Durante el día de ayer se celebró a escala mundial el Global Azure Bootcamp, del cual fui asistente a la edición que se celebró en Madrid.
Un hecho relevante para el evento, además de la parte de charlas y formación, es que siempre se emplea un laboratorio científico en el cual podamos hacer una contribución a una línea de investigación. Durante el día del evento todos los asistentes podemos desplegar el laboratorio en nuestras suscripciones de Azure, escalarlo y que vaya haciendo lo que debe hacer para obtener resultados que serán analizados más tarde. Años anteriores los laboratorios trataron sobre la investigación del cáncer de mama, el estudio de la diabetes tipo 2, por poner un ejemplo. Es un modo de poner nuestro granito de arena a una buena causa.
Secret Life Of Galaxies
Este año el laboratorio consistía en ayudar al Instituto Astrofísico de Canarias. Una de sus múltiples líneas de investigación consiste en el estudio de las galaxias para, a través de sus estrellas, entender cómo, cuándo y por qué se formaron. En especial se busca obtener la información de las estrellas más antiguas de la galaxia a estudiar para obtener información sobre su edad y composición química.
Para obtener esta información se hacen capturas de las estrellas de una galaxia y se analiza cómo es la luz que se captura. A través de la frecuencia se puede obtener información sobre la composición, ya que tenemos referentes en los cuales basarnos. El problema es que, al ser una medición, la captura incluye una serie de errores que dificultan el análisis de datos:
La imagen de la izquierda corresponde a una imagen limpia. Cada color se refiere a cómo son las estrellas en términos de edad y formación química. Sin embargo, la imagen de la derecha corresponde a la imagen en bruto. Se aprecia que los límites están menos definidos, hay mucho ruido y por lo tanto, dificulta el análisis de la información. El objetivo del laboratorio de este año es aplicar un algoritmo a escala global que contribuya a «limpiar» los datos para reducir el ruido y permitir un análisis correcto.
El algoritmo fue desarrollado por Sebastián Hidalgo en el Instituto Astronómico de Canarias y se llama SELiGa (Secret Life Of Galaxies). Los resultados de este experimento irán a un paper que se publicará en el próximo Astronomy Journal
Charlas
Al igual que otros años, la organización decidió dividir en tres tracks las charlas, con la diferencia que esta vez no había un track definido por área, sino que estaban mezcladas. Por ejemplo, en el Track 1 había charlas de desarrollo, de IT… La organización prefirió hacerlo así para que la gente se moviese entre charla y charla y así, compartir impresiones y conocerse. Como no pude ir a todas las que me habría gustado, pondré un resumen de las que tuve el placer de asistir:
Seguridad en Azure: hazme una rebajita guapi. claro que si !!!: Joaquín Molina nos contó, desde el punto de vista de infraestructura, algunas prácticas muy recomendables de cara a logging y seguridad en general de los recursos que tenemos desplegados en Azure.
Azure Key Vault o como el capitán Kirk asegura la nave: En esta charla Alberto Díaz expuso cómo usar Azure Key Vault y cómo ha mejorado respecto a hace un año. Bastante interesante porque propuso varias demos basadas en El Mundo Real que serán muy útiles para nuestro día a día.
Descubriendo la Historia del Universo con Microsoft Azure: Tenía mucha curiosidad en asistir a esta charla, porque explicaron en detalle cómo funciona y qué incluye el laboratorio que se ha desplegado en Azure para poder ejecutar SELiGa. Los ponentes fueron David Rodríguez, Adonai Suárez y Sebastían Hidalgo.
GPU Cloud Computing: la potencia de la aceleración gráfica en Azure: Esta ha sido una de las mejores charlas a las que he asistido en general, tanto por el contenido por la forma. Carlos Milán y Alberto Marcos explicaron en detalle cómo y por qué usar una GPU puede ayudar a acelerar determinados algoritmos. Como demo, además del minado de bitcoins, enseñaron cómo jugar a Project Cars III en UltraHD a través de Azure. Si tienes pensado en comprarte un PC para jugar y juegas menos de 30 horas al mes, aconsejo mirar esta charla…
Qué tengo que saber como desarrollador sobre Blockchain: Iván González nos explicó cómo es blockchain, para qué se puede usar y qué implicaciones tiene dentro de la computación actual.
Migrando de ASM a ARM (2.0) – Tips and Tricks: Otra charla desde las trincheras. Alejandro Almeida García nos contó, bajo su experiencia, cómo funciona la migración entre ASM y ARM y qué problemas podemos encontrarnos en función de qué recurso queramos migrar y qué estrategia queramos aplicar.
Chihuahua o Muffin: Deep Learning con CNTK: ¿Alguna vez te has preguntado si esa mopa que ves de lejos es realmente una mopa, o un perro? Bienvenido, pues no eres el único. Pablo nos explicó con cierto detalle cómo funcionan las redes neurales que se usan en Deep Learning y qué operaciones matemáticas se usan para el aprendizaje. Otra charla magistral, completa, clara y directa.
Agradecimiento
Una vez más, algo va muy bien cuando un evento logra llenar las plazas disponibles en un sábado. Por supuesto, quiero agradecer por aquí a la organización por la elección del laboratorio científico (ya que me parece fascinante y lo tenemos «en casa») y además por todo el esfuerzo y dedicación que han empleado para lograr que este evento sea un éxito.
Este fin de semana tuvo lugar el Freakend 2017 de videojuegos y como era de esperar, fue apasionante. Esta vez fuimos 82 personas en el evento y lo organizamos en un hotel de la sierra de Madrid. De hecho, reservamos la totalidad del hotel para nosotros y nos permitió de disponer de varias salas para el evento.
Mientras que otros años había una gran cantidad de charlas e incluso varios tracks distintos, esta vez la organización prefirió tener una sala destinada a las charlas (la mayoría de una hora de duración y un conjunto de charlas mas «ligeras» que comentaré más adelante) y otra sala donde estaban montadas diferentes experiencias de realidad virtual, juegos de mesa, emuladores e incluso algo de retro gracias a Carlos Milán. Las charlas fueron en bloques de dos en dos, lo que permitía no saturarse demasiado y además poder comentar con los asistentes el contenido de la misma sin prisa ni mucho estrés.
Las charlas fueron de diversa índole. Algunas destinadas más al ámbito de la programación, otras de diseño y otras sobre experiencias personales o el estado de la industria.
50 sombras de eSports: Nacho Lasheras nos comenta los orígenes, las causas y el futuro de los eSports. La verdad es que fue bastante interesante, porque desde «fuera» de la industria parece que ha sido una irrupción muy súbita cuando realmente es algo que lleva gestándose desde hace tiempo y que por supuesto, no ha hecho más que empezar.
Mesa Redonda de VR: Diego Bezares moderó una mesa sobre el estado de VR. Como comentario personal, mucha gente estaba trabajando con VR. En la sala contigua pude probar algunos cacharros y esta vez sí puedo decir que al menos, en mi opinión personal, hay juegos de verdad para VR en lugar de demos puramente técnicas.
Hacking de videojuegos: Carlos nos explicó cómo se puede hackear un videojuego aplicando técnicas de ingeniería inversa usando JS. Pudimos ver cómo volar con el Guild Wars 2, cómo crear un modo espectador e incluso cómo la gente de Blizzard protege Overwatch para evitar hackeos.
Técnicas de narrativa ambiental: Juan Fernandez de Simón, de Ninja Theory nos contó algunos de los recursos que se usan en videojuegos para contar historias. Como jugador es un tema que nunca me he planteado, pero me resultó muy curioso las técnicas que usan para meterte en la historia sin que te percates.
La startup alrededor del videojuego: Gema Parreño nos cuenta su experiencia creando una startup y un producto. Es una charla que me gustó especialmente, y salvando las diferencias, lo comparo con el reciente asuntillo de GitLab. Creo que hay que ser muy valiente para contar la realidad, la verdad y ser sincero ante una audiencia sobre todo lo acontecido.
DIV2js: Salvador de la Puente nos explicó cómo usa DIV a través de un conversor de JS. Fue una charla apasionante en la que explicó cada paso del pipeline para convertirlo, las instrucciones, el modo de programarlo…
Charlas ligeras:
Multijugador en Dynasty Feud*: Aitor Tejedor nos explicó cómo implementaron el multijugador en Dynasty Feud y cómo resolvieron problemas relativos a la latencia y sincronización de los jugadores en la partida. Realmente interesante
Fabric Engine: En este caso Borja Morales nos explicó cómo usan su engine y cubren lo que no pueden hacer con los comerciales.
El código de las fuentes: Jaime adora las fuentes y nos contó cómo funcionan y los problemas que tienen a la hora de localizar un videojuego. Como siempre, chapó.
Juegos narrativos: Ludipe nos cuenta cómo está haciendo un juego de índole narrativa, qué pasos sigue y cómo va quedando. Todo un currazo. Además por la noche me enseñó unos cuantos juegos indie españoles multijugador que no conocía. Y por supuesto, fue épico.
Mixed reality: Mi compañero David Ávila presentó algunos de los trabajos que se han hecho en Plain Concepts sobre realidad mixta.
Karisma: Unai Landa -que «sólo» lleva 21 años en la industria- nos explicó cómo han trabajado en Karisma, el motor que usan en Digital Legends y que tiene más de 10 años. Una charla interesantísima.
Gráficos vectoriales para videojuegos: Beatriz Alonso expuso, desde el punto de vista del artista, cómo tuvieron que hacer para tener un modelo vectorial en un juego 2D optimizando espacio y rendimiento. Fue muy interesante ver todo el proceso del pipeline y cómo van optimizando e iterando hasta conseguir el menor número de vértices posibles. Además de otras cosas muy interesantes.
Zalo Engine: Un freakend no sería lo mismo si no hacemos un juego para GameBoy. Dicho y hecho: Gonzalo nos explicó cómo usar un motor para programar en C (en lugar de ensamblador) un juego. Además, todo el código en riguroso directo.
Como siempre, lo primero de todo es agradecer a @flipper83 por todo el esfuerzo y trabajo que ha dedicado para organizar este evento. Además, hemos tenido la oportunidad de conocer a personas apasionantes. Como les digo en privado siempre, gracias por organizar cosas como estas.
*Editado:
Gracias a Nacho, que me indicó que no apunté la charla de Dynasty Feud de Kaia Studios. Y mis disculpas a Kaia Studios por no haberos incluido en un primer momento!
Aviso: Es un artículo largo y no muy técnico. Te recomiendo coger un café y/o armarte de paciencia 🙂
Nota: Este artículo nace de un proyecto personal, presentado como charla en The Mindcamp. No hubiera sido posible construir esto sin todos mis amigos y colegas que me ayudaron cuando lo pedí. Aprovecho este canal para daros las gracias 🙂
Cuando Microsoft presentó el Bot Framework hace unos meses y además insistió bastante en IA y bots, se me ocurrió que podría hacer un mini proyecto para ver qué tal funciona y comprobar su uso.
El concepto de bots no es nada nuevo. Ya cuando era joven pasaba las tardes en el IRC respondiendo a bots de preguntas; e incluso alguno me hice para hacer chorradas con los usuarios de la sala de chat. Al presentar el Bot Framework, me vino el recuerdo de esa etapa y me puse a investigar a ver cuál es la visión de usar bots ahora y qué podemos hacer con ellos. Por un motivo o por otro quería hacer un bot y quería que fuese distinto. No quería el típico que te diga la hora o tengas frases prefijadas.
Bot Framework
Este artículo NO va a ser un artículo dedicado a analizar Bot Framework. Ya hay infinidad de artículos muy buenos en la MSDN y otros tantos tutoriales de «Hola Mundo». Si quieres saber cómo funciona, te recomiendo que le eches un vistazo a la página de Bot Framework.
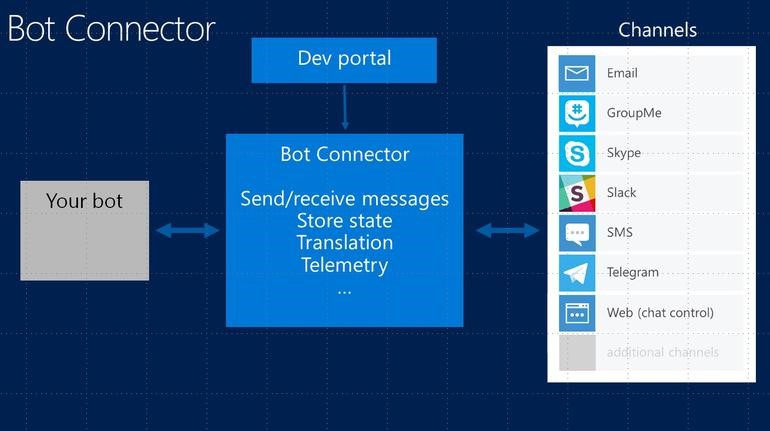
Para mí Bot Framework me supone un alivio a la hora de crear un bot, ya que simplifica lo que es el propio bot (básicamente una WebAPI que tiene un único endpoint a través del cual se reciben todos los mensajes): gestión de conversaciones, permite traducir automáticamente los mensajes y en especial, han cuidado mucho la integración con otras plataformas. Tiene un gestor muy sencillo en el cual con varios pasos guiados y muy sencillos te permite desplegar tu bot sobre distintas plataformas, como Skype, Telegram, Facebook, SMS, etc. Tal vez para mí esta sea una de las características más importantes, ya que me permite gestionar la publicación del bot sobre las distintas plataformas de una forma centralizada.
Una cosa a tener en cuenta es que no es una release. Bot Framework está en preview, con todo lo que ello implica. Funciona bien y han mejorado bastante respecto a hace unos meses, pero no omitas la palabra «preview» al pensar en ello.
Una vez sabiendo cómo podía publicar el bot, el siguiente paso era darle contenido. Según la plataforma puedes hacer que el bot sea proactivo desde el punto de vista del usuario o te ofrezca opciones. Por ejemplo, puedes hacer que a determinada hora el bot te abra una conversación y te diga algo. O puedes que te envíe imágenes o preguntas con opciones elegidas para que te muestre algún tipo de información. En cualquier caso mi objetivo es mucho más humilde y si el bot responde a algo relacionado con lo que el usuario le envía, me doy por satisfecho. No quiero que el bot reciba comandos, quiero que sea capaz de interpretar un texto normal escrito por un humano.
Como quiero un bot que responda, necesito dotarle de frases que responder. En un primer momento pensé en buscar frases célebres de WikiQuote o usar textos de subtítulos de alguna serie. Pero me resultó más fácil coger algún perfil de Twitter famoso y usarlo como corpus de frases que responder. Así pues con esto, la arquitectura de mi bot sería la siguiente:
Una web app que expone una web api para usar Bot Framework.
Un web job se encargaría de la ingestión de datos vía Twitter. Cada hora se conectaría a Twitter y extraería los tweets de los perfiles de usuario que he marcado.
Con esto tan simple ya tengo el bot con contenido funcionando. Además, me permite tener la web app en Free. Y sí, Bot Framework es gratuito. Al menos de momento.
Cognitive Services
Text Analyzer
El siguiente paso es encontrar una forma de dada una entrada de usuario, poder devolver la respuesta más apropiada dentro del corpus de mensajes. Aquí es importante tener un corpus amplio y variado. Para ello tenía que disponer de alguna forma de «entender» lo que quería decir el usuario y tener una forma de «entender» qué significan los tweets del corpus. La primera aproximación consistía en intentar hacer un análisis de la frase para extraer la estructura gramatical y trabajar con ello. Evidentemente es una tarea muy compleja y no es algo que se pueda hacer en un par de horas, así que descubrí una serie de APIs dentro de Microsoft Cognitive Services que permiten extraer información del texto. En concreto me basé en Text Analyzer, que permite detectar el idioma y extraer las frases principales de un texto. Aunque bien es cierto que Cognitive Services proporciona APIs para extraer la estructura gramatical de una oración o frase, esta sólo está disponible en inglés. Como mi corpus son mensajes en español, tuve que descartarlo directamente.
Usar TextAnalizer (la API de Cognitive Services que se encarga de esto) es tan sencillo como hacer una petición HTTP a la propia API:
Primero se le pasa como header la clave de autenticación (que se obtiene una vez te registras en la API) y después lanzas una petición al endpoint deseado. En mi caso es el siguiente:
var uri = "text/analytics/v2.0/keyPhrases";
response = await CallEndpoint(client, uri, byteData);
var keyPhrases = JsonConvert.DeserializeObject<TextResponse<KeyPhraseResponse>>(response);
Donde el método CallEndPoint, simplemente hago la llamada con el formato correcto:
var result = string.Empty;
using (var content = new ByteArrayContent(byteData))
{
content.Headers.ContentType = new MediaTypeHeaderValue("application/json");
var response = await client.PostAsync(uri, content);
if (response.Headers.Contains("operation-location"))
{
var operationId = response.Headers.GetValues("operation-location").Single();
var operationRequest = string.Format(operationUrl, operationId);
do
{
// Request every minute
await Task.Delay(60000);
response = await client.GetAsync(operationRequest);
result = await response.Content.ReadAsStringAsync();
} while (result.Contains("\"status\": \"succeded\""));
}
else
{
result = await response.Content.ReadAsStringAsync();
}
}
return result;
La estructura de datos de la API se organiza en base a un documento que incluye todos los datos, así que lo modelé y a la hora de hacer una petición, realmente envío el siguiente conjunto de bytes:
Document document = null;
var request = new TextRequest() { Documents = new List<Document>() };
for (int i = 1; i &lt;= input.Count; i++)
{
document = new Document
{
Id = i.ToString(),
Text = input[i - 1]
};
request.Documents.Add(document);
}
var serializedEntity = JsonConvert.SerializeObject(request);
byte[] byteData = Encoding.UTF8.GetBytes(serializedEntity);
Cada texto que envío debe estar identificado, porque después me es devuelto con el mismo identificador y con el resultado del análisis. Además, esto me sirve para aprovechar que puedo analizar varias frases en una misma llamada a la API en lugar de una por una, ya que hay un límite mensual de llamadas (tengas o no la suscripción gratuita). De esta forma aprovecho el webjob de ingesta de datos de Twitter para preanalizar las frases en bloques y así reducir la cantidad de llamadas efectuadas. Sólo se hace una llamada cuando se pregunta al bot, para obtener las frases principales de lo que ha escrito el usuario. Para hacerlas coincidir, miro cuáles coinciden con el corpus y elijo una al azar entre las seleccionadas.
L.U.I.S.
Ya tenía un sistema «para salir del paso» que me permitiese tener un bot que responda a algo parecido a lo que se le pregunta. Una vez hecho esto, le pedí a varios amigos que me ayudasen y le preguntasen cosas al bot. Esto fue crucial, porque pude ver qué se le preguntaba al bot y afinar un poco las respuestas. Gracias a ello, me permitió descubrir una serie de patrones de preguntas/frases que lanzan al bot y que yo no hacía. Ahora ya necesitaba algo más, necesitaba algo que me permitiese detectar patrones en las peticiones que recibía y reorientar la respuesta hacia esos patrones. Por ejemplo, si preguntas «¿Quien es Messi»? lo ideal es ser capaz de identificar que estás haciendo una pregunta, que preguntas quién es y en concreto, alguien en concreto. Si cambio la pregunta por «¿Quien es Cristiano Ronaldo?» es el mismo tipo de pregunta, pero el objeto sobre el que pregunto ha cambiado. La pregunta puede variar levemente, puede empezar en minúscula, sin el signo de interrogación inicial, sin el final, con / sin tildes… Además puede haber otras preguntas similares.
Para este tipo de casos se suele usar aprendizaje automático. La idea es sencilla: dado un conjunto inicial de elementos ya categorizados, seré capaz de ir detectando los nuevos elementos. Tal vez no los detecte a la primera, o no sean exactos, pero en ese caso puedo reanalizarlos de nuevo y detectarlos mejor iteración por iteración.
Cognitive Services nos proporciona L.U.I.S. (aka Language Understanding Intelligence System) que es justamente una herramienta de aprendizaje automático que está pensada para procesar modelos basados en comandos. Por ejemplo, dentro de mi modelo la pregunta «Quien és Messi?» es una entidad y le marco que «Messi» es una persona. A base de ponerle más preguntas y entrenarlo más, puedo ponerle preguntas similares y el sabrá decirme si es una pregunta de tipo «Quien és» y que «Messi» es la persona.
Aunque L.U.I.S. admite un conjunto limitado de entidades, me sirvió para obtener una serie de preguntas típicas que mis usuarios habían hecho. Además me permite mantener y entrenar a mi modelo si veo que algo no lo detecta. Si por ejemplo recibo la pregunta «quien es Federico Garcia Lorca» y no me detecta bien el nombre, puedo reindicarle «Federico García Lorca» es la persona y el modelo se vuelve a entrenar con esta información.
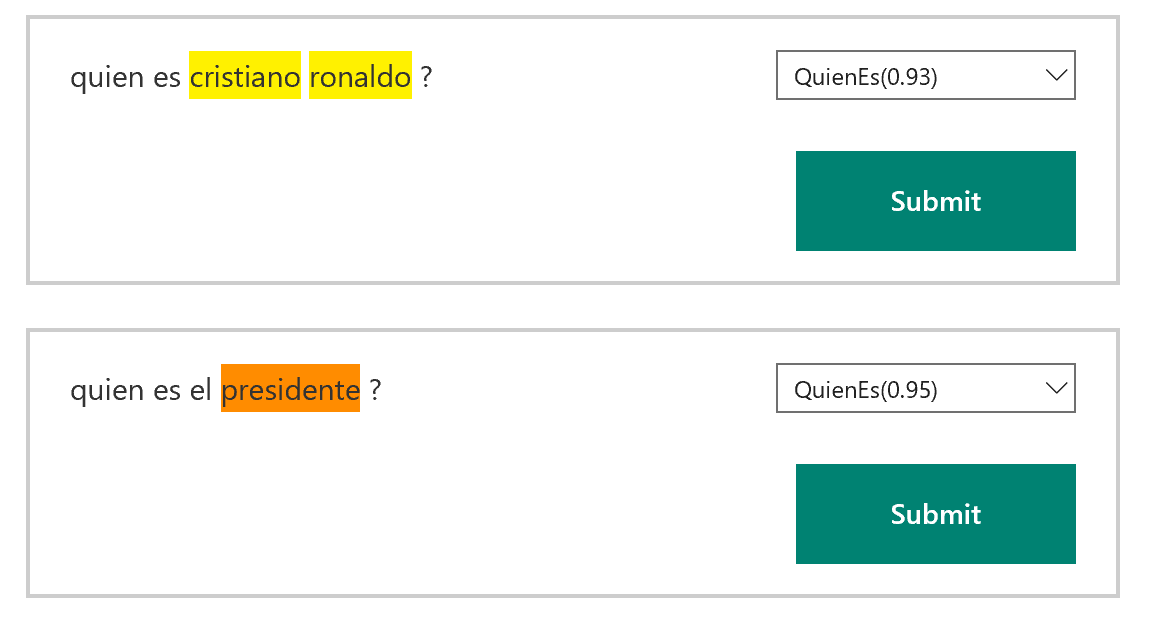
Veámoslo con una captura de ejemplo, extraída directamente del modelo que tengo construido:
Dentro de las entidades que dispongo, es capaz de detectar que a las entradas «quien es cristiano ronaldo?» y «quien es el presidente?» se corresponden con la pregunta modelada como «quien es X». Nos indica para la primera un 93% de probabilidad y un 95% para la segunda. La diferencia de colores en las palabras resaltadas es el tipo que busco, ya que tengo dos tipos de objetivos: personas y cosas. Es capaz de detectar que «cristiano ronaldo» es una persona y que «presidente» es una cosa. Y siempre, si considero que está mal o no está muy afinado, puedo cambiar esa asignación y volver a enviar la entrada pulsando «Submit». En ese momento el modelo se entrenará de forma automática y será capaz de afinar la respuesta con la información que le hemos suministrado.
A nivel de código L.U.I.S tiene su propio paquete de NuGet, por lo que no es necesario hacer una llamada HTTP y preparar/procesar los datos a enviar/recibir.
bool _preview = true;
LuisClient client = new LuisClient(_luisAppId, _luisSubscriptionKey, _preview);
LuisResult res = await client.Predict(input);
Con estas tres simples líneas, invocamos a L.U.I.S. Nótese que lo que le enviamos es que nos prediga en base a una frase. Esa frase la lanzará contra el modelo que tiene ya entrenado y nos devolverá un resultado con la probabilidad de las entidades que él cree que son relacionadas con la frase que hemos enviado. Además, podrá detectar parte en las entidades (ej: «Messi») si así le hemos entrenado previamente. Ya es decisión nuestra, en parte a la probabilidad de cada entidad en determinar qué hacer. Lo bueno es que si vemos que la probabilidad no nos encaja con lo que creemos que debería ser, siempre podemos volver a L.U.I.S y darle más información sobre el modelo para volver a entrenarlo.
Ahora ya sí, con un simple algoritmo podía lanzar peticiones a L.U.I.S, ver si encontraba algo que me pudiera valer y si no, seguía cotejando con las frases clave de los textos.
¿Cuál es el secreto de la felicidad?
Una pregunta arriesgada y profunda. Si supiera la respuesta o quisiera hacer creer que la se, posiblemente dejaría el gremio y me pondría a escribir libros y dar conferencias como buen gurú. Lamentablemente sólo sé que no sé nada, así que dejaré mis bestsellers para otro momento en mi vida. Pero si has llegado hasta aquí, al menos me reconocerás que el título tiene gancho.
Posiblemente, el hombre más feliz de Springfield
Pero la pregunta, si bien no quiero saber cuál es el secreto, sí me interesa saber si mis usuarios son felices o no. Los textos que escribimos en redes sociales se usan en los típicos estudios de doctorandos desde hace varios años para analizar su contenido y entender qué significan. Tal vez no ahora, pero hace unos años era bastante común: saber si lo que escribo es algo feliz o triste. Se suele analizar teniendo en cuenta el contexto, las palabras que se emplean, expresiones no lingüísticas (como emoticonos) etc. Evidentemente desde un punto de vista comercial es bastante interesante de cara a categorizar a tus usuarios…
Una de las propiedades de la API de Text Analyzer es que permite extraer la felicidad de los textos. Realmente, para ser exactos, más que la felicidad en sí trata de analizar los textos para ver si tienen un sentimiento negativo o positivo. Usando esta API, del mismo modo que se hizo antes con las frases clave, puedo extraer de primera mano el sentimiento de mi corpus. Después lo usaré para ver el sentimiento del usuario cada vez que escriba un mensaje.
Preparados para el análisis…
Como la idea ahora ha sobrepasado la línea de «aplicación», pues vamos a entrar en el análisis, necesito modificar el proyecto. Ahora he de decidir qué quiero analizar/medir y en base a qué, así que:
Voy a analizar el sentimiento de mis usuarios
Voy a analizar cuáles son las palabras más usadas en mis usuarios
Voy a establecer una granularidad de tiempo hasta la hora del día.
Para ello necesitaré una estructura que permita estos análisis. Aunque tengo pocos datos, he decidido montar un cubo multidimensional que tiene las siguiente dimensiones:
Canal: Para saber de dónde vienen mis usuarios (Telegram, Skype, Facebook, SMS, etc)
Conversación: Los mensajes se agrupan en conversaciones (cada ventana de chat que se abre se considera una conversación)
Fecha: Fecha de cuándo se envío/respondió el mensaje, con una definición hasta la hora del día.
Fuente del mensaje: Para ver si es un mensaje que ha enviado el usuario o ha respondido el bot.
Tipo de mensaje: Para ver si es un mensaje o un comando.
Usuario: Los distintos usuarios que han usado el bot. Tengo la información que me suministra Bot Framework, que es prácticamente nada (Id y con suerte el nick/nombre) pero suficiente para poder separarlos después durante el análisis.
Palabra: Las palabras que se han usado en los mensajes.
Y finalmente, tendré dos tablas de hechos (donde junto las dimensiones con lo que quiero medir):
Conversación: Mido la felicidad de la conversaciones, cuántos mensajes tienen, cuántos usuarios participan…
Palabras: Mido cuántas palabras hay, cuál es la longitud de cada palabra…
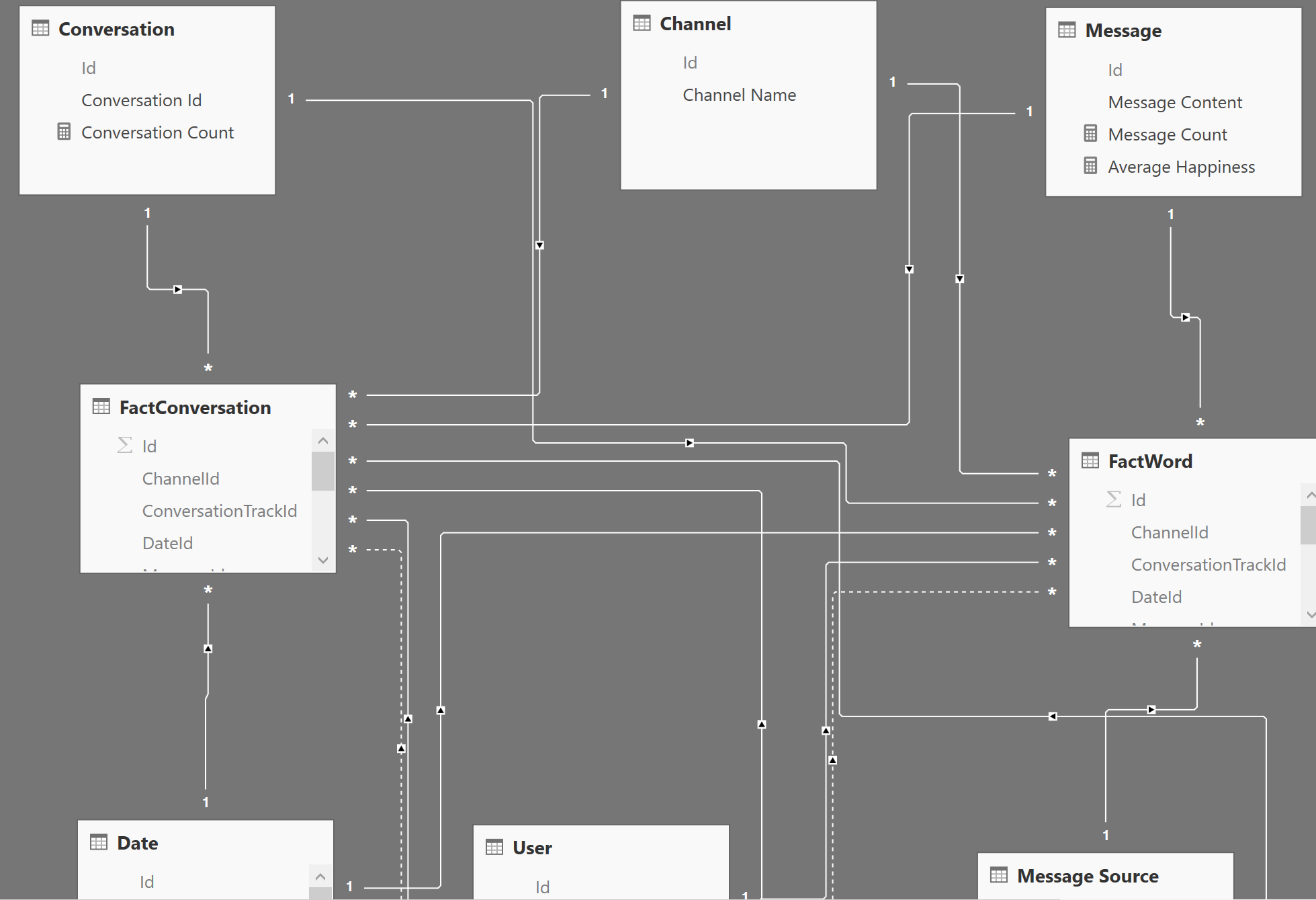
Y para montar este modelo, he usado la aproximación de Kimball para montar un modelo en estrella. La idea detrás de un cubo multidimensional es que relajamos las formas normales típicas de los modelos relacionales. Así pues, en mi tabla de hechos tendré una fila por cada entrada que quiera medir. En el caso de conversaciones, la granularidad llega hasta la frase. Por lo tanto, cada vez que alguien escriba o el bot responda, se insertará una fila en esa tabla. Esta limitado así porque si quiero medir el sentimiento, lo mido en base a una frase completa. La siguiente imagen es un ejemplo del contenido de esta tabla:
En el caso de la tabla de Palabras, la granularidad alcanza hasta la palabra en sí. Es decir, si se escribe una frase con 50 palabras, en esa tabla se insertarán 50 filas con cada una de las palabras.
El modelo en estrella propone que cada columna de la tabla de hechos que no sea una medida apunte hacia una fila de una dimensión. De este modo, tenemos la tabla de hechos en el centro «rodeada» de las dimensiones que emplea. De ahí el nombre en estrella:
Para poder montar este modelo, tengo dos retos fundamentales. El primero es que no quiero que la experiencia del bot se vea perjudicada. Ya bastante hace el tener que lanzar peticiones a una API externa por cada mensaje como para que además tenga que calcular e insertar las filas en el cubo. Aprovechando la estructura que tenía (webjobs gratuitos) y el patrón multitenant, monté dos webjobs y una cola:
Cada vez que hay una interacción con el bot, se manda la información a una cola de Azure.
Un webjob será el encargado de leer los datos de la cola y meterlos en una tabla de Staging dentro del cubo multidimensional. Esta tabla tiene datos casi «en bruto».
Otro webjob se encarga de coger todo lo que hay en Staging y procesarlo para actualizar cada una de las dimensiones y finalmente, rellenar las tablas de hechos con la información suministrada.
Posiblemente la parte de la cola la podría haber ahorrado, pero al tener todo el entorno «bajo mínimo» quería minimizar el impacto en el bot y prefería darle a otro esa responsabilidad.
Ya casi está todo. Veamos un resumen:
Tenemos un bot que lee datos de Twitter
Al recibir una petición, consulta con L.U.I.S y TextAnalyzer la frase más acorde. Justo antes de mandar la respuesta al usuario, manda la información analítica a una cola
Por otro lado, los procesos de la parte analítica se encargan de coger los mensajes y rellenar las dimensiones y las tablas de hechos.
Todos los webjobs se ejecutan cada hora. Son independientes entre sí (pueden caerse los tres y el bot seguiría funcionando sin problema). Los mensajes no se borran de la cola hasta que no se insertan, por lo que si se cae incluso el job de la parte analítica, no perdería esa información. Quedaría ahí hasta que se pueda insertar de forma satisfactoria.
Además, lo tengo montado con Visual Studio Online con builds de integración y despliegue continuo. El despliegue sólo se hace si antes se ha hecho un backup automático de las bases de datos, por si rompo algo que al menos el bot deje de ir pero no pierda mis datos analíticos (que en el fondo es lo que importa en esta vida!)
Ver y entender, esa es la cuestión
De nada sirve que extraiga información, analíticas y luego no se pueda mostrar. Si no la puedo ver, es lo mismo que no tenerla.
Para visualizar los datos he usado PowerBI. Es una herramienta de Microsoft gratutita (la parte online no lo es) que permite generar reportes e informes en base a modelos de diversas fuentes. En mi caso particular, importé el cubo multidimensional en un modelo de PowerBI y le puse un formato correcto (nombre, tipos de datos, relaciones, etc). Esto permite que cualquiera que acceda al modelo pueda consultarlo con las dimensiones que antes he mencionado para extraer las medidas.
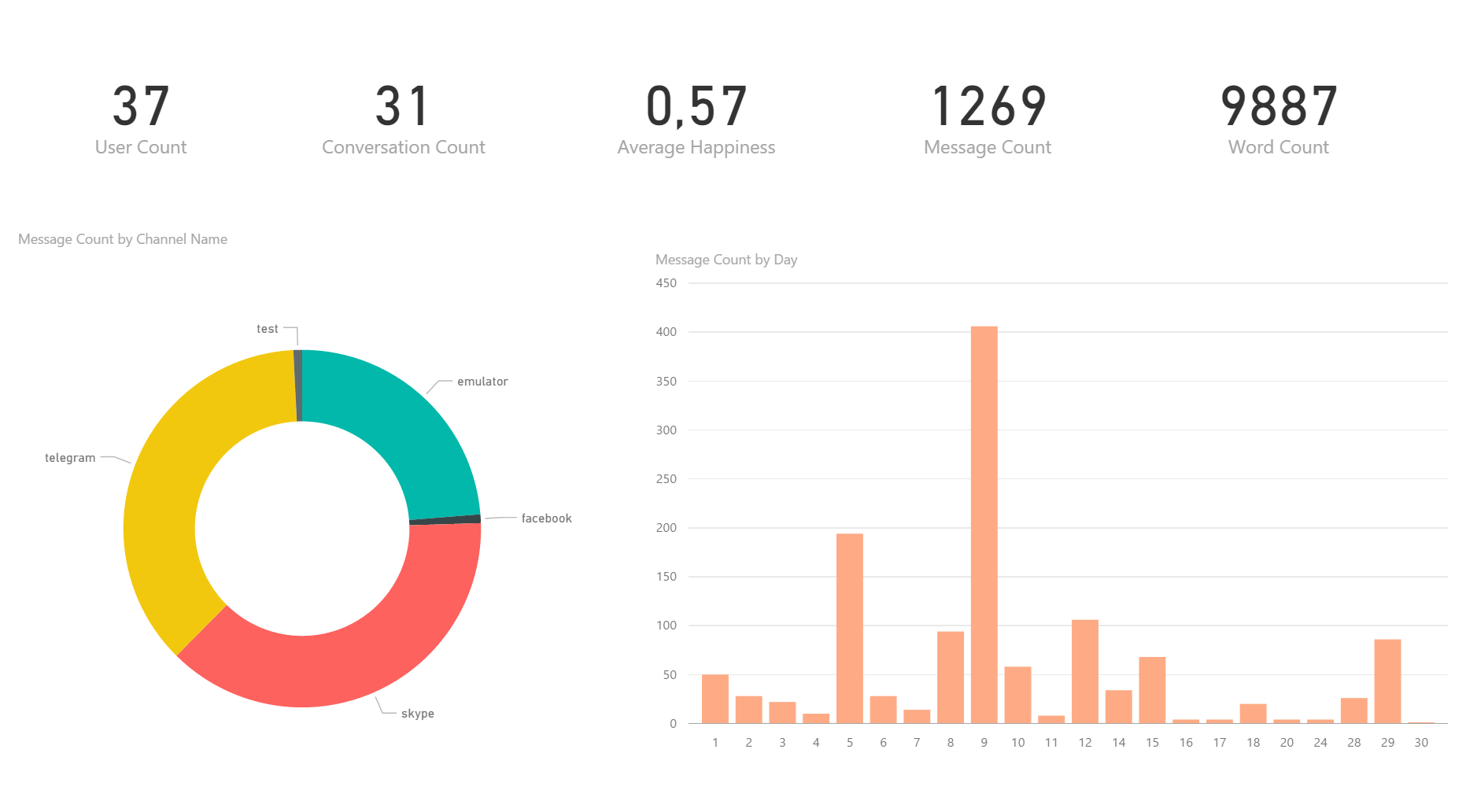
Así por ejemplo, se han visto cosas curiosas. He creado varios reportes para poder visualizar la información. El primero de ellos es una vista general:
Podemos ver la cantidad de usuarios que han interactuado, cantidad de conversaciones, felicidad media, mensajes, palabras y canal empleado. Lo bueno de PowerBI es que puedo hacer click sobre una parte del «circulito» de canal o fecha y me filtra todos los datos.
Sin embargo, la parte interesante comienza cuando creo el reporte de felicidad por usuario. Se percibe que los usuarios tienen un sentimiento positivo por la tarde. Durante la mañana están menos positivos, hasta que llega la tarde. A partir de las 20-21h (los datos son de verano) el sentimiento comienza a decrecer:
La gráfica superior izquierda muestra el sentimiento del usuario seleccionado por día y la cantidad de mensajes escritos. La de la parte superior derecha sirve para mostrar la relación entre el tamaño de los mensajes y el sentimiento. Los mensajes más cortos tienen un sentimiento más positivo que los mensajes más largos. Y la gráfica inferior, muestra el sentimiento por horas. Pueden variar los picos por usuario, pero la tendencia es la misma para todos mis usuarios.
El siguiente reporte que monté fue para analizar el resultado de las conversaciones. Si como usuario escribes un texto positivo y el bot te responde mal, tu siguiente respuesta será menos positiva. De un modo u otro, tu respuesta está condicionada por lo que te digan. Esto me resultó muy curioso porque no me lo imaginaba, ya que el contenido del bot era de tono humorístico y no esperaba que pudiese afectar a los usuarios. Sin embargo con los datos que tengo no es así. Es decir, que podría manipular el tono de una conversación sin que el usuario se perciba de ello. Véase la siguiente gráfica:
Se aprecia que una «respuesta» por parte del bot condiciona tu siguiente petición, ajustando tu sentimiento de forma inconsciente.
Conclusión
Hemos visto como podemos montar un bot y analizar cómo son los usuarios que tenemos. Que cada cual saque las aplicaciones que esto tiene y que se aplican hoy día 🙂
Si quieres más información, he dejado en mi GitHub una versión del bot lista para desplegar y probar. Sólo necesitarás:
Tener cuenta de desarrollador en Twitter.
Tener una suscripción de Azure.
Darlo de alta en Microsoft Bot Framework.
Dar de alta el servicio de L.U.I.S. en Cognitive Services.
Con estos datos, rellena los campos en la plantilla parametrizada de ARM. Luego la despliegas y ya lo tienes todo. No debes generar nada, los webjobs se encargarán cuando se ejecuten de generar y rellenar las bases de datos con lo que necesiten para funcionar. Pero por supuesto, hasta que no haya datos de Twitter, el bot no podrá responder nada.
Durante la pasada DotNetConference y después de la charla sobre Async Best Practices de Lluis Franco vino Rodrigo con una serie de curiosidades de los efectos de AsParallel() sobre una colección. Y de esas curiosidades, nace este post.
El ejemplo que comentamos es sencillo. Se trata de calcular cuántos números primos hay de 1 hasta N. Para ello he usado una función sencilla para calcular si un número es primo o no:
static bool IsPrime(int candidate)
{
if ((candidate & 1) == 0)
{
if (candidate == 2)
{
return true;
}
else
{
return false;
}
}
for (int i = 3; (i * i) <= candidate; i += 2)
{
if ((candidate % i) == 0)
{
return false;
}
}
return candidate != 1;
}
Y he creado una lista de enteros hasta N:
var list = Enumerable.Range(1, 10000000);
Quedando la consulta sobre LINQ de la siguiente manera:
var onlyPrimes = list.Where(i => IsPrime(i))
.Count();
Evidentemente esto tiene un coste. Para pocos elementos es prácticamente despreciable, pero si generamos una cierta cantidad de elementos a partir de 1 millón vemos como este se dispara:
Una solución para prevenir este tipo de casos es usar AsParallel(). Este método permite distribuir el contenido de un IEnumerable para que se habilite el procesamiento en paralelo. Es decir, cambiando la sentencia LINQ original por esta obtendremos del tiempo actual de 7,3 segundos a 2,5 para el último caso:
var onlyPrimesParallel = list
.AsParallel()
.Where(i => IsPrime(i))
.Count();
Y juntando los dos tiempos, la gráfica quedaría tal que:
¿Qué efectos produce AsParallel?
Para verlo, usaremos una extensión de Visual Studio que se llama Concurrency Visualizer. Es parecido a los ya conocidos reportes de rendimiento, diagnósticos y análisis sólo que está destinado a mostrar cómo se distribuyen los hilos sobre la memoria y CPU de la máquina. Podemos asociarlo al proyecto en ejecución o asignarle cualquier programa que esté en ejecución.
En el primer caso, que es secuencial, esperamos ver que el hilo de la aplicación se ejecuta en mayor medida sobre uno de los núcleos de nuestro sistema:
Mientras que si vemos el resultado de la opción en ejecución en paralelo obtenemos lo siguiente:
Se puede apreciar fácilmente que hay mucha carga y más procesos que están distribuidos a lo largo de los núcleos.
¿Debemos usar AsParallel?
Bien, antes de responder la pregunta hay que aclarar una serie de puntos. AsParallel no es gratuito. La paralelización no es gratuita. Es costosa. Y Mucho. Para una CPU que no paralaleliza no hay mayor problema, porque entra un proceso y este ocupará el tiempo de la CPU sin importar nada más. Cuando termine devolverá su trabajo y la CPU podrá seguir con otra cosa. Cuando se paraleliza, al coste de las operaciones que se estén haciendo, hay que añadirle el peaje de paralelización. Este peaje es el coste que tiene para el núcleo y el sistema sincronizarse con sus semejantes. Veamos más información del uso de los núcleos en el caso paralelo:
El cambio de contexto es el “peaje” que comenté anteriormente. Supone el proceso que se debe llevar para que los núcleos de la CPU se sincronicen para ejecutar la tarea de forma paralela. Esto implica que en cada cambio de contexto, los registros de los procesadores son guardados y cargados, el kernel del sistema operativo se ejecutará, la TLB (Translation Lookaside Buffer) se recargará y las etapas de instrucciones del procesador finalizará. Es decir, se fuerza prácticamente a que ejecute nuevo código pero con registros ya cargados para que continúe por donde lo dejó la otra etapa paralela. Y le podemos añadir por si fuera poco, que puede ser todavía más costoso para el núcleo si la caché no es válida para el hilo actual. El escenario ideal sería que se paralelice en la justa medida para que todos los núcleos puedan reusar la caché que ya tienen.
Aparecen tres métricas en el reporte:
Cross Core Context Switches: Número de veces que un hilo ha cambiado de un núcleo lógico a otro.
Total Context Switches: Número de veces que se cambia el contexto (de ejecución a sincronización, etc).
Percent of Content Switches: Las dos métricas anteriores divididas (CrossCore / Total Context). Cuando más alto sea el porcentaje, mayor es la actividad del núcleo y del hilo en particular.
Ahora ya podemos responder a la pregunta. Sabemos que es costoso, porque implica un coste asociado por hilo al paralelizar. Así que:
¿Debemos usarlo? Depende. Hay que medir qué aporta y que no aporta. En la segunda gráfica se aprecia que el coste es algo superior al secuencial, pero a medida que crece la lista el coste del paralelo tiene una pendiente con menor inclinación que la secuencial. Otro punto es ver qué hacemos con la paralelización. Si el resultado implica recoger los resultados del proceso, será más caro –como es el ejemplo actual- Si sólo queremos aplicar una operación (cómo hacer una petición HTTP) será más barato. En cualquier caso, hay que medir y probar.
¿Puedo colocar AsParallel donde quiera? Sí, por supuesto. Pero evidentemente eso no significa que funcione como crees que debería funcionar. En la sentencia LINQ actual, AsParallel() está justo antes del WHERE() porque lo que queremos es que distribuya los N elementos de la lista en los núcleos de la CPU y que una vez distribuidos, ejecute el WHERE(). Esto ha sido porque hemos asumido que lo que ejecuta el WHERE() es atómico y costoso. Si por el contrario colocamos AsParallel() después, provocaremos esto:
Sí, efectivamente usa todos los núcleos disponibles. También tarda casi más de 3 segundos que la forma secuencial. Lo que hemos provocado aquí es:
La ejecución de calcular un número primo es puramente secuencial. Es decir, tenemos una lista de N elementos y para cada uno de ellos vamos a determinar es primo o no. Puramente secuencial.
Cuando tengamos todo el resultado, que habrá devuelvo una cantidad X<N de elementos (aquellos que sean primos) aplicamos el AsParallel(). Y la siguiente operación es un COUNT() de forma paralela, por lo que el sistema va a distribuir los X elementos entre los núcleos para poder contarlos y finalmente sumarlos para obtener el resultado final. ¿Es paralelo? Por supuesto, pero de forma incorrecta porque hemos hecho el cálculo de los primos en secuencial y le hemos añadido el sobrecoste de la paralelización para obtener el COUNT. Y además se puede apreciar como el número de cambios de contexto es bastante mayor que la versión paralela correcta, por lo que en lugar de mejorar el rendimiento, lo hemos empeorado con creces respecto a la versión secuencial.
BONUS: DNX
Probando el código de AsParallel() con DNX 4.5.1 (el DNX Core que tengo instalado no soporta AsParallel por el momento) he obtenido un tiempo máximo de 2,2 segundos (0,3 menor que la media –que no máximo-) del ejemplo anterior. Cuanto menos curioso…
Siguiendo la estela del año pasado, este año hemos tenido una nueva edición de la DotNetConference. Es un evento organizado por Microsoft y orientado para todas las comunidades técnicas y desarrolladores que trabajamos con tecnologías Microsoft. Se volvió a batir la afluencia: 1700 personas asistieron de forma presencial y otras 5000 de forma online siguiendo la retransmisión vía streaming.
Tal vez la primera gran diferencia respecto al año pasado es que sólo ha durado un día. En la pasada edición la duración se extendió a dos días, por lo que hubo más espacio y más tiempo entre las charlas. Este año todas las charlas han estado comprimidas en el mismo día, lo cual ha sido un poco caótico porque había que elegir entre ir a la charla o hacer algo de networking. Sin embargo, hay otra pequeña diferencia que sí hemos tenido este año:
Sí señor, Satya Nadella (CEO de Microsoft) pudo asistir al evento e impartir una keynote. Un gran salto de calidad y potencia al evento, porque no todos pueden presumir de tener como ponentes al CEO de una de las mayores empresas de software del mundo. Aquí se ha demostrado el gran trabajo de organización efectuado por el DX Team de Microsoft Ibérica. Supongo que esta noche podrán dormir tranquilos y descansar, porque desde luego se lo tienen merecido después de todo el esfuerzo que han hecho.
Respecto al contenido del evento, otro año más no he asistido a la primera keynote. Tampoco he podido asistir a todas las charlas que me gustaría. Desgraciadamente muchas coincidían en la misma hora pero en distinta sala, así que la elección no fue fácil.
Some dirty, quick and well-known tricks to hack your bad .NET WebApps: Chema Alonso impartió esta divertida y práctica charla sobre pequeñas cosas a tener en cuenta a la hora de desarrollar una aplicación web. Nos demostró, con ejemplos reales y en directo que una mala configuración de servidor (tan simple como dejar los valores por defecto) puede suponer que un atacante que tenga el suficiente tiempo libre nos dé alguna sorpresa. Chema terminó la charla con una frase lapidaria: «Si no revisas los detalles de tu aplicación web no te preocupes, alguien lo hará»
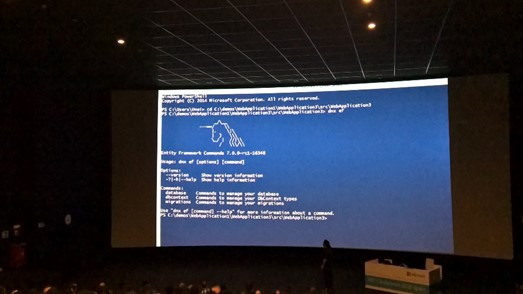
Entity Framework Core 1.0: Unai Zorilla nos vuelve a hacer una demostración que es posible hacer una charla picando código y sin necesidad de IntelliSense. Explicó la motivación que hay detrás de Entity Framework 7 Entity Framework Core 1.0, tanto para aplicaciones Full .NET como para DotNet Core. Hizo hincapié en algunas de las nuevas características que incluye EF 1.0 (que ahora mismo está en RC1) muy interesantes y potentes. Aunque en mi opinión, una gran potencia conlleva una gran responsabilidad. Como último apunte, EF Core 1.0 ha sido reescrito desde cero y no soporta todavía toda la funcionalidad que tiene EF6. Así que entre esos motivos y que todavía está en RC1, no se recomienda su uso en sistemas de producción.
El arte del logging en el Cloud: Luis Guerrero vuelve a marcar una charla espectacular. Contenido y explicación directa. A través de una aplicación que analiza los problemas que puedan aparecer en diversos sitios webs, emplea AppInsights para analizar y obtener la información de lo que va ocurriendo. Porque como él mismo dijo, está muy bien tener un sistema de logging. Pero es mucho más importante tener la capacidad de explotarlo para poder analizar y saber lo que ocurre. Tener un sistema de logging y no poder leerlo o directamente no leerlo, es lo mismo que no tenerlo.
Wearables con C# y .NET: Microsoft Band 2, Apple Watch y Google Wear. Josué Yerai nos explica las diferencias entre Microsoft Band, el Apple Watch y cualquier Android Wear. Algo muy curioso porque todas tienen su propio SDK y aunque parezca sorprendente, la única que dispone de SDK para todas las plataformas es Microsoft Band. A través de un ejemplo mostró cómo funciona realmente las aplicaciones de los wearables y qué podemos hacer con cada uno de ellos.
Mención especial (y no por temas corporativos) me gustaría hacer a mis compañeros de Plain Concepts. Organizaron un concurso a través de un cuestionario de cinco «simples» preguntas de programación en C# que causó furor. No creo que sea por el premio (una Microsoft Band 2 al que acertase las cinco preguntas) sino por el hecho de que es algo que motiva y «pica» para poder investigar y obtener la respuesta correcta. La afluencia al stand de gente rellenando el cuestionario y entregándolo fue constante a lo largo del día, por lo cual considero que fue todo un éxito por la iniciativa de todos los implicados.
Por último me gustaría volver a agradecer a todos la organización, ponentes y patrocinadores la realización del evento. No es sencillo montar un evento de este tipo ni para tanta gente. Y en el fondo, lo importante es que es un evento de comunidad. Una comunidad que está viva y muy activa. Y es algo que en mi opinión, motiva bastante para poder seguir investigando y aprendiendo nuevas tecnologías. Así que: ¡enhorabuena!
Siguiendo con la temática del artículo anterior en el que se mostró cómo crear configuraciones y como aplicar los valores en el web.config para cada una de ellas, en esta ocasión dedicaré el asunto a App.config
¿Por qué lo visto anteriormente no es válido? Técnicamente es válido, pero el problema es que por defecto los app.config no están pensados para soportar transformaciones y los proyectos en los que se encuentran, tradicionalmente de consola o aplicaciones de escritorio, no tienen en cuenta este detalle.
Si se crea un proyecto de consola o aplicación de escritorio en general se aprecia que el app.config no dispone de versión para Debug y Release, pese a que dichas configuraciones sí existen en el proyecto o solución. Por lo tanto, lo primero que se debe hacer es habilitar tantos app.config como configuraciones se disponen.
Como resumen breve, en el post anterior se comenta lo siguiente:
Por un lado, las distintas versiones de web.config son en realidad desde el punto de vista del proyecto ficheros dependientes de otro.
Por otro lado, para poder habilitar las transformaciones es necesario añadir el import correspondiente.
Crear los app.config
Respecto al primer punto la principal diferencia es que debemos crear los ficheros de forma manual, puesto que no tenemos menú disponible para ello. Así pues, si se dispone de la misma configuración que el artículo anterior de cuatro entornos (dev, qa, pre y pro) se creará en primer lugar los app.config equivalentes:
Además cada fichero de configuración se ha creado con una estructura básica por defecto que deberemos preparar. Mientras que la parte original permanece así:
Por lo tanto la estructura de ficheros que queda en el proyecto sería algo muy parecido a esto:
Para que los ficheros pemanezcan jerarquizados en base al App.config original, se debe modificar el csproj indicando que el resto de ficheros que hemos creado por entorno tienen son dependientes del App.config “padre”:
<ItemGroup>
<NoneInclude="App.config"/>
<NoneInclude="App.Debug.config">
<DependentUpon>App.config</DependentUpon>
</None>
<NoneInclude="App.PRE.config">
<DependentUpon>App.config</DependentUpon>
</None>
<NoneInclude="App.QA.config">
<DependentUpon>App.config</DependentUpon>
</None>
<NoneInclude="App.Release.config">
<DependentUpon>App.config</DependentUpon>
</None>
</ItemGroup>
De este modo ya se dispone de un app.config jerárquico al igual que ocurre en un proyecto web:
Trasformación de app.config
Ahora se debe importar la capacidad de transformar el XML. Fácilmente se puede lograr añadiendo la siguiente línea en el csproj:
Ahora podemos modificar el web.config y añadir algo en función del entorno. A modo de ejemplo mantengo el del artículo anterior, por lo que el web.config original quedaría de la siguiente forma:
Si compilamos en QA, se aprecia que no ha aplicado ningún tipo de transfomación y mantiene el web.config original. Aquí tenemos dos problemas:
El proyecto de consola no entiende de transformaciones, somos nosotros quienes las estamos introduciendo casi “a calzador”.
No disponemos de publicación condicionada. En un proyecto web se puede establecer multitud de parámetros que se tienen en cuenta a la hora de publicar, entro ellos la configuración del entorno. Aquí directamente se ofrece la posiblidad de publicar con la única opción de indicar la ruta donde se copiará el resultado de la compilación que en esta opción será siempre Release.
Por lo tanto, lo que se debe hacer es habilitar que tenga en cuenta en la compilación el resto de entornos personalizados que se han ido creando. Para ello se necesita añadir al csproj la siguiente opción post-compilación:
Se añade TransformXML gracias al soporte del Import de Web.Transformation y se transformará todo fichero App.{Entorno}.config. La variable $(ConfigurationName) es una macro predefinida de msbuild que indica cuál es el nombre de la configuración que actualmente está seleccionada. Como se ha seguido el patrón de generar la configuración por entorno (app.debug.config, app.qa.config, etc) podrá encontrar el fichero y de este modo aplicará la transformación. Es decir, gracias a esta tarea de post-compilación se comprobará el efecto de la transformación al compilar el proyecto independientemente o no de la publicación del mismo, justo al contrario que en un proyecto web. Finalmente el app.config para QA quedaría del siguiente modo:
Existen estas opciones en lugar de aplicar el DIY:
Configuration Transform: Es una extensión de VS(2010,2012,2013 por ahora) que añade la funcionalidad que aquí se ha aplicado de forma manual.
SlowCheetah: No he llegado a usarlo pero parece ser que está descontinuado. Hace un año o dos era una buena solución para la gestión de XML en configuraciones.
Fuente:
Basado en esta respuesta de Stackoverflow y experiencias varias
Cuando se desarrolla una aplicación sea del tipo que sea, siempre se incluye un fichero .config donde aparecen datos de la configuración (settings, cadenas de conexión, configuración de dlls, versiones específicas de dlls, etc). Si estamos en una aplicación web tendremos un fichero web.config y si estamos en otro tipo de aplicación se llamará app.config.
Creando entornos
Normalmente en web se trabajan con múltiples entornos al desplegar. Podemos disponer de un entorno de desarrollo, de un entorno de QA/test, de un entorno de preproducción y finalmente de un entorno de producción. Normalmente a cada entorno se corresponde una configuración de despliegue distinta, porque tendrán settings o cadenas de conexión distintas.
Cuando creamos un proyecto web, automáticamente nos genera un web.config. Sin embargo podemos apreciar que nos genera dos ficheros: uno para Debug y otro para Release:
Lo cual en el csproj se traduce de la siguiene forma:
<ContentInclude="Web.Debug.config">
<DependentUpon>Web.config</DependentUpon>
</Content>
<ContentInclude="Web.Release.config">
<DependentUpon>Web.config</DependentUpon>
</Content>
Y para generar esos ficheros, la plantilla de VS se basa en la configuración de la solución que exista. Por defecto se crean dos configuraciones: debug y release para cada uno de los proyectos integrados en la solución:
Lo cual nos permite crear rápidamente tantas configuraciones como necesitemos. Además, podemos crearlas basándonas en otras ya existentes:
Y una vez creadas, nos situamos encima de Web.Config y ya Visual Studio nos sugiere que podemos añadir nuevas configuraciones:
A partir de este momento, cuando se publique la aplicación se aplicará la transformación de web.config a la configuración seleccionada. Es decir, los efectos del web.config sólo tienen validez una vez se ha desplegado la aplicación, por lo que no es posible probarlo si desde el propio Visual Studio cambiamos la configuración al ejecutar/probar.
Transformaciones
Si disponemos de un web.config base,compilamos y desplegamos con una solución determinada (Debug, Release o cualquier otra que se haya creado de forma previa) este se transformará. ¿Cómo? Si se presta atención al csproject del proyecto, se importa una extensión de msbuild:
Esta extensión permite que después de la compilación, se aplique el web.config original y después se apliquen las transformaciones que se hubieran definido en la configuración específica de cada entorno.
Pero ¿qué es una transformación? Es una alteración del web.config base para insertar, eliminar o modificar parte de la estructura del XML. Véase en detalle una configuración de Release por ejemplo:
Véase el uso del namespace de XML-Document-Transform. Este habilitará las instrucciones necesarias para las trasformaciones. Las más comunes suelen ser las relativas a la substitución de un atributo XML, añadir un nuevo nodo o reemplazarlo por otro. Los atributos que se usarán serán los siguientes:
Transform: Indica la naturaleza de la operación: Replace, Insert, InsertIfNotExists, etc.
Locator: Si necesitamos localizar el nodo para una sustitución, se indicará aquí el nombre del atributo que se usará a tal efecto.
Por ejemplo, si se tiene una sección de appsettings en el web.config base tal que:
<appSettings>
<addkey="environmentName"value="none"/>
</appSettings>
En un hipotético web.QA.config sería del siguiente modo:
<appSettings>
<addkey="environmentName"value="QA"
xdt:Transform="Replace"
xdt:Locator="Match(key)"/>
</appSettings>
En el cual indicamos en Transform que se desea aplicar un Replace en aquel nodo cuyo atributo Key sea “environmentName”. Así al publicar la aplicación en con la configuración de QA, se aplicarará esa transformación.
También se puede reemplazar un nodo completo, en cuyo caso no se indicaría el atributo locator. Mientras que en un web.config base no aparece este nodo, podemos insertarlo en cuaquier transformación:
El fin de semana pasado tuvo lugar el Freakend 2015. Es una reunión en una casa rural en la que nos juntamos diferentes personas pero con un mismo objetivo: nuestra pasión por los videojuegos.
48 “frikis” de los videojuegos entre los que contaban desarrolladores, artistas, productores y aficionados como un servidor entre los que su dedicación profesional no son los videojuegos en estos momentos. La idea como siempre es organizar charlas en base a la experiencia de cada uno. Todo el fin de semana estuvo repleto de charlas muy interesantes y de diversos ámbitos: desde la experiencia de hacer un kickstarter hasta cómo programar juegos con C# y GameBoy. Tanto era el interés que cada uno de nosotros venía de una ciudad distinta o incluso de algún país extranjero para poder asistir.
Tuvimos con la presencia de lo que para mí son grandes leyendas del desarrollo de videojuegos en España, como José Rauly de Mercury Stream o Unai Landa (Digital Legends y ex-Pyro), Sergi Vargas, Jesús Martínez y una lista de enorme calidad en la que me demostró de nuevo lo mucho, muchísimo que tengo que aprender todavía. También se apuntó a la fiesta David Bonilla y nos contó de primera mano su experiencia con Otogami, el famoso buscador de juegos online que te encuentra siempre el mejor precio.
¿Lo mejor del evento? Sin duda alguna, la gente y el hecho de poder compartir experiencias. Si hay algo que adore de este tipo de eventos es que me permite salir de la burbuja de mi trabajo diario y conocer profesionales de otras tecnologías y ámbitos que nos permiten intercambiar conocimientos y opiniones. Se nota y se percibe cuando hay comunidad, pasión y ganas por hacer las cosas bien hechas. Y pese a ser muchos de distintos ámbitos, tuve esa fantástica sensación. Después de cada charla hubo numerosos debates comentando aspectos de la misma y relacionados, con lo que se pudieron compartir numerosas opiniones muy valiosas. También como ocurre en estos casos, al acabar las charlas del día nos juntamos varios en corillos comentando cualquier cosa: desde el estado de la industria, aspectos profesionales, técnicos o directamente qué juegos nos han gustado más.
Como punto original, tuvimos a los GameYourHear que además de asistir al evento nos deleitaron a las 3 de la mañana con unas cuantas canciones en riguroso directo de videojuegos.
Y como siempre estuvimos bien alimentados en base a lo que necesita el cuerpo:
Por último (y no menos importante) quiero agradecer a Diego y Jorge todo su esfuerzo y empeño para lograr coordinar tanta gente para un evento que ha salido redondo. Sé que han terminado muy cansados y agotados, con toda la razón del mundo. Pero no me cansaré de repetirlo: GRACIAS por hacer cosas como estas.
P.D: Como suele ser habitual, tuvimos algún invitado especial que no se perdió el evento:
El pasado fin de semana tuvo lugar en la universidad de Alcalá de Henares la DotNet Spain Conference 2015. Fue un evento espectacular y que se echaba en falta.
Desgraciadamente no pude asistir a la keynote ni a las primeras charlas, así que voy a comentar sobre lo que sí tuve ocasión. También desgraciadamente no me pude desdoblar para asistir a más de una charla o taller a la vez, porque había varías a la misma hora y en distintos tracks muy interesantes. Vaya por delante mi agradecimiento a todas las personas implicadas en la organización de tal magno evento en el que hubo 1000 asistentes y otros tantos virtuales siguiendo las charlas y talleres de forma online. Se echaba en falta un evento donde la comunidad .NET podamos juntarnos y compartir nuestras experiencias, ya que si por alguien lo dudada existimos
Tengo mi aplicación en el cloud y no escala: ¿Qué hago? En esta charla Quique Martínez nos cuenta experiencias reales de clientes que han querido llevar sus aplicaciones on-premise a la nube y los problemas que han tenido. Muy útil para conocer las implicaciones de una decisión que no se debe tomar a la ligera.
Complex Event Processing con Event Store: Marçal Serrate nos cuenta cómo modelar y usar un EventStore de una forma muy curiosa. Mostró un ejemplo usando la api de GitHub, en el que extrajo estadísticas de los lenguajes más usados en función de los commits. Después usó Event Store para analizar los comentarios y mostrar estadísticas de en qué lenguajes se incluyen más palabras mal sonantes. Muy curioso.
Sube tu Universal App al Cloud: Aquí asistí a medias, pero Adrían Fernández nos cuenta cómo desarrollar una universal app de ingredientes de hamburguesas y subir la api correspondiente a Azure.
MongoDB en Azure para programadores de .NET: Aquí Francesc Jaumot nos cuenta una introducción sobre qué es Mongo Db y cómo integrarlo dentro de una aplicación .NET.
Async best practices: Lluis Franco y Alex Casquete explican en profundidad la evolución de asincronía en todas las versiones del framework: desde eventos y delegados hasta el async/await. Estuvo bastante bien porque contaron algunos temas sobre la parte interna de la gestión de tareas dentro del framework.
Code Smells: Fernando Escolar nos ilustra sobre aquellos fragmentos de código que nos persiguen durante la noche y lo más profundos de los sueños cual orcos buscando oro y plata. Código que todos hemos escrito alguna vez y no está bien y cómo corregirlo haciendo que quede más elegante y funcional.
Por qué deberías plantearte F# para tu próximo proyecto: Una charla introductoria sobre F# y lenguajes funcionales que impartió Alex Casquete. Promete, porque ya hay una comunidad creciente de usuarios en F# en Madrid y Barcelona que en un futuro no muy lejano nos contarán cosas muy molonas…
Let’s Fight !!! Arduino vs Netduino vs .Net Gadgeteer vs Galileo: La verdad es que asistir a un evento de este calibre y no asistir a una charla de Bruno debería ser motivo de castigo. Nos explicó las múltiples alternativas de IoT, tanto de .NET como de C y las comparó en base a su experiencia. Muy interesante porque es un mundo que apasiona a la vez que asusta.
Gestión masiva de datos en la era IoT: Cuando empezamos a capturar datos con nuestros sensores de IoT, ¿qué hacemos con ello? Luis Guerrero nos propone usar Azure Stream Analytics con una charla interactiva en la que mediante Twitter fuimos viendo el resultado y análisis de los Twitts que cada uno de nosotros mandó.
Algunas que me hubiera gustado ir son CloudFirst, Visual Studio Online, Effective C#, el taller de Machine Learning, Release Management, Galileo y el IoT, Cloud Hardcore Debugging… Lo interesante de este tipo de eventos es que permite explorar áreas y conocimientos que en tu día a día es prácticamente imposible que alcances. Ya de por sí es interesante conocer áreas nuevas, pero todavía más es encontrarme con gente de la comunidad, antiguos y nuevos MSP’s e incluso algún amigo y compañero de clase en la universidad.
Por último, de nuevo me gustaría agradecer a TODA la organización su esfuerzo y dedicación para lograr un evento muy interesante y que me ha traído a la memoria aquellos eventos grandes de hace años donde todos nos reuníamos. Espero que el año que viene podamos disfrutar de una nueva edición. Hasta entonces, simplemente ¡mil gracias!
Hace ya varios años que tomé la decisión de descartar cualquier temática no técnica para los blogs y dejar a un lado las ideas o pensamientos que pudiera tener, inclusive aquellos relacionados con las propias materias técnicas. Sin embargo, hay ocasiones que a veces la parte técnica no es mostrar qué fragmento de código, qué framework o qué tecnología he usado para resolver un problema. Una idea, un matiz o una sugerencia pueden dar con la pista y abrir un nuevo mundo de posibilidades.
Ayer en La 2 (sí, veo La 2, ¿qué pasa?) emitieron un documental sobre la construcción del Rover Curiosity que desde el punto de vista ingenieril es muy pero que muy interesante:
Considero que la formación recibida como ingeniero informático ha sido satisfactoria; aunque como todo en la vida, puede ser mejorable en algún campo más que en otro. Recuerdo todavía casi como si fuera ayer, las clases en las que nos enseñaban metodologías de gestión de proyecto y un poquito de tareas más o menos relacionadas pero sin entrar en profundizar (algo de pruebas, algo de gestión de personal, algo de estimación, algo de arquitectura, etc) lo cual me debería llevar a tener una cierta visión del Mundo Real para poder sobrevivir en él.
Sin embargo, tengo muchísimas lagunas, de las que poco a poco (bien aprendiendo despacito o generalmente mediante palos) voy consiguiendo rellenar. Hoy voy a hablar de pruebas. En el documental podrás ver algunas de las pruebas a las que someten al Rover Curiosity y a algunos de sus elementos. En la carrera me enseñaron poco de pruebas y es algo que debería ser desde mi punto de vista algo fundamental en cualquier ingeniería.
P & P: Hacer Pruebas es de Pobres
Probar debería ser lo más normal del mundo. Metodologías como TDD y BDD se centran precisamente en probar lo que hace desde distintos puntos de vista. ¿Quién no ha oído hablar de TDD? ¿Quién no ha visto una charla/evento sobre TDD? ¿Quién aplica TDD? Ah amigo…
La ingeniería del software es una (¿ingeniería?) muy reciente. Los fundamentos matemáticos de la computación moderna (sin desmerecer a pioneros como Ada, Pascal, Baggage e incluso el misterioso mecanismo de Anticitera) nace a partir de 1920-30, de la mano de científicos como Von Neumann o Turing. A partir de ahí, el ritmo de desarrollo de la ciencia de la computación va cobrando un camino vertiginoso hasta nuestros días en los cuales la tecnología avanza a un ritmo que difícilmente podemos seguir. Nos hemos acostumbrado a servicios como Facebook, Youtube, Gmail/Hotmail, la nube… todo el mundo los conoce y parece que siempre han estado ahí. Parece, porque realmente alguno ni siquiera tiene 10 años.
Este rápido avance provoca que las disciplinas tengan que adaptarse casi a paso cambiado. Otras ingenierías como la civil, industrial o química llevan décadas, siglos e incluso milenios de desarrollo con lo cual sus procesos están asentados, depurados y aceptados. Nosotros todavía estamos discutiendo qué metodología es mejor o más adecuada porque, sencillamente es un mundo cambiante al cual tenemos que adaptarnos y proponer constantemente alternativas y soluciones para poder sobrevivir.
Todo lo que usamos a diario ha sido sometido a multitud de pruebas. Desde nuestra casa, el coche (con sus famosas pruebas de airbag), carreteras, puentes… Hasta el teclado sobre el que escribo este texto ha sido sometido a durísimas pruebas para estimar cuánto tiempo debe durar y proporcionar un funcionamiento correcto bajo una serie de condiciones.
¿Ocurre lo mismo con el software? Desgraciadamente, no. Las excusas son variopintas y todos, YO el primero, las hemos pronunciado alguna vez:
No tengo tiempo para hacer pruebas.
Hacer pruebas no sirve para nada.
No sé cómo probar esto.
Paso de hacer pruebas; esto funciona de lujo.
Hay pruebas, pero no funcionan.
etc…
Justificadas o injustificadas, son excusas. Y son excusas porque hay solución a cada una de ellas:
“No hay tiempo para hacer pruebas” : El 95% de los clientes van a preferir una entrega que les funcione en un alto porcentaje de la funcionalidad contratada antes que una bomba nuclear inestable en sus manos.
“No sirve para nada” : Respirar tampoco, fíjate.
“No sé como probar esto”: A esta la respondo más abajo.
“Paso de hacer pruebas; esto funciona de lujo” : Explotará. Y lo sabes. ¿El motivo? Salvo sorpresa, somos humanos, no máquinas autómatas y cometemos errores. Es normal, cotidiano y predecible. Pero podemos intentar que sea menos cotidiano cada vez.
“Hay pruebas, pero no funcionan” : Simple. Si no sirven, se quitan. Y si no, se adaptan. Respondo más abajo también.
Podemos agrupar las excusas en tres tipos:
Timing: No se puede dedicar tiempo pese al riesgo que conlleva. Y si conocemos y aceptamos los riesgos, adelante.
Pereza: Poco podemos hacer aquí…
Conocimientos: Esta es la buena y la más importante.
TDD es una metodología con una curva de aprendizaje inicial muy dura, porque exige un cambio de paradigma mental a algo que no estamos acostumbrados. Normalmente estamos (mal) acostumbrados a programar, arrancar y probar. Si falla, vemos qué falla y vamos a corregirlo hasta que quede listo. Sin embargo no hace falta aplicar TDD/BDD/{ponga usted su favorita} para hacer pruebas. ¿Cuánto tiempo se pierde en parar, cambiar y arrancar? ¿Cuántos pasos hay que dar para volver a ejecutar la prueba? ¡Automaticemos todo esto en la medida de posible!
Probar antes ejecutar la aplicación te puede ayudar con las siguientes capacidades:
Adquirir un mayor conocimiento de lo que estás haciendo.
Te permite centrarte en una sola cosa y descartar el resto de tareas relacionadas.
Te proporciona una visión muy clara de la funcionalidad.
Averiguar, probar y acotar comportamientos que no estaban contemplados en un principio.
Mejorar el código descubriendo las dependencias, acoplamientos, etc que estaban ocultos.
Descubrir funciones o métodos que deberían/no deberían existir
etc…
Precisamente una de las bazas de hacer pruebas es el refactor una vez se ha probado para que cada vez el código sea más claro, limpio y conciso respetando la funcionalidad. Y bueno, eso es simplemente (simplificando mucho, claro) teniendo una prueba que represente la validación de un requisito. Podemos cambiar el código, o lo que haga pero sabemos que el test va a recibir una entrada X y devolverá una salida Y. Si eso no ocurre, es que algo hemos roto. Se trata de seguridad. De tener la seguridad empírica, con el paso del tiempo, que el desarrollo y su avance no rompe nada de lo que funcionaba anteriormente.
Be water, my friend
Nadie nace sabiendo y parece que lo olvidamos demasiado a menudo. Reconocer la ignorancia de algo es la primera piedra de conocimiento de ese algo, porque es el momento en que nos planteamos en el subconsciente una necesidad de aprendizaje que anteriormente no se nos presentó.
Probar es algo que supone esfuerzo, especialmente al principio. Y al final también. Las primeras pruebas son feas, mal hechas, desorganizadas, acopladas… y poco a poco, a medida que se van haciendo se mejora. Porque el único método de aprender a hacer pruebas es haciéndolas. Podrás leer muchos libros, consultar o tener mucha referencia a recursos, pero hasta que no te sientas frente al lienzo en blanco no aprenderás a hacer pruebas. Y con la experiencia y la multitud de recursos disponibles (libros, github, blogs) se irá refinando el proceso cada vez.
En un campo en que la tecnología cambia cada 6-18 meses y los requisitos también, no nos queda otra que adaptarnos y cambiar continuamente. Si cambian los requisitos, cambian los tests que deben validarlos. Es una exigencia continua de un flujo continuo…
Para la mayoría de proyectos en los que he trabajado en mi vida profesional, me tomo los despliegues y entregas con demasiado estrés. Intento que todo lo que pueda hacer en función de mis conocimientos esté bien: build etiquetada, todos los tests de todos los tipos pasando, despliegue controlado por si hay que hacer rollback en cualquier momento, bakcups de todo… Son momentos críticos para cualquier sistema porque implica que durante ese tiempo, lo que sea que se esté desplegando no está disponible y hay que asegurar que el despliegue no rompa nada de la versión antigua. Porque en última instancia, podemos hacer rollback y estaremos en una situación de estrés por solventar la incidencia en el menor tiempo posible… pero al menos efectivamente, se puede solucionar.
A veces pienso en la cantidad de pruebas que hacen los ingenieros de NASA, ESA, EADS como el del Rover Curiosity y la presión que deben sentir (proyectos de 2.000 millones de € que dependen de un cable de 8€, por ejemplo) para que todas las pruebas y toda la casuística posible quede demostrada y ejecutada, intentando no dejar nada al azar. Porque una vez el robot ha sido lanzado y está en Marte, no hay vuelta atrás ni solución si ocurre algún problema*. Y eso, como ingeniero no hace más que producirme la más absoluta admiración.
Hay casos en los que por mucho que se sigan las mejores prácticas, por mucho que queramos habrá una parte en la que no tenemos control sobre lo que ocurre. Son cosas inevitables. Pero todo aquello que podamos hacer a nivel de pruebas para garantizar la estabilidad, seguridad y calidad de nuestro trabajo, hagámoslo. Afortunadamente disponemos de la tecnología para que en la mayoría de casos podamos replicar los entornos de producción/despliegue de forma bastante fidedigna, lo que permitiría reducir el riesgo de un despliegue. Este tipo de capacidades no las tiene la industria aeroespacial ni muchas otras, por lo que deberíamos usar las herramientas disponibles para minimizar riesgos y asegurarnos los menores problemas posibles. Porque, a fin de cuentas es una inversión a largo plazo que siempre sale muy, pero que muy rentable.
* Algunos gazapos de la industria aeroespacial derivados de NO hacer las pruebas suficientes:
Ariane 5: No se probó el sistema de cálculo de la aceleración hasta el día del lanzamiento. Este sistema venía derivado del Ariane 4 y funcionaba perfectamente, pero no se probó sobre un Ariane 5. Resultado: el piloto automático no interpretó los datos correctamente ya que se produjo una excepción de punto flotante, obligando a los ingenieros de control a autodestruir el cohete ya que el desvío de trayectoria podría haber provocado una auténtica catástrofe.
Mars Climate Orbiter: Parte del software de tierra hablaba en millas mientras que otra parte en metros. Resultado: se enviaron datos incorrectos a la nave, no ajustó el ángulo y distancia correcta para situarse en la órbita de Marte. Quedó carbonizada al tomar contacto con la atmósfera marciana.