
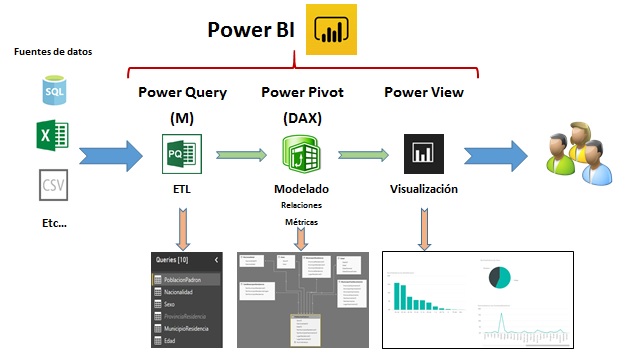
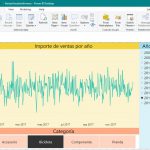
Desde su entrada en liza dentro de la arena de las herramientas de inteligencia de negocio, Power BI ha escalado rápidamente puestos dentro de este segmento del desarrollo de sistemas de análisis de datos y toma de decisiones, hasta situarse como una de las opciones más interesantes que existen actualmente gracias a un numeroso conjunto de cualidades, entre las que cabe destacar una poderosa capacidad de representación gráfica de la información residente en el modelo de datos, así como la integración en el producto de Power Query, el motor de extracción, transformación y carga (ETL) incluido también en Excel.
Precisamente, los mencionados procesos de limpieza y depuración de datos representan uno de los pilares principales de las fases que componen el desarrollo de un sistema de información, por lo que contar con una herramienta potente y versátil para realizar estas operaciones es fundamental. Power Query, gracias a su rica interfaz de usuario, que nos permite efectuar las más variadas operaciones de transformación y adaptación de los datos origen, confiere a Power BI una gran potencia en la preparación de los datos que posteriormente modelaremos mediante Power Pivot (DAX), para convertirlos en información accesible a través de cuadros de mando, informes, etc.
En la siguiente figura podemos ver una representación gráfica a grandes rasgos de las diferentes fases que constituyen el desarrollo de un sistema de información utilizando Power BI.
Y por si esto fuera poco, allá donde no podamos llegar con las operaciones disponibles en la interfaz de usuario, Power Query también nos ofrece la posibilidad de programar tareas a través de M, su lenguaje de fórmulas, lo que amplia considerablemente el abanico de opciones a nuestra disposición
El papel del self-service BI en el desarrollo de un DataWarehouse
Habitualmente se asocia el término self-service BI con la capacidad de que disponen ciertos usuarios de un DataWarehouse para conectarse al sistema, obtener un subconjunto de su información y analizarla de forma independiente al sistema principal, creando una estructura BI de menor tamaño focalizada en determinados aspectos de la principal.
Se trata de usuarios con perfil avanzado y gran conocimiento de la naturaleza de los datos manejados por el sistema, que junto a las herramientas adecuadas pueden analizar la información con un grado de precisión diferente al que normalmente requiere el grueso de usuarios finales.
Este tipo de usuario con frecuencia trabaja junto a los desarrolladores del DataWarehouse encargados del diseño y creación de las bases de datos, cubos (multidimensionales o tabulares), cuadros de mando, etc., ya que aporta información muy valiosa para la adecuada optimización de los procesos que intervienen en su creación, es por ello que disponer de herramientas self-service BI de calidad como Power BI contribuye a mejorar el resultado final del sistema de información.
Power Query. Mucho más que self-service BI
Desde su irrupción en el mercado BI, Power Pivot, Power View, y en última instancia, Power Query; todos ellos complementos (add-in) de Excel, se han presentado como herramientas self-service BI, destinadas a los usuarios avanzados anteriormente mencionados. Sin embargo la evolución y mejora en prestaciones de toda esta suite de complementos, y la posterior aparición de Power BI como integrador de todos ellos (motor analítico de Power Pivot, motor de visualización de Power View y motor de transformación de Power Query) en un único producto, los convierten no solamente en software para analistas de sistemas de información, sino también en herramientas muy útiles para los desarrolladores de dichos sistemas.
El objetivo del presente artículo consistirá en realizar una aproximación al desarrollo de un modelo de Power BI, centrándonos fundamentalmente en las operaciones de extracción, transformación y carga (ETL) que llevaremos a cabo mediante Power Query, pero prestando también atención al importante volumen de datos que podemos manejar mediante esta aplicación.
No se trata de explicar Power Query en todos sus detalles sino de hacer una introducción al mismo y a M, su lenguaje de programación, abordando algunas de las técnicas más comunes en el tratamiento de datos, que sirvan al lector como iniciación, al mismo tiempo que observamos la capacidad de gestión que posee trabajando con conjuntos de datos de varios millones de registros.
Se asume que el lector dispone de Power BI instalado en su máquina para poder seguir los ejemplos descritos; no obstante, en el siguiente enlace es posible realizar la descarga del instalador.
Padrón de habitantes. La fuente de datos origen
Como fuente del modelo que vamos a construir utilizaremos los datos disponibles en el Instituto Nacional de Estadística (INE) sobre la población inscrita en el Padrón de habitantes de los municipios de España.
El registro del Padrón Municipal está formado por la información relativa a los vecinos de las poblaciones que componen el territorio nacional, remitida por los diferentes ayuntamientos al INE, quien ofrece una versión anonimizada de esta información a los ciudadanos a través de los denominados ficheros de microdatos.
Cada uno de estos archivos, disponibles en la Estadística del Padrón continuo, contiene, en formato de texto plano, la información sobre la población registrada en España a 1 de enero de cada año, donde cada fila del archivo representa a un individuo.
Como acabamos de decir, estos datos se encuentran adecuadamente anonimizados para cumplir con la normativa de protección de datos, y entre los mismos podemos obtener el lugar de residencia y nacimiento por provincia, municipio y país, así como la edad, sexo y tamaño de municipio por número de habitantes.
Cumpliendo igualmente con los requisitos del INE respecto al uso de estos archivos, hemos de informar al lector que el grado de exactitud de la información elaborada en este artículo a partir de dichos archivos no depende ya del INE, sino en este caso de los procesos y operaciones llevados a cabo con Power BI (Power Query) como software empleado para realizar su explotación.
Para el ejemplo que vamos a desarrollar emplearemos el archivo correspondiente a los datos de la estadística a 1 de enero de 2016 (alrededor de 46 millones de registros), por ser los más recientes disponibles en el momento de la publicación de este artículo.
Una vez que hayamos accedido a la página de descarga haremos clic en el botón “Ir” para obtener el archivo de texto micro_2016.txt con los datos de población. También haremos clic en el enlace Diseño de registro y valores válidos de las variables, que nos proporcionará el archivo Diseño y valores de las variables del Fichero Microdatos Padron_2016.xlsx, conteniendo la guía del diseño de registro del fichero de población, así como los datos para alimentar las tablas de búsqueda o catálogos que emplearemos en el modelo: listado de provincias, municipios, países, etc. A partir de ahora nos referiremos a este archivo de forma abreviada como archivo Excel origen o Excel origen. Por cuestiones de espacio ambos archivos se descargan comprimidos en formato zip, siendo necesaria su posterior descompresión.
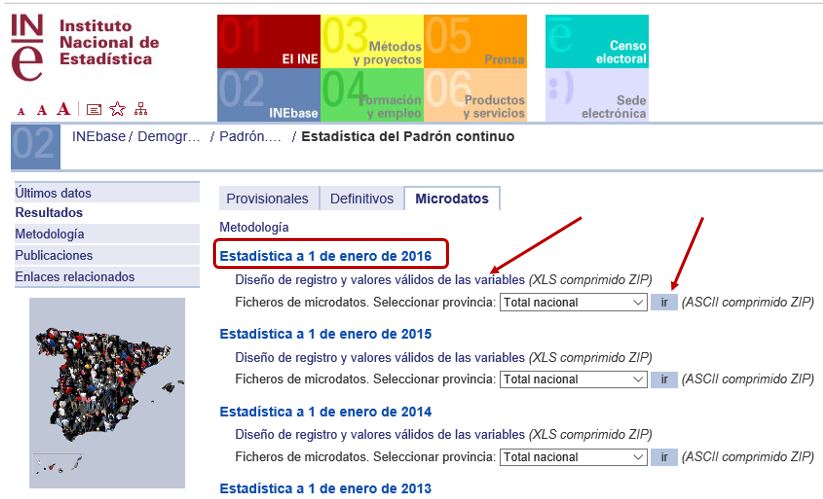
Diseño de registro del archivo de población
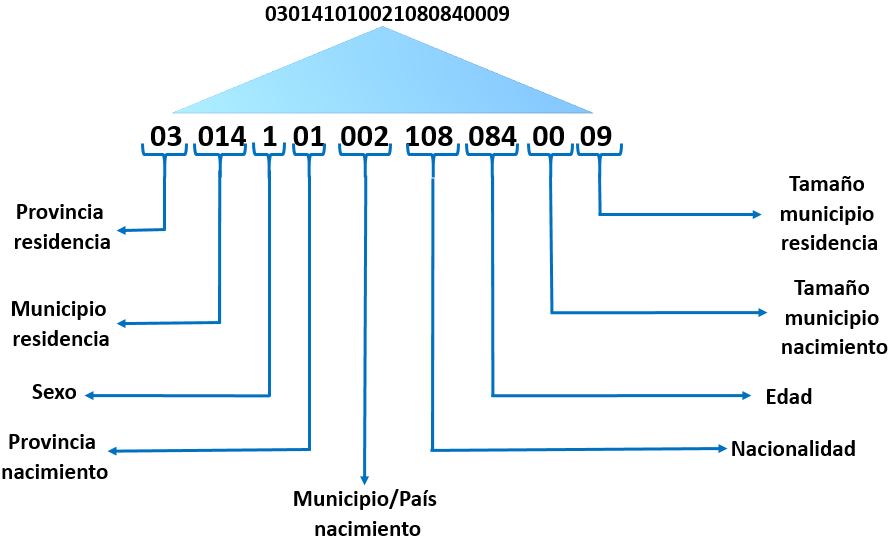
Como hemos avanzado anteriormente, cada fila del archivo de población contiene una cadena de dígitos con los datos de un individuo. En el siguiente ejemplo vemos una muestra aleatoria de una de estas filas.
030141010021080840009
Para extraer cada una de las partículas que identifican las diferentes propiedades de la persona utilizaremos como guía la hoja Diseño del archivo Excel origen, que nos muestra el significado y posiciones que le corresponden dentro de la cadena total de dígitos.

Utilizando estas indicaciones, la siguiente figura muestra un breve esquema de la distribución de los valores de cara al próximo proceso que implementaremos con Power Query, para segmentarlos de modo que cobren sentido en la posterior fase de modelado.
Importación de datos con Power BI
Llegamos por fin al momento de empezar con el trabajo de campo. En primer lugar ejecutaremos Power BI y seleccionaremos la opción Get Data del grupo External data, lo que mostrará una lista con los tipos de orígenes de datos más comunes, de los que elegiremos Text/CSV.

Seguidamente se abrirá un cuadro de diálogo en el que navegaremos hasta la ruta en la que hayamos depositado el archivo de datos de población micro_2016.txt. Después de seleccionarlo, Power BI mostrará una visualización previa de sus primeras filas.
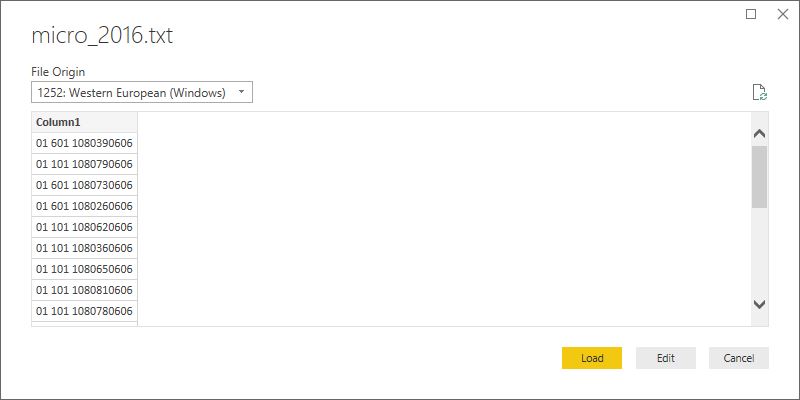
A continuación haremos clic en Edit, y con ello, Power BI cederá el paso al motor de Power Query, representado por la ventana del editor de consultas o Query Editor, que contendrá una consulta con los datos del archivo que acabamos de incorporar.
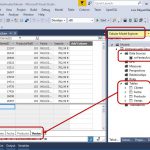
Query Editor. El entorno de desarrollo de Power Query
Query Editor será nuestra ventana principal de trabajo a lo largo del artículo y en ella resulta recomendable que nos familiaricemos con los elementos destacados en la siguiente figura.
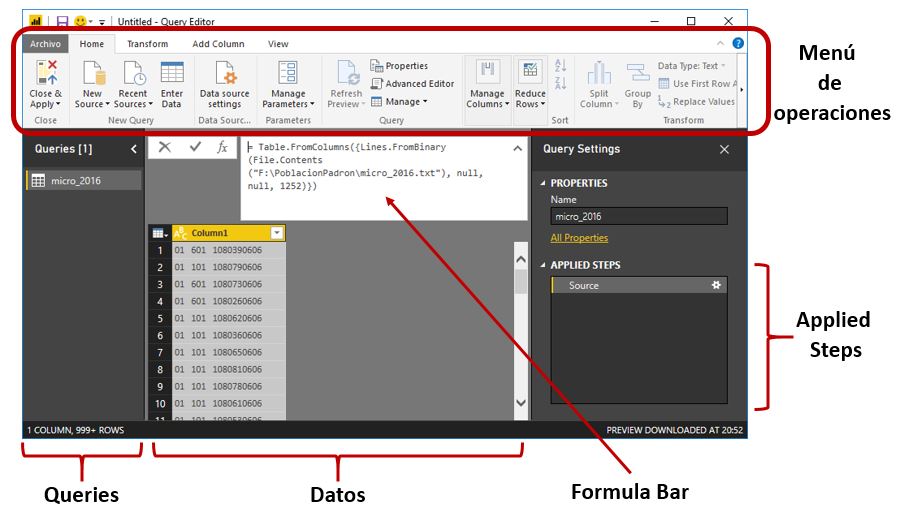
Queries. Panel contenedor de las consultas utilizadas en las operaciones de transformación de datos, que posteriormente serán empleadas como base en la construcción del modelo desde los diseñadores de Power BI. El término Query (consulta) sirve al Query Editor para identificar principalmente a tablas, listas de valores u otro tipo de objetos que almacenan datos de forma estructurada. El trabajo a desarrollar en el presente artículo va a estar enfocado principalmente al manejo de tablas, por lo que emplearemos ambos términos, consulta y tabla, para referirnos al mismo tipo de objeto: una estructura de datos organizados en filas y columnas.
Datos. Esta zona muestra el contenido de la consulta actualmente seleccionada en el panel Queries.
Applied Steps. Cada una de las operaciones que llevemos a cabo sobre una consulta representa un paso en el conjunto de transformaciones realizadas, quedando registrado con un nombre en este bloque del panel Query Settings. Esto nos permite situarnos en cualquiera de los pasos para revisar el estado que tenía la consulta en ese preciso instante, modificarlo, eliminarlo, etc., como si de una grabadora de macros se tratara.
Formula Bar. Expresión en lenguaje M correspondiente al paso actualmente seleccionado. En el caso de que este elemento no se encuentre visible lo activaremos marcando la casilla Formular Bar del grupo Layout en la pestaña View.
Menú de operaciones. Se trata de una impresionante caja de herramientas en donde encontraremos todo tipo de acción de depuración, limpieza, transformación, etc. que necesitemos aplicar a los datos. Tengamos también presente que si aquí no halláramos la solución que buscamos siempre está disponible la posibilidad de introducir nuestro propio código en lenguaje M.
Modificando los nombres predeterminados
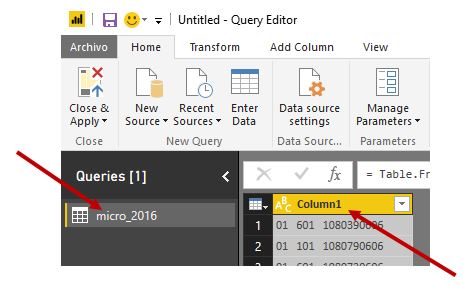
El archivo que acabamos de importar genera una consulta llamada micro_2016, que contiene una columna con el nombre Column1, ambas asignadas automáticamente en la operación de importación.
Aunque podemos utilizar estos nombres predeterminados en las siguientes tareas de transformación, vamos a cambiarlos por otros que sean más significativos de cara al resto de operaciones a realizar, ya que Power Query asigna nombres a todos los elementos de los procedimientos de transformación que su motor necesita tener identificados. Por ello resulta una buena práctica que en aquellos sobre los que tengamos que realizar alguna manipulación especial, tal como su empleo en una fórmula, les asignemos descriptores personalizados.
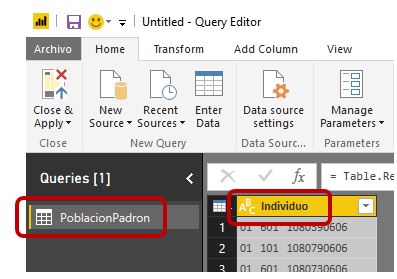
En el caso que actualmente nos atañe haremos clic derecho tanto en el nombre de la consulta como de la columna, seleccionando la opción Rename y modificando respectivamente sus nombres por PoblacionPadron e Individuo (pulsando F2 también conseguiremos el mismo resultado). PoblacionPadron representará a la futura tabla de datos del modelo que vamos a desarrollar.
Optimización de los tiempos de carga de datos
Llegados a este punto podemos actualizar el trabajo desarrollado hasta el momento en la ventana Query Editor sobre el modelo de datos de Power BI haciendo clic en la opción de menú Close & Apply, situada en el grupo Close.

En nuestro caso está operación puede suponer una importante penalización en tiempo de proceso debido al elevado volumen de datos contenidos en PoblacionPadron, ya que de manera predeterminada, todas las consultas del Query Editor se cargan en memoria para su posterior utilización en el modelo de datos de Power BI.
Como alternativa para poder trabajar con los datos sin necesidad de cargarlos realmente, haremos clic derecho en la consulta y seleccionaremos la opción Properties para abrir su ventana de propiedades. Una vez situados en ella desmarcaremos la casilla Enable load to report y aceptaremos los cambios; de esta manera mantenemos una referencia a los datos en su ubicación de origen sin incorporarlos hasta que no sea necesario, reduciendo por tanto los tiempos de proceso. El siguiente artículo de Reza Rad sobre cuestiones de rendimiento en Power BI aporta información adicional acerca de este particular.

Tras ejecutar la opción Close & Apply se cerrará la ventana Query Editor y volveremos a la ventana principal de Power BI, donde haremos clic en la opción de menú Archivo | Save para guardar el trabajo desarrollado hasta el momento en un archivo que llamaremos PoblacionPadron.pbix.
Creación de columnas a partir de los datos origen. Preparación de la tabla de datos
La siguiente tarea de la que nos ocuparemos será la división en columnas de los datos identificativos de cada individuo a partir de la columna existente en la tabla PoblacionPadron, siguiendo para ello las pautas de la hoja Diseño del archivo Excel origen.
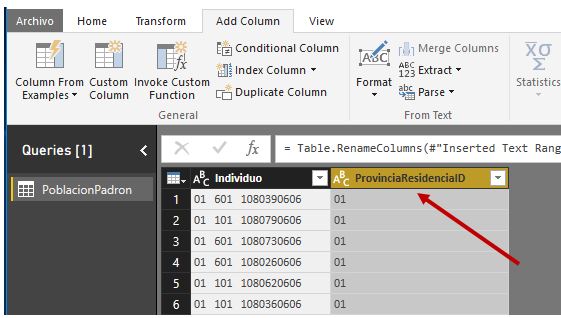
Comenzaremos por el código de provincia de residencia de la persona, que corresponde a los dos primeros dígitos de la columna Individuo.
En primer lugar haremos clic en la cabecera de la columna Individuo. A continuación, en la pestaña de menú Add Column, grupo From Text, seleccionaremos la opción Extract para obtener una subcadena de la columna, eligiendo Range como tipo de extracción.
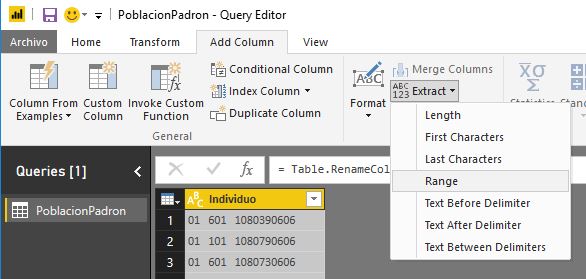
Como resultado de esta acción se abrirá un cuadro de diálogo donde en el parámetro Starting Index introduciremos 0. Este parámetro representa el índice de la posición a partir de la cual comenzará la extracción de la subcadena. Por otra parte, en el parámetro Number of Characters introduciremos 2 como cantidad de caracteres a obtener.
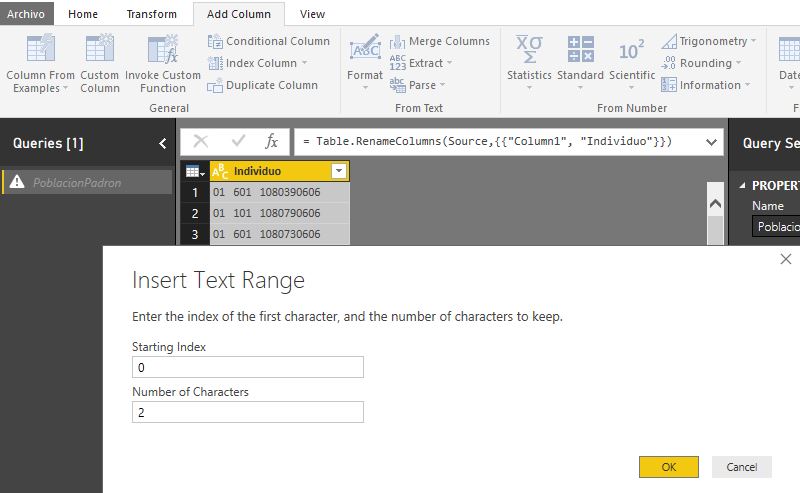
Aceptando este diálogo se creará una nueva columna con el código de provincia de residencia del individuo, a la que cambiaremos el nombre por ProvinciaResidenciaID.
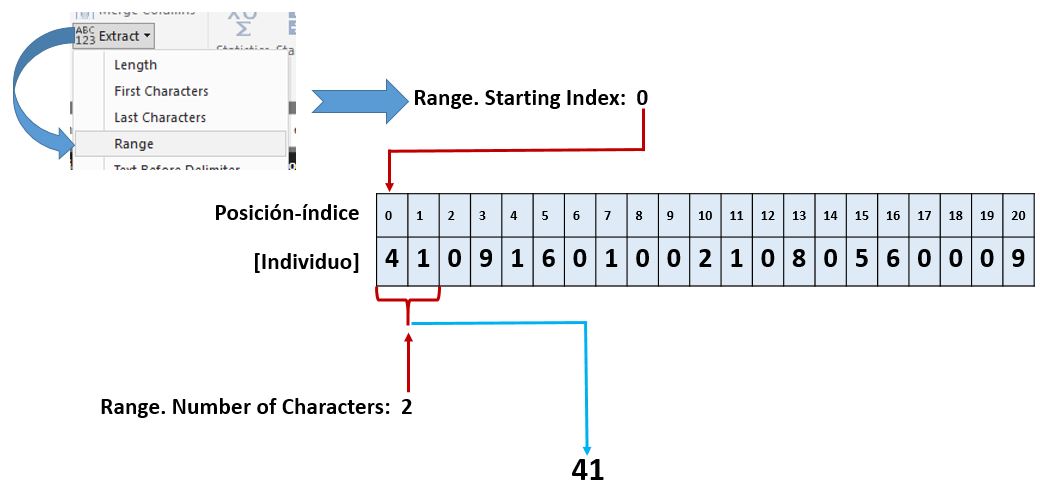
El motivo de utilizar 0 para indicar la posición de inicio de la extracción se debe a que Power Query trabaja con índices en base cero, lo que significa que el número de índice o posición del primer elemento es 0, el índice del segundo es 1 y así sucesivamente. En la siguiente figura se muestra de modo esquemático la operación que acabamos de realizar.
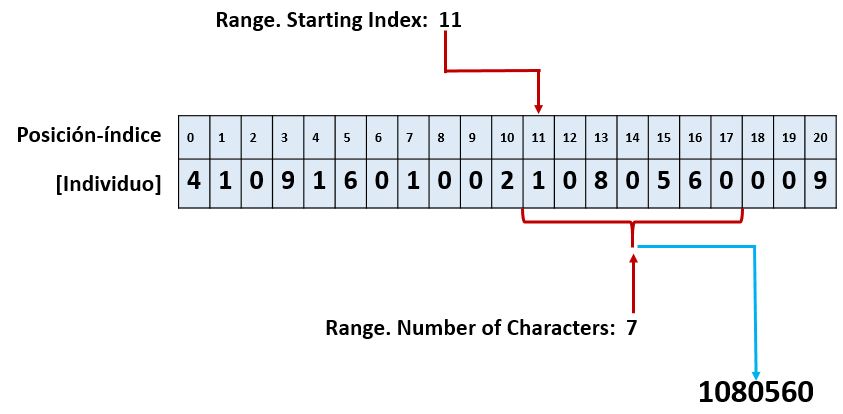
Si por ejemplo quisiéramos obtener, a partir de la cadena de la figura anterior, una subcadena de 7 caracteres empezando por la posición 12, los valores a utilizar serian 11 para el índice de comienzo de la extracción, y 7 para el número de caracteres a recuperar. A continuación volvemos a mostrar el esquema de ejecución para esta operación.
La función del lenguaje M que internamente ejecuta la opción de menú Extract-Range es Text.Range, cuya utilización abordaremos en ejemplos posteriores. En el siguiente bloque de código vemos la extracción de las anteriores subcadenas, pero utilizando esta función que acabamos de mencionar.
Text.Range([Individuo],0,2) Text.Range([Individuo],12,7)
Teniendo en cuenta las consideraciones que acabamos de explicar, para aquellas operaciones relacionadas con la manipulación de cadenas de caracteres, será necesario restar 1 a las posiciones de la cadena con la que necesitemos trabajar, para hacerlas coincidir con el índice que internamente utiliza Power Query en las funciones de tratamiento de texto.
Columna con valor basado en una condición
El código de municipio de residencia es la siguiente columna que vamos a añadir a la tabla, encontrándose su valor situado en las posiciones 3, 4 y 5 de la columna Individuo.
Adicionalmente hemos de tener en cuenta que para aquellos municipios con población inferior a 10000 habitantes este valor está blanqueado (cadena vacía) por cuestiones de protección de datos. Puesto que como veremos más adelante, la forma de identificar un municipio se basa en la unión de los códigos de provincia más municipio, para los casos en que este último no esté disponible utilizaremos un código que no exista previamente como 999, más adecuado en esta circunstancia que una cadena vacía, ya que proporcionará mayor consistencia a los datos en la fase de creación del modelo posterior a las transformaciones que actualmente estamos llevando a cabo con Power Query.
Revisando en la ventana Query Editor las opciones de menú de la pestaña Add Column, advertiremos la existencia de la opción Conditional Column, mediante la que podemos crear una columna basada en una o varias condiciones. Sin embargo entre los operadores disponibles no existe ninguno que nos permita extraer una subcadena por posiciones.
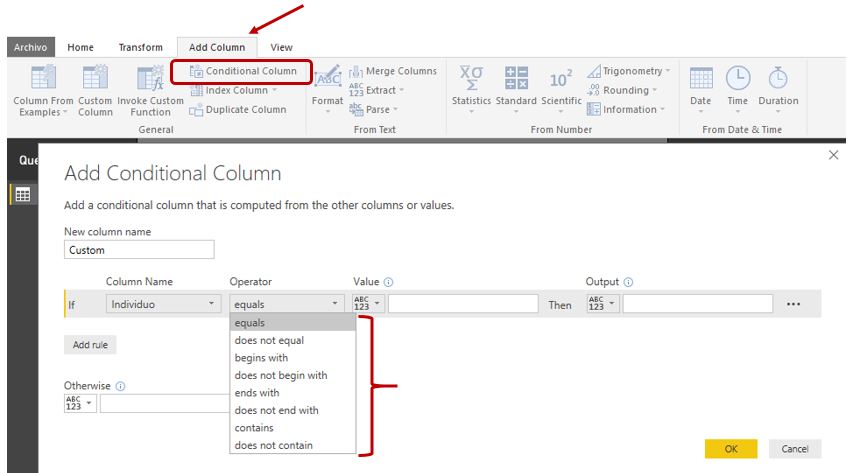
Esto nos lleva a buscar la solución en la opción Custom Column, también situada en la pestaña de menú Add Column, que como su nombre indica, posibilita la creación de una columna personalizada mediante la introducción de una expresión escrita en lenguaje M.
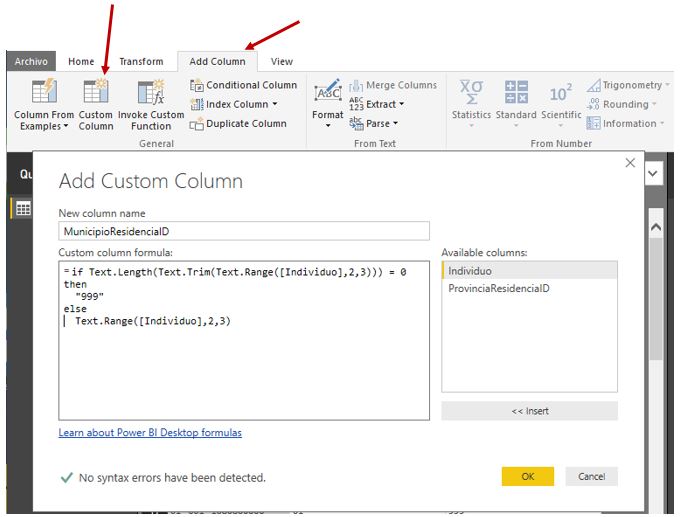
if Text.Length(Text.Trim(Text.Range([Individuo],2,3))) = 0 then "999" else Text.Range([Individuo],2,3)
En el anterior bloque de código utilizamos la estructura de decisión if…then…else y funciones pertenecientes a la categoría Text para comprobar si existe valor en la subcadena de 3 caracteres que empieza en el índice 2. Nótese que en un caso como el actual, donde ejecutamos varias funciones de forma anidada, el orden de evaluación de las mismas comienza por la que está situada en la posición más interior continuando hacia el exterior, tal y como explicamos seguidamente.
En primer lugar extraemos la subcadena mediante la función Text.Range, después eliminamos los espacios en blanco que pudiera haber con la función Text.Trim, y comprobamos la longitud resultante con la función Text.Length; si esta es 0 (cadena vacía) se trata de uno de los municipios blanqueados, por lo que devolvemos como resultado la cadena 999 (como delimitador de cadenas se utiliza el carácter de comilla doble); en caso contrario, es un municipio con valor y devolvemos la subcadena correspondiente a su código mediante Text.Range.
Para el resto de columnas pendientes de crear seguiremos empleando la opción de menú Custom Column, ya que en todos los casos necesitaremos extraer una subcadena de la columna Individuo.
Atención a las mayúsculas y minúsculas en M
Ahora que ya hemos comenzado a escribir código M hemos de ser precavidos al crear nuestras expresiones, debido a la distinción entre mayúsculas y minúsculas que este lenguaje hace entre sus elementos, tales como palabras reservadas, nombres de funciones, etc.
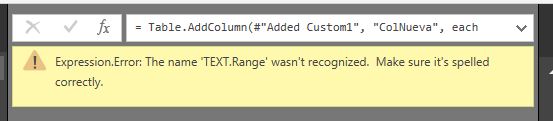
Si por ejemplo intentamos crear una nueva columna con la siguiente expresión.
TEXT.Range([Individuo],2,3)
Al haber escrito el nombre de la categoría de función TEXT en mayúsculas en lugar de Text, que sería la forma correcta, obtendríamos el error que vemos en la siguiente figura.
¿Cómo encuentro la función más adecuada para cada momento? La respuesta está en el interior
M es un lenguaje compuesto por funciones, que organizadas en categorías (Table, Text, Number, List, etc.) ofrecen un amplio espectro de posibilidades para el manejo de tablas, listas, cadenas de caracteres, etc.
Pero ante tal oferta necesitamos algún tipo de documentación para buscar la que mejor se adapte a nuestros requisitos en cada situación.
Como recursos en Internet disponemos de la página de referencia oficial de Microsoft, desde la que podemos descargar un documento con las especificaciones del lenguaje. Para las funciones existe igualmente una página en la que se encuentran agrupadas por categoría, y también podemos encontrar multitud de sitios dedicados no solo a Power Query, sino también a Power BI, Power Pivot y resto de tecnologías Microsoft BI, de los que al final del artículo se proporcionan algunos enlaces destacados.
Sin embargo, todos los anteriores recursos se basan en nuestra disponibilidad de una conexión a Internet, pero ¿qué ocurre si por determinadas circunstancias no podemos conectarnos a la Red?
Esta situación no debe preocuparnos, ya que desde el propio Power Query podemos acceder a información sobre las funciones del lenguaje M mediante un pequeño truco.
En primer lugar crearemos una nueva consulta mediante la opción New Source | Blank Query, situada en el menú Home, grupo New Query.
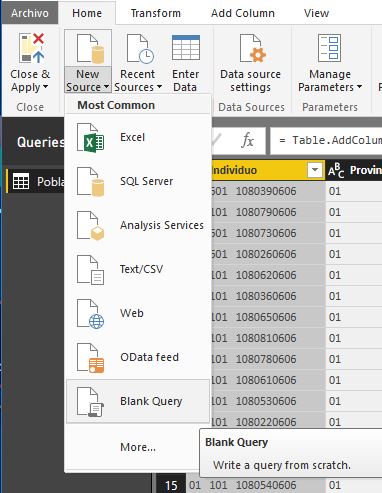
Una nueva consulta con el nombre por defecto Query1 será creada. En la barra de fórmulas escribiremos la siguiente expresión.
= #shared
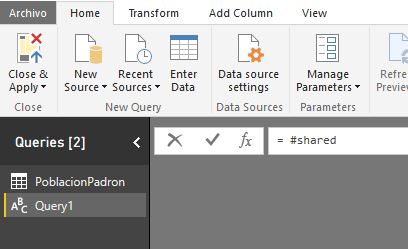
Tras pulsar Enter se generará un conjunto de resultados compuesto por registros (objetos Record) conteniendo las funciones del lenguaje, así como tipos (types), valores constantes, etc. Para poder manejar más cómodamente este listado haremos clic en la opción de menú Into Table, del grupo Convert, perteneciente a las pestañas Record Tools | Convert, para convertirlo en una consulta de tipo tabla.
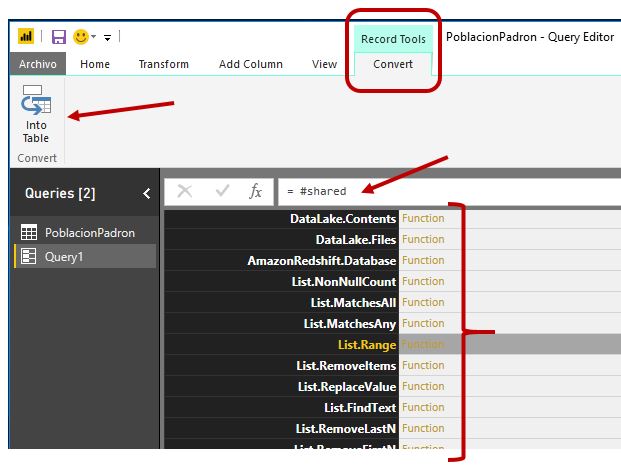
Una vez obtenida la tabla podemos buscar información sobre las funciones mediante la aplicación de un filtro sobre la columna Name. Por ejemplo, si queremos ver únicamente las funciones de la categoría Text, haremos clic en el botón de filtro/orden de dicha columna, introduciremos el valor Text. (incluyendo el punto para delimitar mejor la búsqueda), y haremos clic en OK.
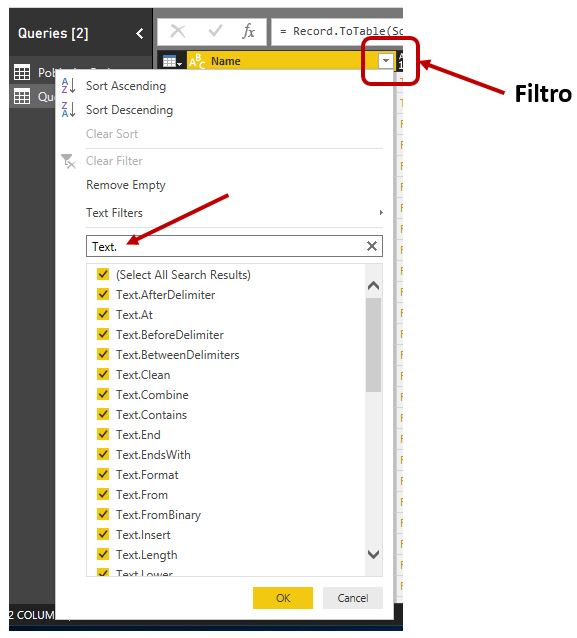
Como resultado, la tabla mostrará los nombres de las funciones filtradas. Podemos volver a abrir este cuadro de filtro y aplicar un orden ascendente.
Pero si la ayuda se quedara solamente en un listado de las funciones, esta utilidad resultaría poco práctica. Vamos pues a buscar en esta lista una de las funciones que hemos utilizando previamente: Text.Range, y en la columna Value haremos clic pero no en el valor Function sino en un espacio vacío dentro de dicha casilla. Se abrirá entonces un panel en la parte inferior de la ventana con información detallada acerca de la función seleccionada: signatura (parámetros y retorno con sus tipos correspondientes), descripción de la operación que realiza y ejemplos de uso.
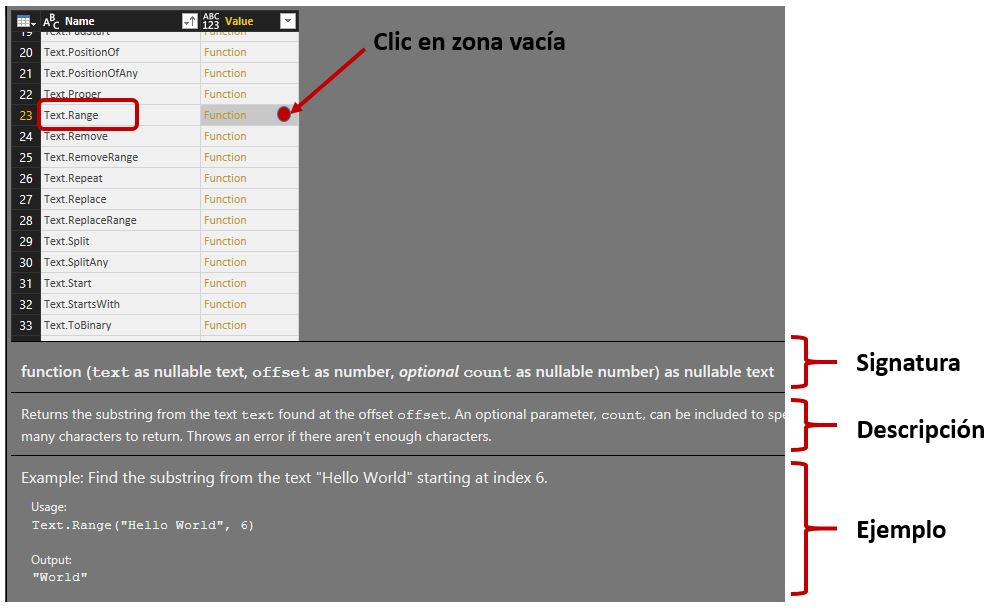
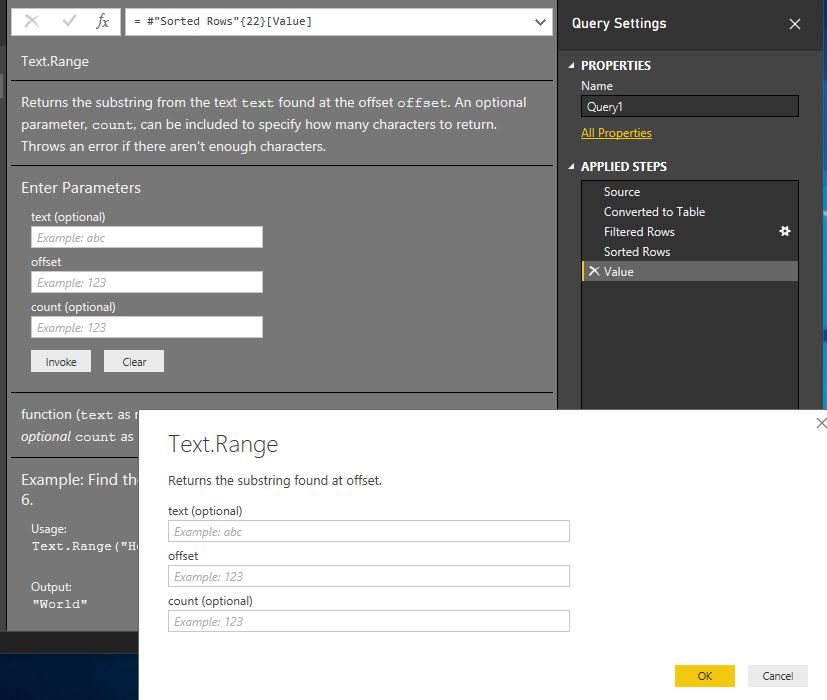
Si volvemos a hacer clic, esta vez en el valor Function, se ampliará la información sobre la función, abarcando toda la ventana y abriendo la caja de diálogo de interacción con el usuario para que podamos evaluar su funcionamiento.
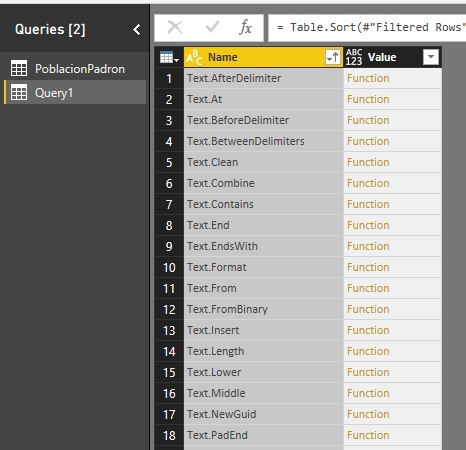
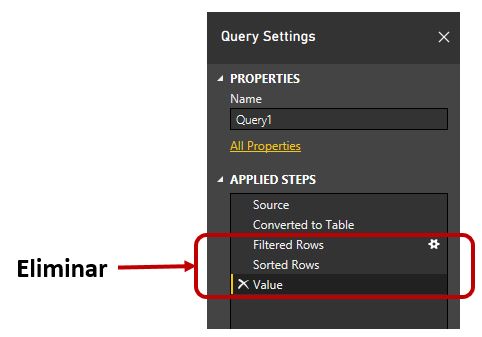
También podemos utilizar otras variantes de filtro como la búsqueda de funciones que contengan una subcadena concreta dentro de su nombre. En primer lugar vamos a eliminar en el panel Applied Steps los últimos pasos creados hasta quedarnos en Converted to Table. La eliminación de un paso es muy sencilla, basta con seleccionarlo y pulsar Supr o hacer clic en el icono de borrado situado junto a su nombre.
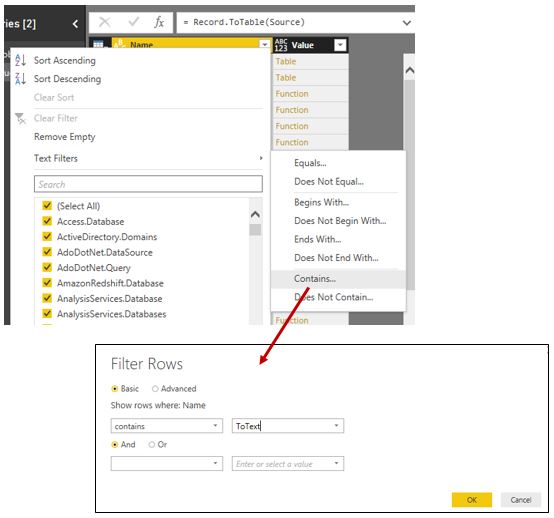
A continuación abriremos nuevamente la caja de filtro y en la opción Text Filters seleccionaremos Contains, introduciendo en el cuadro de filtro el valor ToText. Tras aceptar este cuadro de diálogo obtendremos como resultado todas las funciones cuyo nombre contiene la partícula introducida.
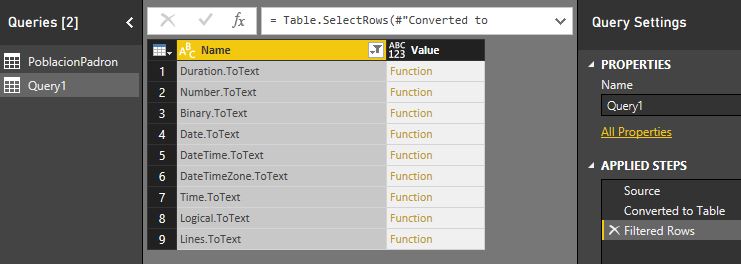
Una vez que terminemos de consultar la documentación utilizando estas técnicas podemos seleccionar la tabla Query1 en el panel Queries y eliminarla pulsando la tecla Supr.
Columna para identificar el sexo del individuo
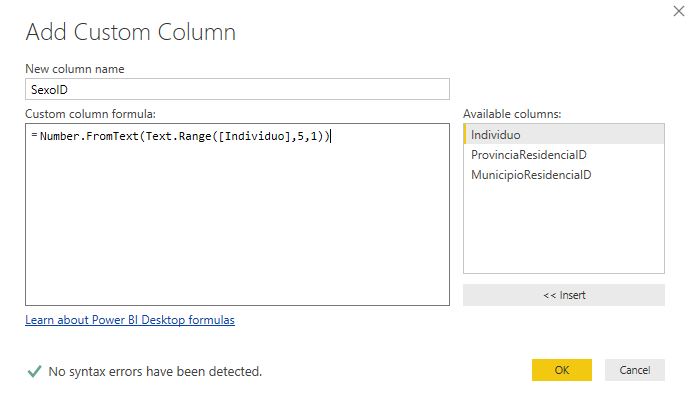
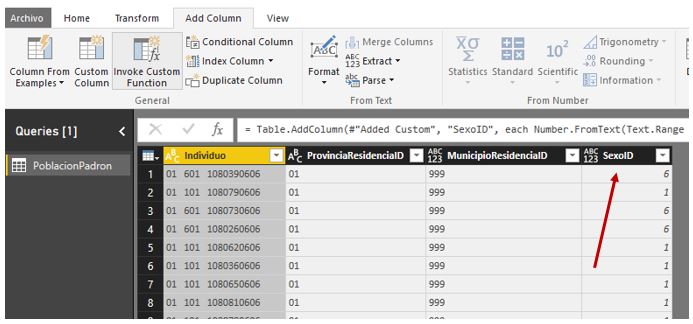
El dígito situado en la posición 6 de la columna Individuo identifica el sexo de la persona, siendo el valor 1 para hombre y 6 para mujer. Este valor lo trasladaremos a la nueva columna SexoID, donde además de la función Text.Range utilizaremos Number.FromText, para convertir el resultado a un tipo de dato numérico.
Number.FromText(Text.Range([Individuo],5,1))
Tipos de datos en Power Query. Elegir entre Any o un tipo concreto
Al crear la columna SexoID en el apartado anterior, a pesar de haber empleado la función Number.FromText para convertir su contenido en número, el tipo de dato de la columna generada es Any (cualquiera o tipo genérico) en lugar de Whole Number (número entero) como era nuestra intención, lo cual nos obliga de forma explícita a cambiar el tipo de dato de la columna haciendo clic en su nombre, y a continuación, en el menú Home, grupo Transform, opción Data Type, seleccionar el valor Whole Number.
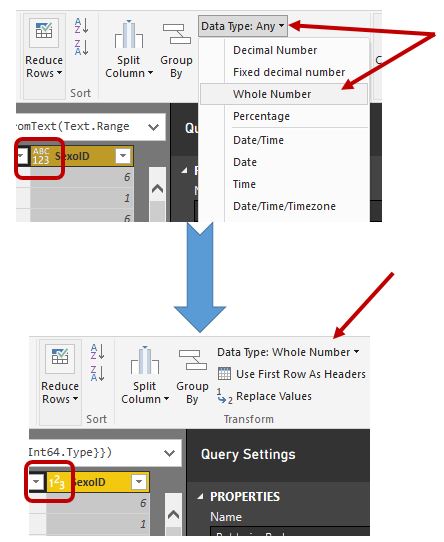
Siempre que nos encontremos ante una situación de estas características, en la que Power Query ha asignado por defecto el tipo Any a una columna, pero nosotros sepamos cuál es el tipo de dato adecuado que la misma debería tener, la recomendación es que cambiemos su tipo al que realmente le corresponda, para que las operaciones con la misma puedan llevarse a cabo con mayor precisión y fiabilidad.
Para conocer de modo rápido el tipo de dato que tiene una columna nos fijaremos en el icono situado en el lado izquierdo de su título; los más habituales se muestran a continuación.

Otra técnica que también podemos utilizar para el cambio de tipo de datos consiste en hacer clic sobre dicho icono de la cabecera de columna y elegir el nuevo tipo en la lista que aparece.
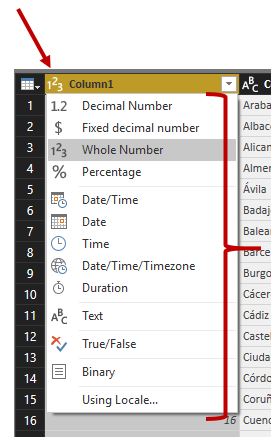
A partir de aquí, en aquellas operaciones que supongan la creación de una columna, especificaremos junto a su nombre el tipo de dato que debe tener
Lugar de nacimiento. Provincia
La siguiente columna, que tendrá el nombre ProvinciaNacimientoID (Text), se obtiene de las posiciones 7 y 8 de la columna Individuo, y representa, como indica su nombre, la provincia de nacimiento de la persona. Para la población nacida fuera de España se usará el valor 66, y en el caso de nacidos en antiguos territorios españoles se usa el código 53.
ProvinciaNacimientoID ===================== Text.Range([Individuo],6,2)
Lugar de nacimiento. Municipio o país
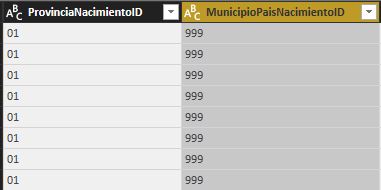
El municipio o país de nacimiento se obtiene de las posiciones 9, 10 y 11, trasladándose a la columna MunicipioPaisNacimientoID (Text). Para las personas que no hayan nacido en España, el valor corresponderá al código del país de nacimiento. Al igual que sucedía con el lugar de residencia, en los municipios de menos de 10000 habitantes se blanquea este valor por protección de datos, de modo que para estos casos utilizaremos el código 999.
MunicipioPaisNacimientoID ===================== if Text.Length(Text.Trim(Text.Range([Individuo],8,3)))=0 then "999" else Text.Range([Individuo],8,3)
Nacionalidad
Los datos del código de nacionalidad, que trasladaremos a una columna con el nombre NacionalidadID (Text), se encuentran en las posiciones 12, 13 y 14.
NacionalidadID ===================== Text.Range([Individuo],11,3)
Edad
La edad del individuo se traspasará a una columna llamada EdadID (Whole Number), obteniéndose de las posiciones 15, 16 y 17.
EdadID ===================== Text.Range([Individuo],14,3)
Tamaño de municipio según habitantes
Y terminamos con la creación de las columnas que indican el tamaño de municipio de residencia y nacimiento según su número de habitantes: TamMunicipioResidenciaID (Text) y TamMunicipioNacimientoID (Text). Ambas tienen una longitud de 2 dígitos y se encuentran respectivamente en las posiciones 18 y 19 así como en la 20 y 21.
Por cuestiones de confidencialidad estadística, en los municipios menores de 10000 habitantes, si para una provincia existe un único municipio en un tramo de población, éste se ha añadido al tramo siguiente o anterior manteniendo el código de este último.
Al igual que ocurría con la provincia de nacimiento, para la columna TamMunicipioNacimientoID, en aquellas personas nacidas en el extranjero se asigna el código 66, mientras que los nacidos en antiguos territorios españoles se codifican con el valor 53. El siguiente bloque de código muestra las expresiones a utilizar para construir estas columnas.
TamMunicipioResidenciaID ====================== Text.Range([Individuo],17,2) TamMunicipioNacimientoID ======================= Text.Range([Individuo],19,2)
En siguiente figura podemos ver las últimas columnas que hemos creado.

Composición del identificador de lugar de residencia
MunicipioResidenciaID no es una columna que pueda utilizarse de forma autónoma para hacer la selección del lugar de residencia del individuo. La muestra más palpable de ello la tenemos en el hecho de que si revisamos la hoja CMUN del archivo Excel origen, el código 004, por poner un ejemplo cualquiera, corresponde a municipios de 5 provincias diferentes, por lo que para referirnos de forma unívoca a una localidad necesitamos ambos códigos: provincia y municipio.
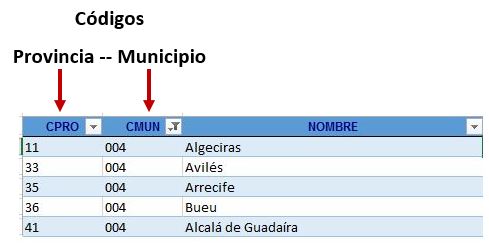
Por dicha razón crearemos una nueva columna llamada LugarResidenciaID (Text), en la que concatenaremos los valores de ProvinciaResidenciaID y MunicipioResidenciaID. Esto nos permitirá posteriormente construir una consulta con un identificador de iguales características, que utilizaremos como tabla de búsqueda al implementar el modelo de datos en Power BI.
LugarResidenciaID ================ [ProvinciaResidenciaID] & [MunicipioResidenciaID]

Composición del identificador del lugar de nacimiento
Supongamos que en la fase de creación del modelo de datos queremos diseñar la información del lugar de nacimiento como una jerarquía formada por los niveles país, provincia y municipio. Una forma de resolver este problema pasaría por la creación, en la tabla actual, de una nueva columna que actúe de identificador, a la que llamaremos LugarNacimientoID (Text), formada por tres códigos distintos correspondientes a los niveles que acabamos de mencionar. El modo de componer este identificador variará en función de si el individuo nació en España o el extranjero, dato que averiguaremos consultando la columna ProvinciaNacimientoID.
Si el valor de ProvinciaNacimientoID es 66 se trata de un extranjero, lo que significa que la columna MunicipioPaisNacimientoID contiene el código de país de nacimiento en lugar de un municipio. Como es lógico, en este caso carecemos del código de municipio, por lo que asignamos el valor 999 para indicar que se trata de una localidad desconocida o no disponible.
[MunicipioPaisNacimientoID] & [ProvinciaNacimientoID] & "999"
Si el valor de ProvinciaNacimientoID no es 66 comenzaremos a construir el identificador con el valor 108, que corresponde al código de país de España, seguido de ProvinciaNacimientoID y MunicipioPaisNacimientoID.
"108" & [ProvinciaNacimientoID] & [MunicipioPaisNacimientoID]
La expresión al completo para crear la columna se muestra en el siguiente bloque de código.
if [ProvinciaNacimientoID] = "66" then //si nació en el extranjero [MunicipioPaisNacimientoID] & [ProvinciaNacimientoID] & "999" else //si nació en España "108" & [ProvinciaNacimientoID] & [MunicipioPaisNacimientoID]
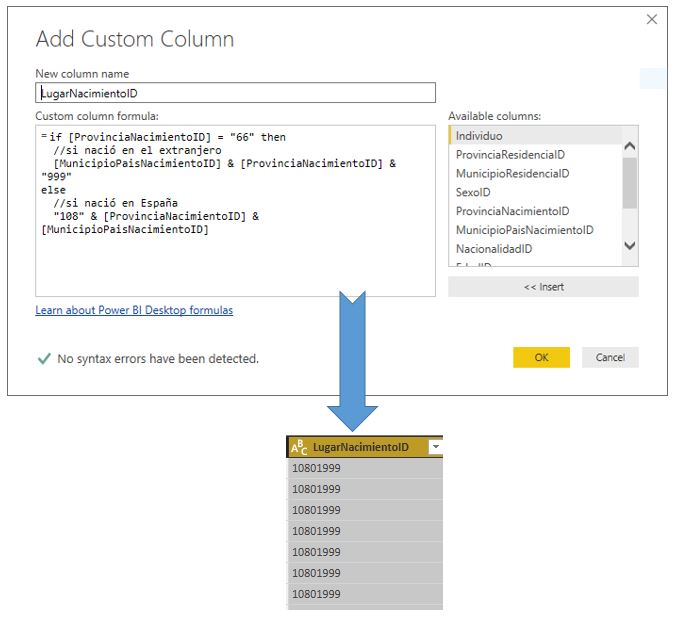
Tras la creación de LugarNacimientoID eliminaremos aquellas otras columnas utilizadas como soporte en la preparación de esta tabla, que no necesitaremos emplear de aquí en adelante para el desarrollo del modelo de datos. Las columnas en cuestión serán: Individuo, ProvinciaResidenciaID, MunicipioResidenciaID, ProvinciaNacimientoID y MunicipioPaisNacimientoID.
A continuación ejecutaremos nuevamente la opción de menú Close & Apply en el Query Editor, y en la ventana de Power BI guardaremos los cambios en el archivo .pbix.
Conclusiones
Llegados a este punto finalizamos el presente artículo, en el que hemos realizado una introducción a Power BI desde una perspectiva de herramienta ETL, haciendo uso de las operaciones de transformación de datos pertenecientes al motor de Power Query integrado en esta herramienta, con el objetivo de armar la tabla de datos para un modelo que construiremos con los diseñadores de Power BI.
En una próxima entrega continuaremos con el desarrollo de este sistema de información, abordando la creación, también con el Query Editor, de las tablas de búsqueda, que una vez relacionadas con la tabla de datos, permiten a los usuarios realizar sus labores de análisis mediante la aplicación de filtros y la creación de métricas.
Agradecimientos
Quisiera expresar mi agradecimiento a María Dolores Esteban Vasallo y Ricard Gènova Maleras, integrantes del Servicio de Informes de Salud y Estudios (Subdirección de Epidemiología, Dirección General de Salud Pública, Consejería de Sanidad. CM) por la ayuda prestada en el diseño de las métricas del modelo de datos, la selección de la fuente de datos utilizada como base para la elaboración del presente artículo, así como una inestimable tarea de revisión del mismo.
Enlaces de Interés
Blog de Power BI: https://powerbi.microsoft.com/es-es/blog/tag/power-query/
PowerPivotPro (Rob Collie): https://powerpivotpro.com/
Radacad (Reza Rad): http://radacad.com/blog
Excelguru (Ken Puls): https://www.excelguru.ca/blog/
DataChant: https://datachant.com/


Deja un comentario