioResidenciaID varchar(2) NULL, TamMunicipioNacimientoID varchar(2) NULL, Fecha date NULL );
Antes de comenzar con las pruebas de generación aleatoria de fechas, realizaremos una carga de datos en la tabla INEPadron a partir de los registros de INEPadronOrigen.
Empleando como guía el archivo Excel con el diseño de registro, escribiremos la siguiente sentencia, mediante la que distribuimos convenientemente los datos de la tabla de origen para volcarlos en las columnas de la tabla destino. Seguimos utilizando TABLOCK para reducir los tiempos de ejecución y el tamaño del registro de transacciones.
INSERT INTO INEPadron WITH (TABLOCK) ( ProvinciaResidenciaID, MunicipioResidenciaID, SexoID, ProvinciaNacimientoID, MunicipioPaisNacimientoID, NacionalidadID, Edad, TamMunicipioResidenciaID, TamMunicipioNacimientoID ) SELECT SUBSTRING(Datos,1,2), SUBSTRING(Datos,1,2) + IIF( LEN(SUBSTRING(Datos,3,3)) = 0, '999', SUBSTRING(Datos,3,3) ), CONVERT(int,SUBSTRING(Datos,6,1)), SUBSTRING(Datos,7,2), SUBSTRING(Datos,7,2) + IIF( LEN(SUBSTRING(Datos,9,3)) = 0, '999', SUBSTRING(Datos,9,3) ), SUBSTRING(Datos,12,3), CONVERT(int,SUBSTRING(Datos,15,3)), SUBSTRING(Datos,18,2), SUBSTRING(Datos,20,2) FROM INEPadronOrigen;
La ejecución de la siguiente sentencia se completa en 1 minuto y 15 segundos, lo cual es un excelente tiempo dado el elevado volumen de registros a cargar en la tabla. Sin embargo, podemos mejorar todavía más estos tiempos, si en el momento de crear la tabla agregamos a la misma un índice de tipo almacén de columnas (columnstore index). Vamos para ello a repetir el proceso de creación y carga de la tabla incluyendo el mencionado índice.
--eliminar la tabla DROP TABLE IF EXISTS INEPadron; --crear de nuevo la tabla CREATE TABLE INEPadron ( .... .... ); --creación del índice columnstore en la tabla CREATE CLUSTERED COLUMNSTORE INDEX ix_INEPadron ON INEPadron; --cargar la tabla INSERT INTO INEPadron WITH (TABLOCK) ( .... ....
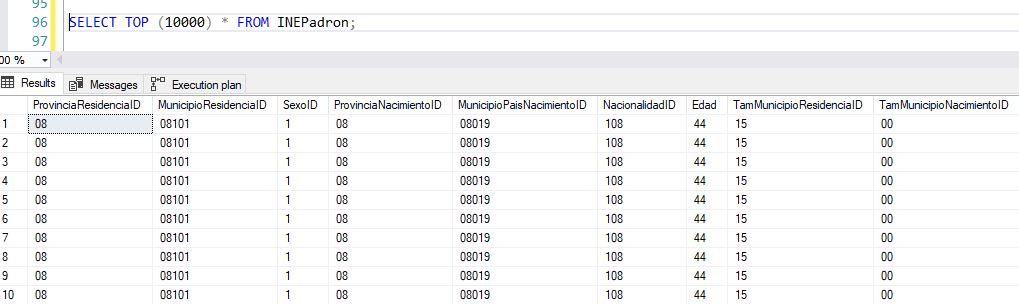
Mediante esta técnica, la carga de la tabla INEPadron se realiza en 37 segundos, superando los tiempos conseguidos en la sentencia inicial que realizaba la misma operación. La siguiente figura ofrece una muestra de las filas recién cargadas.
Elección de la estrategia de generación aleatoria de fechas
Entre las técnicas de creación de fechas para nuestro proceso de carga de la tabla INEPadron, vamos a elegir una consistente en generar un número aleatorio identificativo del día del año, comprendido por lo tanto entre 1 y 365 (366 si es año bisiesto), posteriormente convertiremos este valor en una fecha.
Si hablamos de generación aleatoria de números en SQL Server, con toda seguridad pensaremos en utilizar la función RAND. Los inconvenientes, no obstante, que dentro de nuestro escenario plantea RAND, radican en que el valor que devuelve es un número de tipo float, mientras que nosotros necesitamos un tipo int. Por otra parte, dicho valor será el mismo para todas las filas devueltas por una misma sentencia. Expliquemos este comportamiento con un ejemplo.
Mediante la siguiente sentencia obtenemos un muestreo de filas sobre algunas columnas de la tabla INEPadron, ejecutando adicionalmente la función RAND para cada fila.
SELECT MunicipioResidenciaID, NacionalidadID, Edad, RAND() AS AleatorioRAND FROM INEPadron TABLESAMPLE (0.1 PERCENT);
Pero como hemos indicado, el valor proporcionado por RAND será el mismo para todas las filas devueltas por la sentencia.
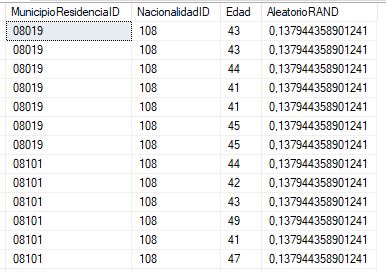
Ante tal resultado, podemos optar por la utilización de la técnica empleada por Jeff Moden en este artículo, basada en el uso combinado de las funciones NEWID, CHECKSUM y ABS.
En el siguiente bloque de código utilizamos, en primer lugar, una expresión de tabla (Common Table Expression), para que RAND y NEWID generen sus respectivos valores; mientras que en la consulta externa sobre la expresión de tabla aplicamos CHECKSUM y ABS para generar el número. Esto nos permite observar que NEWID devuelve un valor distinto cada vez que es ejecutado, y el número en el que lo convertimos.
WITH cteDatos AS ( SELECT MunicipioResidenciaID, NacionalidadID, Edad, RAND() AS AleatorioRAND, NEWID() AS AleatorioNEWID FROM INEPadron TABLESAMPLE (0.1 PERCENT) ) SELECT *, ABS(CHECKSUM(AleatorioNEWID)) AS AleatorioNEWID_CHECKSUM_ABS FROM cteDatos;

NEWID crea un valor de tipo uniqueidentifier distinto para cada una de las filas devueltas por la sentencia. Seguidamente pasamos ese uniqueidentifier a la función CHECKSUM, y esta realizará un cálculo que devolverá un número int positivo o negativo, por lo que a su vez pasaremos ese resultado a la función ABS, para asegurarnos de que todos los números sean positivos.
Sin embargo, la mayor parte de los números no estarán en el intervalo requerido de 1-365 (366). Para conseguirlo, dividiremos el número aleatorio obtenido entre la cantidad de días que tiene el año con el que estemos trabajando utilizando el operador módulo (%). Con este último número y la fecha de comienzo del año, calcularemos la fecha que necesitamos utilizando la función DATEADD.
TRUNCATE TABLE INEPadron; INSERT INTO INEPadron WITH (TABLOCK) ( ProvinciaResidenciaID, MunicipioResidenciaID, SexoID, ProvinciaNacimientoID, MunicipioPaisNacimientoID, NacionalidadID, Edad, TamMunicipioResidenciaID, TamMunicipioNacimientoID, Fecha ) SELECT SUBSTRING(Datos,1,2), SUBSTRING(Datos,1,2) + IIF( LEN(SUBSTRING(Datos,3,3)) = 0, '999', SUBSTRING(Datos,3,3) ), CONVERT(int,SUBSTRING(Datos,6,1)), SUBSTRING(Datos,7,2), SUBSTRING(Datos,7,2) + IIF( LEN(SUBSTRING(Datos,9,3)) = 0, '999', SUBSTRING(Datos,9,3) ), SUBSTRING(Datos,12,3), CONVERT(int,SUBSTRING(Datos,15,3)), SUBSTRING(Datos,18,2), SUBSTRING(Datos,20,2), CONVERT(date,DATEADD(day,(ABS(CHECKSUM(NEWID())) % 365),'2017')) FROM INEPadronOrigen;
La función DATEADD devuelve un tipo datetime, pero la columna Fecha de la tabla INEPadron es de tipo date. Por este motivo, en el anterior bloque de código utilizamos la función CONVERT, para hacer la correspondiente conversión entre tipos.
En el caso de que estemos interesados en ejecutar este código para otros años de la población del Padrón de habitantes, podemos encapsularlo en un procedimiento almacenado, al que pasemos como parámetro el año a procesar. Mediante dicho parámetro, calculamos las fechas inicial y final del año, que empleamos en la función DATEDIFF para obtener el número de días que contiene el año.
CREATE PROCEDURE spGenerarFechasAleatorias @sAnualidad varchar(4) AS BEGIN DECLARE @dtFechaInicio AS date; DECLARE @dtFechaFin AS date; DECLARE @nNumDiasAnualidad AS int; SET @dtFechaInicio = @sAnualidad; SET @dtFechaFin = EOMONTH(@dtFechaInicio,11); SET @nNumDiasAnualidad = DATEDIFF(day,@dtFechaInicio,@dtFechaFin) + 1; TRUNCATE TABLE INEPadron; INSERT INTO INEPadron WITH (TABLOCK) ( ...... ...... Fecha ) SELECT ...... ...... CONVERT(date,DATEADD(day,(ABS(CHECKSUM(NEWID())) % @nNumDiasAnualidad),@dtFechaInicio)) FROM INEPadronOrigen; END ...... ...... --después de crear el procedimiento almacenado --lo ejecutamos mediante la siguiente sentencia EXECUTE spGenerarFechasAleatorias '2017';
El tiempo de ejecución de este código en el entorno de prueba que hemos preparado es de 41 segundos. La siguiente figura muestra la tabla resultante, con la columna de fechas aleatorias al final.

Análisis de resultados en Excel
Como siguiente paso resultaría interesante analizar la forma en la que se han distribuido los valores aleatorios, para lo que vamos a realizar un recuento de la cantidad de filas que se han asignado a cada fecha usando la siguiente sentencia.
SELECT Fecha, COUNT(*) AS Recuento FROM INEPadron GROUP BY Fecha ORDER BY Fecha
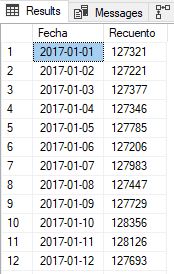
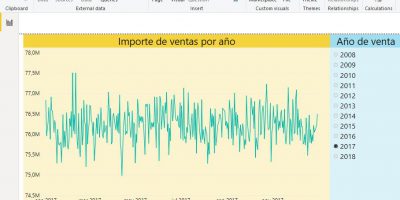
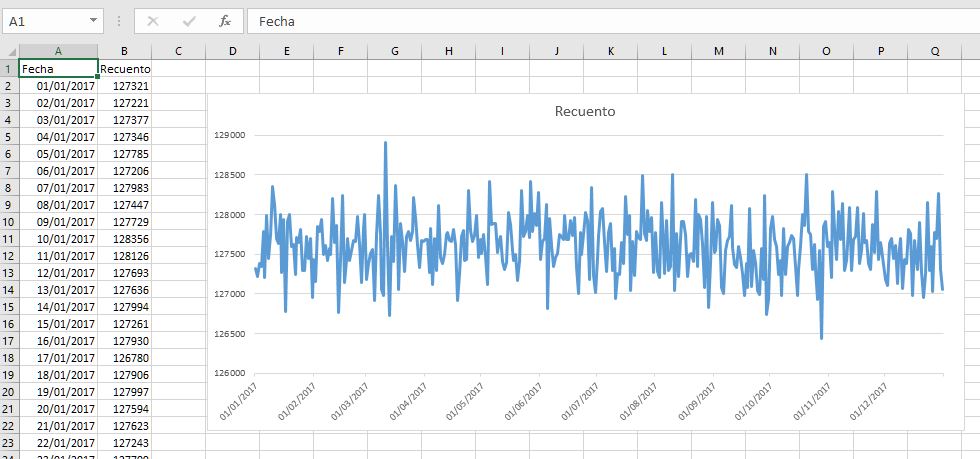
A continuación, copiaremos estos resultados y los pegaremos en un archivo Excel, creando con ellos un gráfico de línea, que nos ofrezca una imagen con la que analizar visualmente la evolución de las fechas.
Análisis de resultados en Power BI
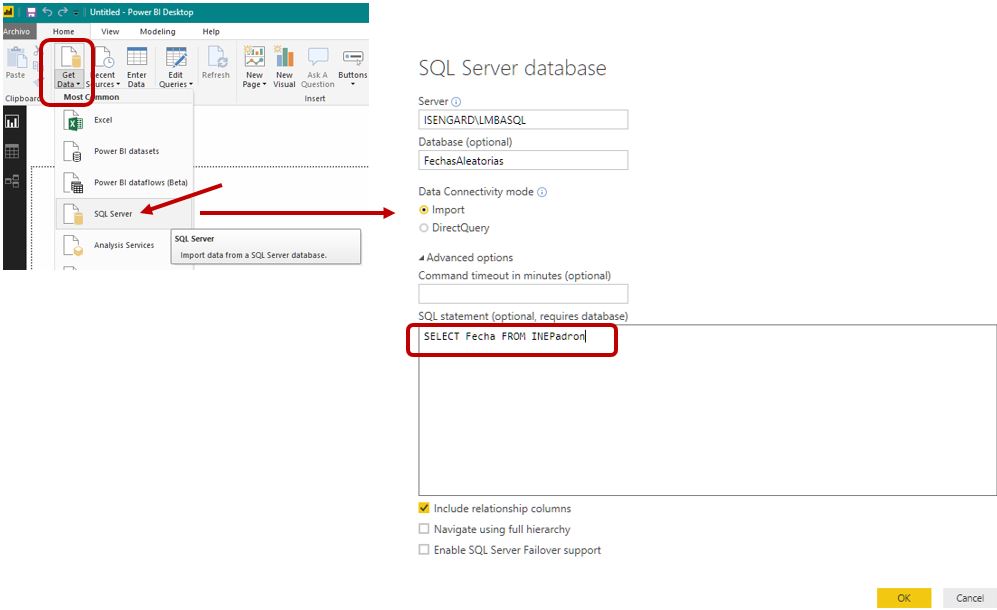
Una alternativa al anterior modo de presentación consistiría en desarrollar un modelo de Power BI conteniendo estos datos, para crear un informe con los mismos. Por lo que abriremos Power BI, y mediante la opción de menú Home > Get Data, del grupo de opciones External data, nos conectaremos a la base de datos en la que estamos desarrollando este ejemplo. Como solamente necesitamos analizar la columna Fecha de la tabla INEPadron, emplearemos la sentencia SQL de la siguiente figura para obtener las filas de dicha columna.
La siguiente ventana del asistente mostrará una previsualización de los datos. Haciendo clic en Load los cargaremos en nuestro archivo Power BI.
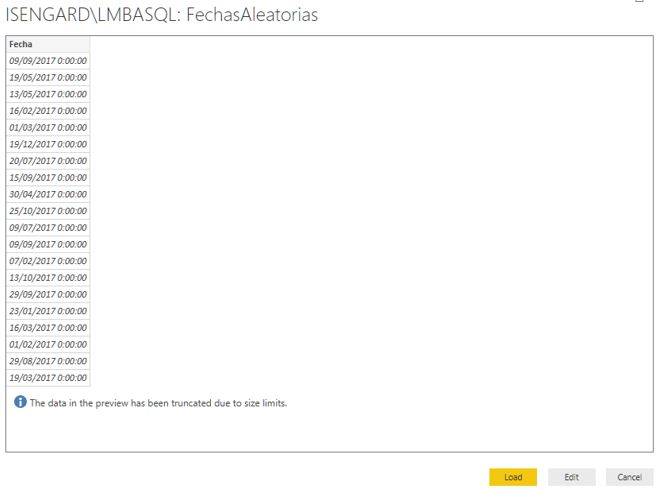
Tras la fase de importación, la opción de menú Home > Edit Queries dará paso a la ventana del editor de consultas, donde renombraremos la consulta existente a INEPadron. A continuación, haremos clic derecho en el nombre de la consulta seleccionando la opción Duplicate. Haciendo clic derecho en el duplicado, mediante la opción Rename cambiaremos su nombre por Fechas.
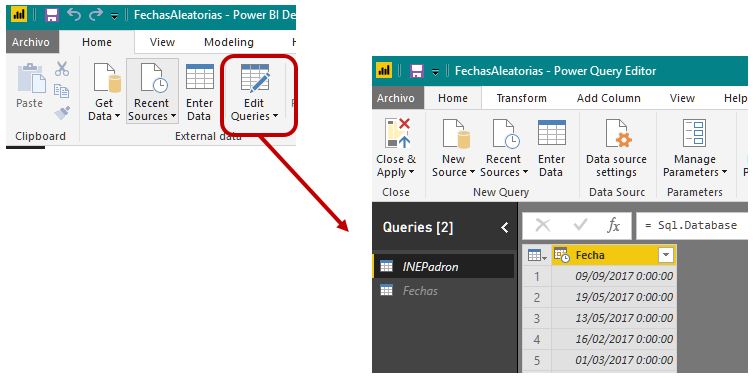
La consulta INEPadrón actuará como la tabla de hechos de un cubo, mientras que Fechas será la tabla de dimensión. Es por ello, que en la consulta Fechas solamente necesitamos los valores únicos de cada fecha. Haciendo clic en dicha consulta, ejecutaremos la opción de menú Home > Remove Rows > Remove Duplicates, del grupo de opciones Reduce Rows, para eliminar sus duplicados.

Guardaremos estos cambios haciendo clic en la opción Close & Apply, volviendo a la ventana principal de Power BI, donde estableceremos una relación entre ambas tablas del modelo en el diseñador Relationships.
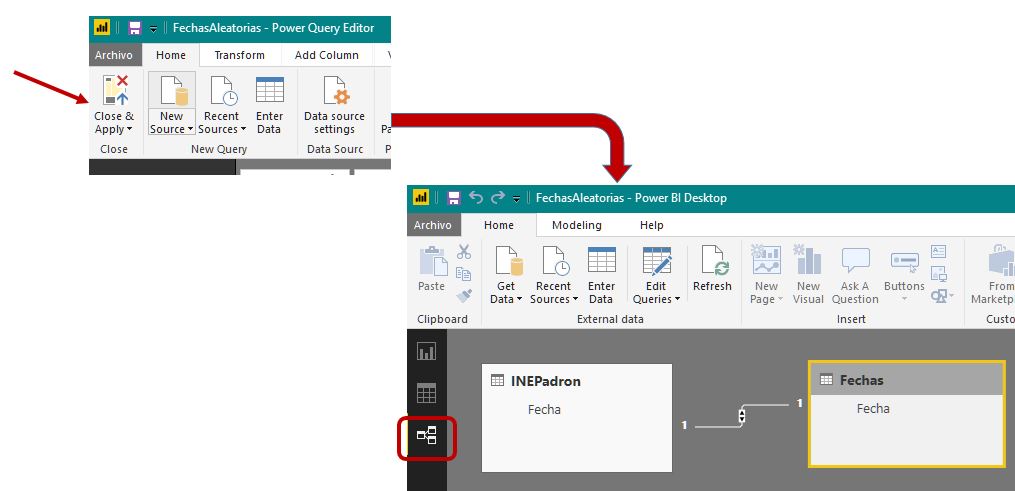
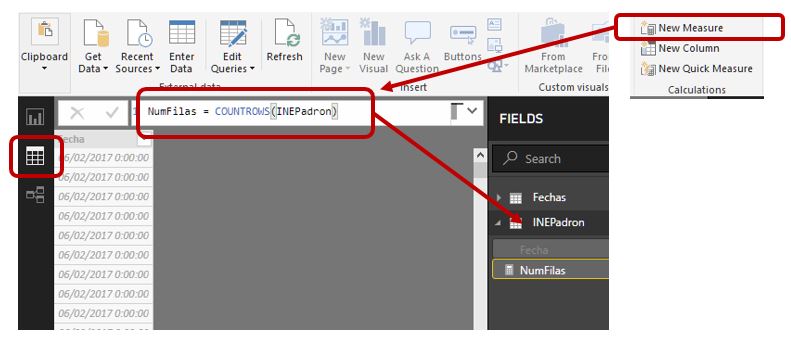
Como siguiente paso, en el diseñador Data crearemos una medida con el nombre NumFilas para la tabla INEPadron, que realice un recuento de sus filas, empleando la función COUNTROWS del lenguaje DAX.
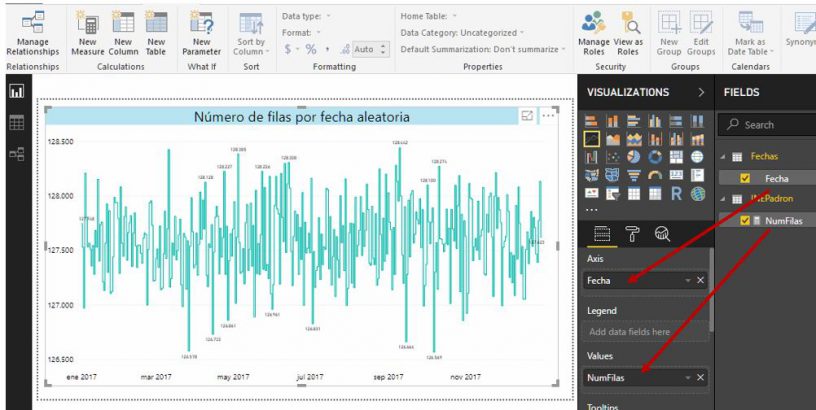
Finalmente, en el diseñador Report añadiremos un gráfico de línea, asignando la medida a la propiedad Values, y el campo Fecha de la tabla Fechas a la propiedad Axis. Con algunos retoques de formato, el informe tendrá la apariencia de la siguiente figura.
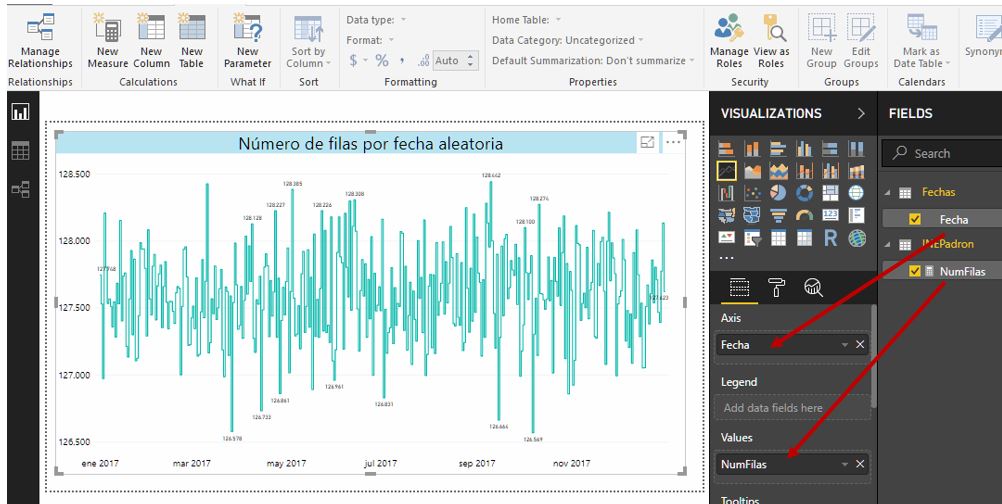
Aunque los resultados obtenidos por el lector serán diferentes de los nuestros, dicha diferencia no debería resultar significativa, por lo que la gráfica se parecerá bastante a la que acabamos de exponer. En nuestra tabla INEPadron, la cantidad máxima de fechas generadas para un día es de 128442, mientras que la mínima es de 126569. El número de fechas asignado por día se “mueve”, por tanto, en un intervalo de 1873, produciendo un gráfico con la forma que observamos en la figura anterior
Conclusiones
En este primer artículo sobre generación de fechas, hemos abordado una técnica basada en el uso combinado de las funciones NEWID, CHECKSUM y ABS, para generar un número aleatorio con el cual obtener una fecha. Aplicado este procedimiento sobre un conjunto de datos de más de 46 millones de registros, logramos unos tiempos de ejecución notablemente rápidos. En próximas entregas continuaremos trabajando en procesos de generación aleatoria de fechas, empleando otros tipos de algoritmo.
Agradecimientos
Quisiera expresar mi agradecimiento a María Dolores Esteban Vasallo y Ricard Gènova Maleras, integrantes del Servicio de Informes de Salud y Estudios (Subdirección de Epidemiología, Dirección General de Salud Pública, Consejería de Sanidad. CM) por toda la ayuda prestada acerca de conceptos sobre distribuciones estadísticas y demográficas, localización de fuentes de información y ánimos durante la elaboración de esta serie de artículos.
Referencias
Documentación SQL Server 2016: https://docs.microsoft.com/en-us/sql/index?view=sql-server-2016
INE (Instituto Nacional de Estadística): http://www.ine.es/
Jeff Moden (sqlservercentral.com): http://www.sqlservercentral.com/Authors/Articles/Jeff_Moden/80567/
DAX Guide: https://dax.guide/


Deja un comentario