
Aunque en un artículo anterior de este mismo blog ya hemos abordado la creación de un modelo de datos en PowerPivot, en esta ocasión el objetivo consiste en hacerlo desde una perspectiva que tenga en cuenta aquellos aspectos relacionados con la optimización de las operaciones de carga de datos y posterior consulta del modelo desde una tabla dinámica de Excel, proporcionando algunas recomendaciones sencillas, pero efectivas, que nos ayuden a conseguir un mejor rendimiento y mayor velocidad de ejecución.
A partir de este momento, el resto de apartados muestra la manera de enfrentarnos al desarrollo de nuestro modelo de datos, describiendo algunos trucos y técnicas que pueden ayudarnos a mejorar sus tiempos de respuesta, redundando en una mayor agilidad en la toma de decisiones y rapidez en la construcción de informes que nos permitan conocer el estado de la organización.
Identificar el objetivo del modelo
Partiendo de la base de datos AdventureWorksDW de SQL Server, que utilizaremos como fuente de datos de ejemplo en la construcción de nuestro modelo de datos, supongamos que necesitamos calcular el importe que han supuesto las ventas de productos por categoría y periodos temporales (año de la fecha de factura), así como la cantidad de clientes que han realizado las compras. En este último caso, además de mostrar la cifra de clientes por el año de emisión de la factura, también debemos clasificarlos por su estado civil, contando a cada cliente una sola vez por año de facturación, es decir, aunque un determinado cliente, dentro de un mismo año, pueda haber realizado más de una compra, el recuento solamente tendrá en consideración una única vez a cada cliente.
Un pequeño ajuste en el origen de datos
Con el fin de poder demostrar más cómodamente en un próximo apartado la creación de relaciones en el modelo de PowerPivot, en primer lugar vamos a eliminar las claves ajenas existentes en la tabla FactInternetSales de la base de datos AdventureWorksDW. Desde SQL Server Management Studio seleccionaremos cada una de las claves y pulsaremos la tecla Supr, o también podemos usar el panel Object Explorer Details, donde seleccionaríamos todas las claves, eliminándolas en una sola operación.
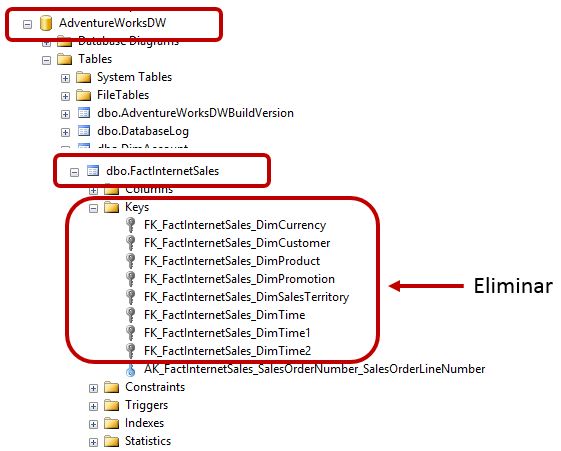
Tablas de datos y tablas de búsqueda
En un modelo de datos de PowerPivot, las tablas a partir de las cuales construimos las medidas (campos calculados) que utilizaremos para analizar el estado de nuestra organización reciben también el nombre de Tablas de Datos (Data Tables). Por otro lado, las tablas utilizadas para filtrar la información, mediante las cuales obtenemos diferentes resultados en función de los criterios de filtro aplicados, se denominan Tablas de Búsqueda (Lookup Tables). Ambos tipos de tablas se relacionan mediante columnas clave, siendo esta la característica que proporciona a PowerPivot su potencia de análisis al visualizar el modelo desde una tabla dinámica de Excel o mediante elementos gráficos de PowerView. Esta y otras muchas características interesantes se describen en una ficha de referencia rápida del blog powerpivot(pro) para algunos de los aspectos principales de esta tecnología.
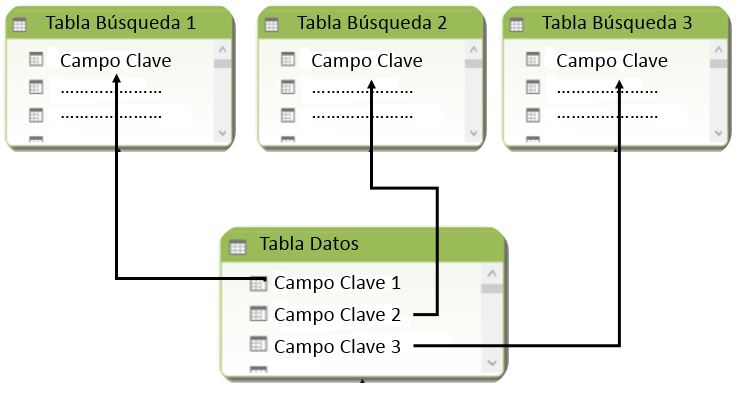
Para aquellos lectores con experiencia en el desarrollo de cubos de datos multidimensionales (cubos OLAP), los conceptos de Tabla de Datos y Búsqueda en PowerPivot se identifican respectivamente con los conceptos de Tabla de Hechos y Dimensión en el entorno multidimensional.
Selección de las tablas a importar
Según los requerimientos planteados en el apartado anterior, comenzaremos por el cálculo del importe de ventas anuales, identificando las tablas FactInternetSales y DimTime como aquellas necesarias para obtener este indicador. Así pues, crearemos un nuevo archivo Excel al que llamaremos VentasClientes.xlsx, y abriremos la ventana de administración de PowerPivot, situándonos en la pestaña del mismo nombre y haciendo clic en la opción Administrar.

Una vez posicionados en dicha ventana iniciaremos el asistente para importar datos desde SQL Server.
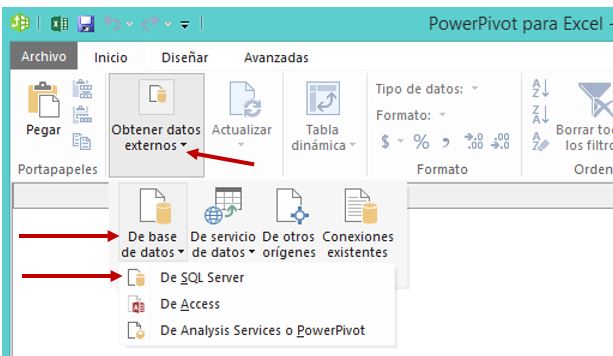
En el primer paso del asistente facilitaremos el nombre del servidor SQL Server al que nos conectaremos y la base de datos de la cual importaremos contenidos.
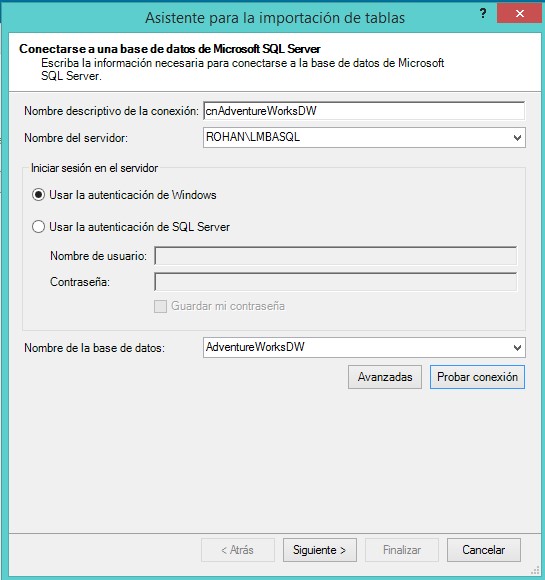
En el siguiente paso elegiremos como modo de importación la selección en una lista de las tablas y vistas a importar.
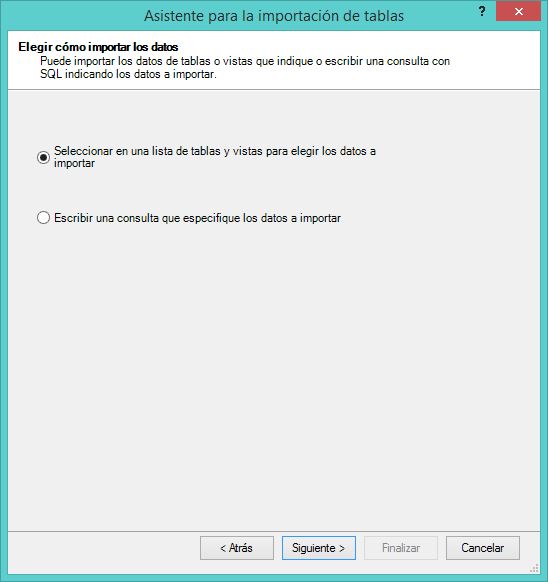
A continuación marcaremos las tablas a importar: FactInternetSales y DimTime,
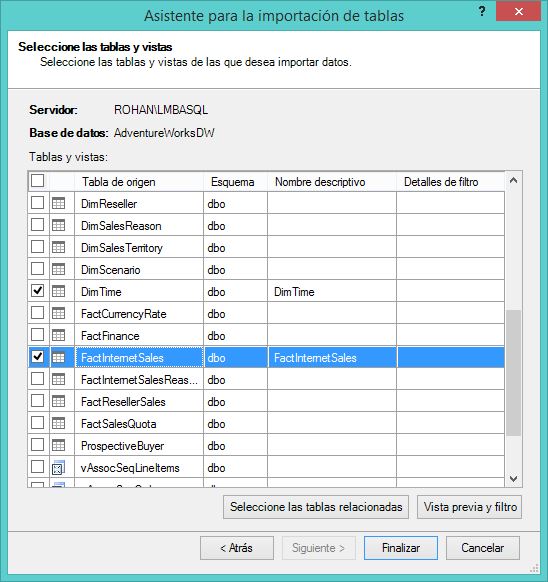
Haciendo clic en Finalizar se realizará la importación de los datos, y tras aceptar la ventana final del asistente, obtendremos dos nuevas pestañas en la ventana de PowerPivot que identificarán a cada una de las tablas añadidas al modelo.
Creación de medidas
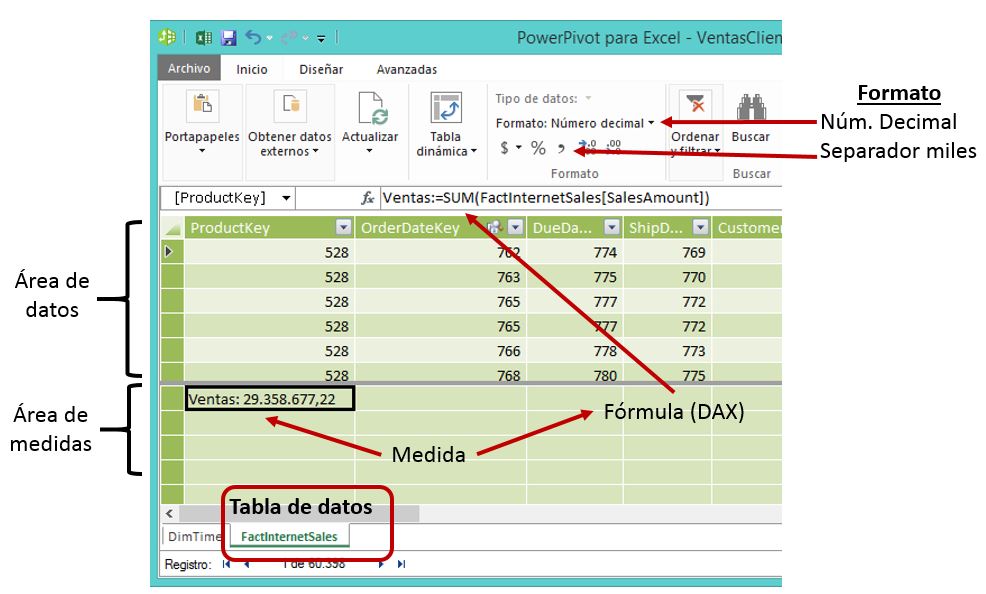
A continuación crearemos, mediante la siguiente expresión en lenguaje DAX, la medida Ventas, encargada de sumar los importes de las facturas emitidas a los clientes, empleando la función SUM y la columna SalesAmount de la tabla de datos FactInternetSales.
Ventas:=SUM(FactInternetSales[SalesAmount])
Para crear esta medida (o campo calculado), en la ventana de PowerPivot seleccionaremos una celda libre en el área de medidas de la tabla FactInternetSales, escribiendo su fórmula en la barra de fórmulas, al igual que hacemos en la ventana tradicional de Excel. Adicionalmente podemos aplicar un formato que en este caso servirá para mostrar el valor como numérico decimal con separador de miles.
¡No sin mi relación!
Después de crear esta medida podemos vernos tentados de consultar las cifras de ventas por año. Haciendo clic en la opción Tabla dinámica del menú Inicio, añadiremos desde la ventana de PowerPivot una tabla dinámica a la hoja de cálculo actual o a una nueva.
A continuación, en el panel Campos de la tabla dinámica, desplegaremos la lista de campos de la tabla DimTime, haciendo clic en la casilla del campo CalendarYear, que se situará en el área Filas (si no fuera así, arrastraremos el campo hasta dicha área). De igual forma procederemos para la tabla FactInternetSales, esta vez con la medida Ventas, que situaremos en el área Valores.
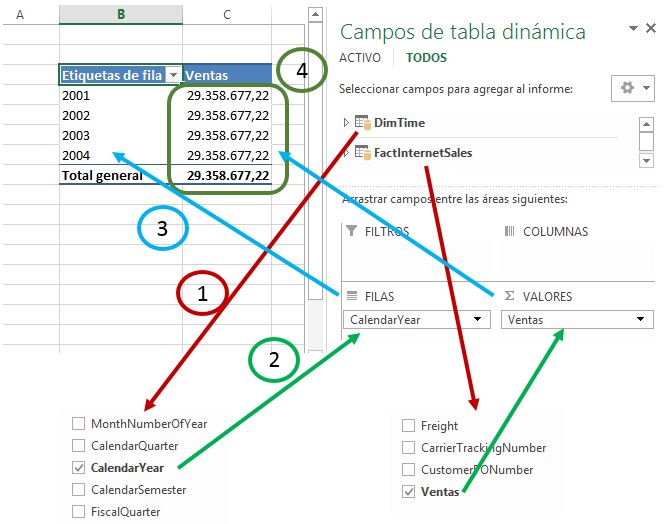
Sin embargo, como podemos apreciar, el resultado no es el esperado, ya que todas las celdas de valores de la tabla dinámica muestran el mismo dato: el total de la medida Ventas (suma total de la columna SalesAmount del modelo).
¿Por qué esta medida no muestra la suma de los importes de las ventas con la cifra que le corresponde para cada año? Pues porque no hemos establecido una relación entre la columna OrderDateKey de la tabla FactInternetSales y TimeKey de la tabla DimTime. Este motivo hace que el motor de PowerPivot desconozca cuántas ventas se atribuyen a cada año, y por consiguiente se ve imposibilitado para realizar esta suma por periodos de tiempo. Hasta el propio Excel en el panel Campos de tabla dinámica nos advierte de tal circunstancia.
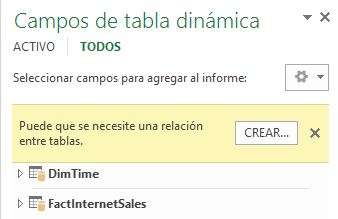
Establecer relaciones entre las tablas
Para evitar el problema que acabamos de exponer y obtener valores consistentes por cada año de venta debemos crear una relación entre los campos mencionados en el apartado anterior.
Esto lo conseguiremos desde el menú Diseñar de la ventana de PowerPivot, utilizando las opciones Crear relación o Administrar relaciones, del grupo Relaciones.
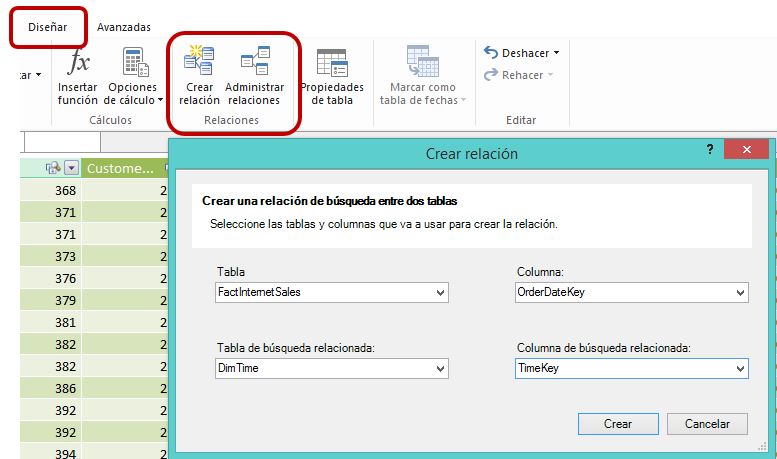
Alternativamente, también podemos establecer una relación mediante la opción Vista de diagrama del menú Inicio, en el grupo de opciones Ver; arrastrando, desde la tabla de datos, la columna origen de la relación hasta la columna destino en la tabla de búsqueda.
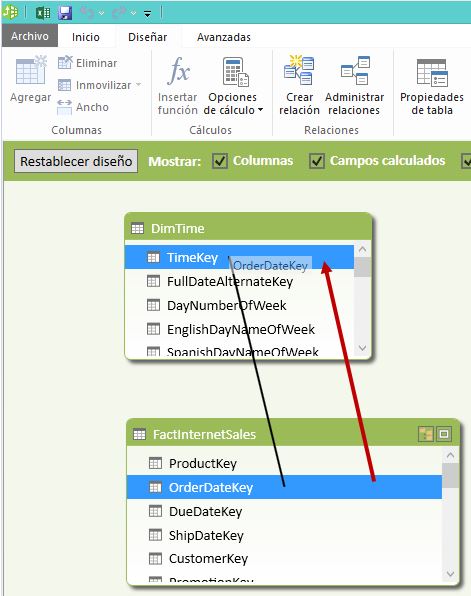
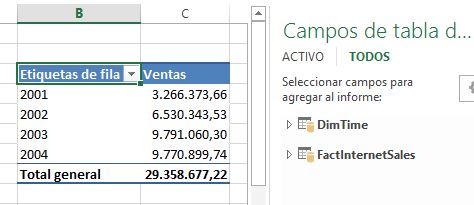
Creada la relación, la tabla dinámica mostrará los valores de la medida Ventas correctamente por año de factura.
¿Importar todas las tablas de una vez o hacerlo progresivamente?
Revisando el enunciado de requerimientos comprobaremos que aparte de las tablas que ya hemos incorporado al modelo vamos a necesitar añadir tablas adicionales (más concretamente DimCustomer y una combinación de las tablas DimProduct, DimProductCategory y DimProductSubcategory) para poder elaborar todos los indicadores solicitados. Entonces ¿por qué no hemos añadido dichas tablas en el proceso de importación anteriormente explicado?
La respuesta a esta pregunta se halla en una simple motivación pedagógica. Podemos importar todas las tablas que vaya a precisar nuestro modelo en un único paso, o bien hacerlo progresivamente, no hay una norma rígida al respecto. En nuestro caso nos hemos decantado por esta última opción, pero todo depende de las características del modelo a desarrollar. En ciertas ocasiones dispondremos de todas las fuentes de datos necesarias para cargarlas en PowerPivot, y habrá otras situaciones en las que el modelo irá evolucionando y no tendremos posibilidad, en sus fases iniciales, de incorporar todos los datos, pero sí los suficientes como para empezar a trabajar en ciertas parcelas de información. También es posible que aunque tengamos todos los datos a nuestra disposición, dada la complejidad del modelo a desarrollar, optemos por construirlo gradualmente.
Sea cual sea la estrategia de importación que sigamos, es muy importante tener presente que siempre debemos ceñirnos única y exclusivamente a los datos con los que realmente vayamos a trabajar.
El objetivo en este sentido es doble: por un lado optimizamos el tamaño del modelo y por otro agilizamos el rendimiento de las consultas que debe ejecutar el motor de PowerPivot. En el siguiente apartado detallamos un poco más este aspecto.
Importar solamente las tablas y columnas que vamos a utilizar
Al trabajar con la tabla dinámica de nuestro ejemplo nos habremos percatado de la numerosa cantidad de campos que cada una de las tablas del modelo pone a nuestra disposición.

Esto, que a priori parece una ventaja (más campos, ergo más posibilidades de filtro, análisis, etc.) puede volverse en nuestra contra si no diseñamos adecuadamente la estrategia de carga de datos al modelo, dadas las particularidades que en este sentido presenta PowerPivot.
xVelocity (inicialmente denominado VertiPaq), el motor de PowerPivot (y también de los modelos tabulares de SQL Server Analysis Services), es una tecnología para el análisis de información con un motor de almacenamiento basado en columna, que gracias a una serie de algoritmos de compresión, y a la realización de sus operaciones de manipulación de datos en memoria, logra excelentes rendimientos en el tratamiento de datos de tamaños muy variados (desde unos pocos miles hasta varios millones de registros).
Sin embargo, si queremos llevar a buen puerto el desarrollo de nuestro modelo, debemos analizar cuidadosamente qué contenidos de los orígenes de datos necesitamos importar, así como su cantidad. Esta cuestión se hace, si cabe, más relevante cuando se trata de la tabla de datos, puesto que habitualmente este tipo de tabla contiene, con diferencia, un número mayor de registros y columnas que las tablas de búsqueda.
En cualquier caso, se trate de tablas de datos o búsqueda, como recomendación general, debemos seleccionar exclusivamente aquellas columnas que vayan a tener una participación activa en el análisis de la información del modelo. Esto incluye a las columnas (en tablas de búsqueda) que el usuario utilice para filtrar los resultados de una tabla dinámica, gráfico de PowerView u objeto de otro tipo con capacidad de conectarse al modelo para presentar su información; columnas de campos clave (en tablas de datos y búsqueda) empleadas en el establecimiento de relaciones; columnas (en tablas de datos) que intervengan en fórmulas para la creación de medidas, etc.
Dicho esto, los factores más importantes que debemos tener en cuenta son la cantidad de columnas a trasladar al modelo, así como el grado de variabilidad de valores de cada columna, es decir, la cantidad de valores distintos contenidos en una columna, y el número de registros en los que está presente cada valor. Recordemos que uno de los aspectos destacados de xVelocity es su nivel de compresión, por lo que a menor frecuencia de valores en una columna, mayor ratio de compresión y optimización en la velocidad de las consultas.
Analicemos este aspecto sobre FactInternetSales. Se trata de una tabla que contiene 60398 registros, por lo que si en la fase de importación al modelo de esta tabla sólo traspasamos las columnas ProductKey y OrderDateKey, el impacto sobre el rendimiento del motor de PowerPivot será mínimo, ya que dichas columnas tienen 158 y 1124 valores distintos respectivamente en la tabla. Dicho impacto irá en aumento conforme vayamos agregando columnas con una mayor cantidad de valores diferentes, como pueda ser CustomerKey (18484 valores), y aunque en esta tabla no existe, una posible columna compuesta por la combinación de SalesOrderNumber y SalesOrderLineNumber sería la que más negativamente afectaría al rendimiento del proceso de carga de datos, ya que arrojaría una cantidad de 60398 valores distintos posibles, esto es, la misma cantidad de registros que tiene la tabla.
No obstante, en el contexto de la base de datos AdventureWorksDW, donde la tabla de mayor tamaño contiene una cantidad que ronda los 64000 registros, el hecho de cargar cualquiera de sus tablas al completo en un modelo de PowerPivot no supondría una merma apreciable en el rendimiento, ni penalización en la ejecución de las consultas. Sin embargo, como es conveniente adquirir buenos hábitos, independientemente del volumen de la fuente de datos a emplear, vamos a seguir las pautas recomendadas en este apartado, empezando por modificar el modelo, tomando exclusivamente las columnas de las tablas que van a intervenir en los cálculos de medidas y filtros.
Recomponer el proceso de importación de datos al modelo
En su estado actual, el modelo nos permite visualizar la cifra de ventas por cada año de facturación. Analizando los elementos de la base de datos que necesitamos realmente para obtener estos resultados, podemos deducir que de la tabla FactInternetSales únicamente precisamos las columnas SalesAmount y OrderDateKey, mientras que de la tabla DimTime serían las columnas TimeKey y CalendarYear, por lo que vamos a proceder a “adelgazar” nuestro modelo con unos sencillos ajustes.
No se trata de eliminar el modelo por completo y crearlo nuevamente a partir de cero, sino que nos posicionaremos en la ventana de PowerPivot, y en la pestaña correspondiente a la tabla FactInternetSales, elegiremos la opción Propiedades de Tabla del menú Diseñar. En dicha ventana de propiedades desmarcaremos todas las casillas de selección de columna excepto SalesAmount y OrderDateKey, haciendo clic en Guardar para mantener los cambios.
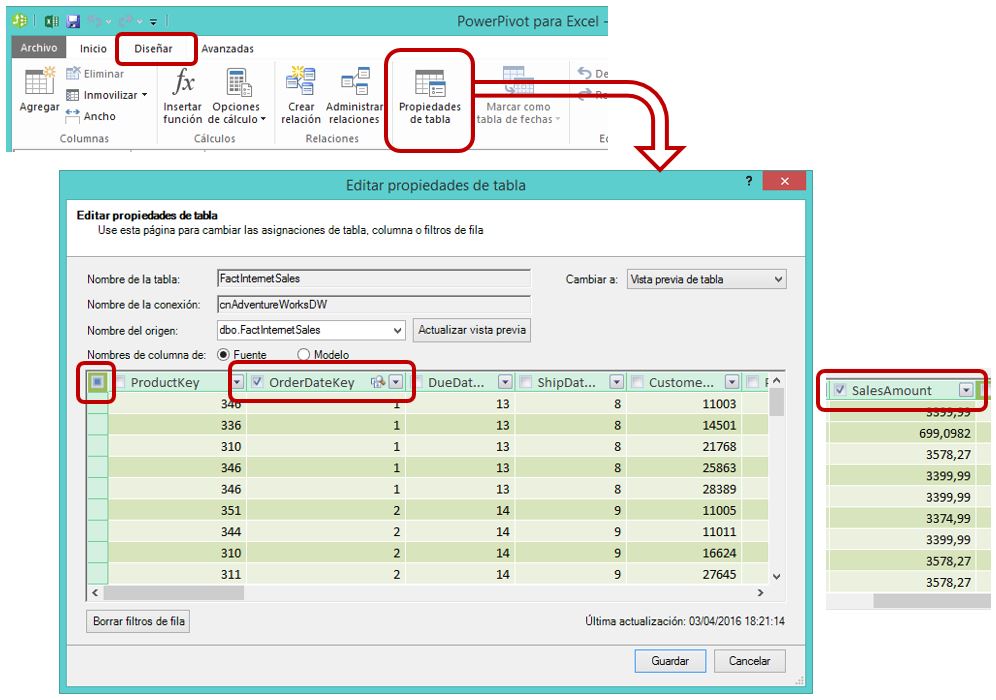
Procederemos de la misma manera con la ventana de propiedades de la tabla DimTime, desmarcando todas las columnas salvo TimeKey y CalendarYear. Al retornar a la tabla dinámica que estamos usando para analizar el modelo, comprobaremos que las columnas disponibles se han reducido en consonancia con los cambios recién aplicados.
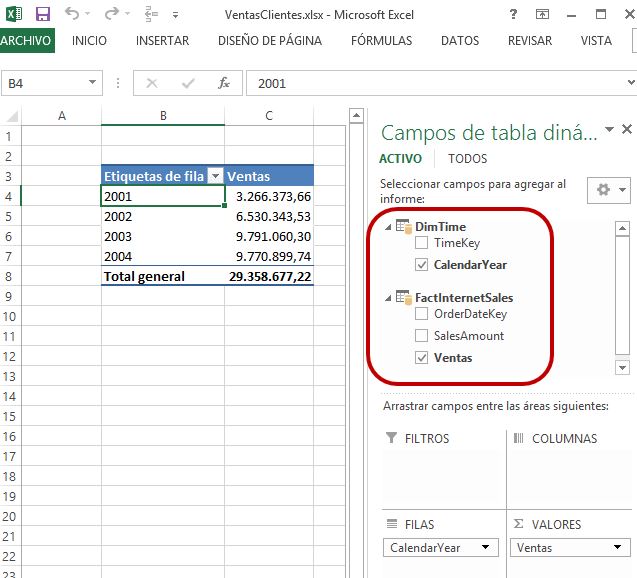
Como ya hemos explicado anteriormente, la disminución en el número de columnas también trae como beneficio una reducción en el tamaño del archivo Excel que alberga el modelo. Aunque en este ejemplo no experimentaremos una ganancia de espacio remarcable, cuando trabajemos con fuentes de datos de mayor magnitud sí que lo apreciaremos en su justa medida.
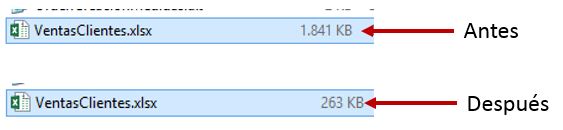
Diseño en estrella mejor que en copo de nieve
El siguiente paso que daremos en la construcción del modelo consistirá en añadir la tabla de búsqueda que nos permita analizar las ventas por la categoría de los productos vendidos.
Revisando entre las tablas de la base de datos elegiremos la columna EnglishProductCategoryName, perteneciente a la tabla DimProductCategory, que representa al literal de categoría que necesitamos. Por otro lado, la columna ProductKey de la tabla FactInternetSales contiene el código del producto vendido. Sin embargo, no existe una conexión directa entre ambas tablas, siendo necesario “recorrer” dos tablas intermedias adicionales: DimProduct y DimProductSubcategory, para poder obtener convenientemente el dato que corresponde a la categoría del producto; dicho de otro modo, no existe una única tabla de búsqueda, sino que la información se encuentra repartida entre varias.
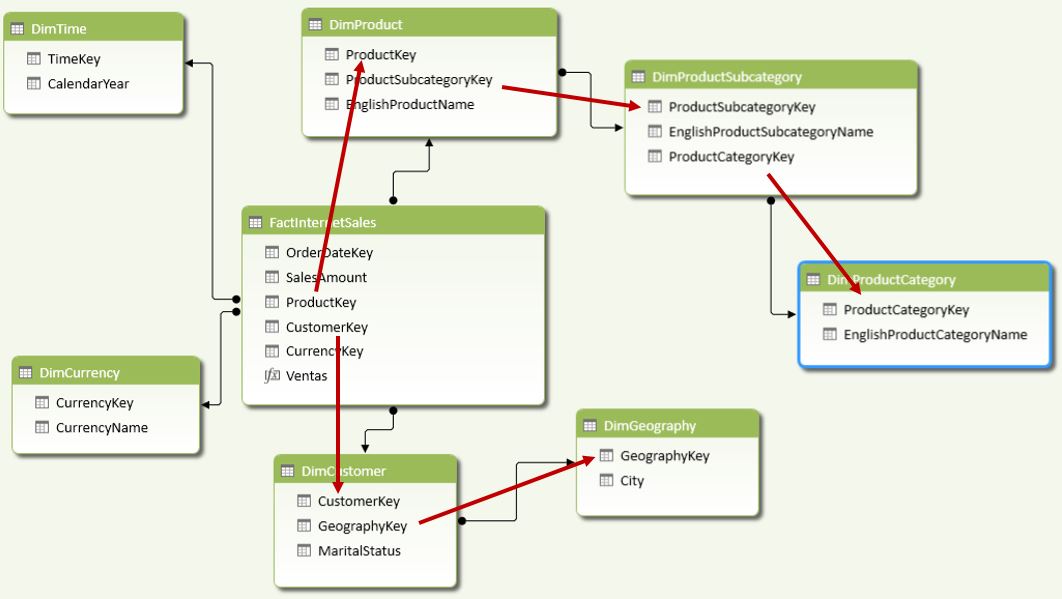
En entornos de almacenamiento de datos (Data Warehousing) e inteligencia de negocio como PowerPivot, SQL Server Analysis Services (Multidimensional o Tabular), etc., esta situación puede resolverse implementando en el diseño del modelo uno de los dos siguientes tipos de esquema: copo de nieve (snowflake schema) o estrella (star schema).
Mediante un esquema en copo de nieve se toman las tablas implicadas, y desde la tabla de datos hasta la última tabla de búsqueda se crea una cadena de relaciones entre las columnas clave. En el siguiente diagrama vemos cómo quedaría un hipotético modelo en el que, además de relaciones simples desde la tabla de datos a una de búsqueda, tenemos dos casos de relaciones con más de una tabla de búsqueda relacionada.
Por otro lado, dentro de un esquema en estrella se combinan, en una única tabla, las tablas independientes que representan una entidad informativa del modelo, la cual relacionaremos con la tabla de datos. Este será el tipo de esquema que implementaremos en nuestro ejemplo.
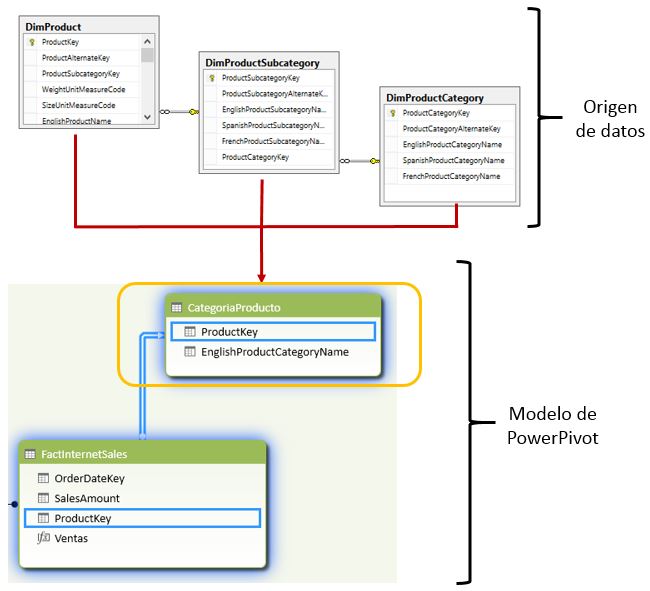
Para conseguir esto con las tablas DimProduct, DimProductSubcategory y DimProductCategory, prepararemos previamente en SQL Server la siguiente sentencia, encargada de la combinación de los datos.
SELECT p.ProductKey ,pc.EnglishProductCategoryName FROM DimProduct AS p INNER JOIN DimProductSubcategory AS ps ON p.ProductSubcategoryKey = ps. ProductSubcategoryKey INNER JOIN DimProductCategory AS pc ON ps.ProductCategoryKey = pc. ProductCategoryKey
A continuación ejecutaremos el asistente de importación de datos de PowerPivot, eligiendo el uso de una consulta en el paso Elegir cómo importar los datos. Escribiremos la anterior sentencia, y ello dará como resultado en el modelo una nueva tabla que llamaremos CategoriaProducto.
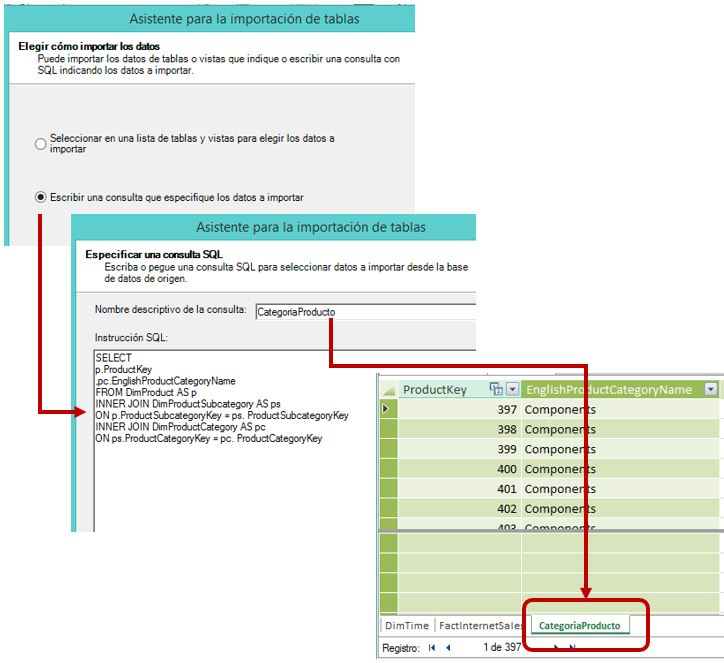
Para poder relacionar la nueva tabla CategoriaProducto con FactInternetSales, abriremos la ventana de propiedades de esta última y marcaremos la casilla de la columna ProductKey para incorporarla al conjunto de columnas de la tabla que intervienen en el modelo.
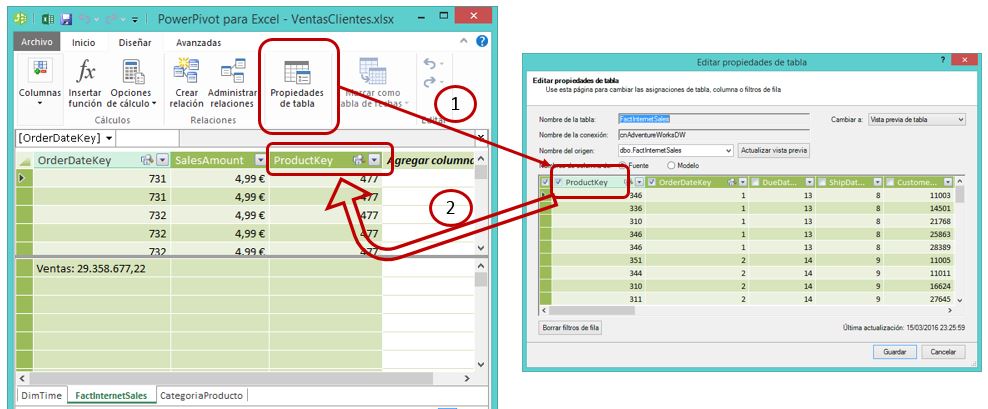
Tras esta operación relacionaremos las columnas ProductKey en ambas tablas y volveremos a la tabla dinámica, donde ya tendremos disponible el campo EnglishProductCategoryName, que situaremos en el área de columnas. En el caso de que no aparecieran los nuevos campos agregados al modelo, haremos clic en la opción TODOS, dentro del panel Campos de tabla dinámica.
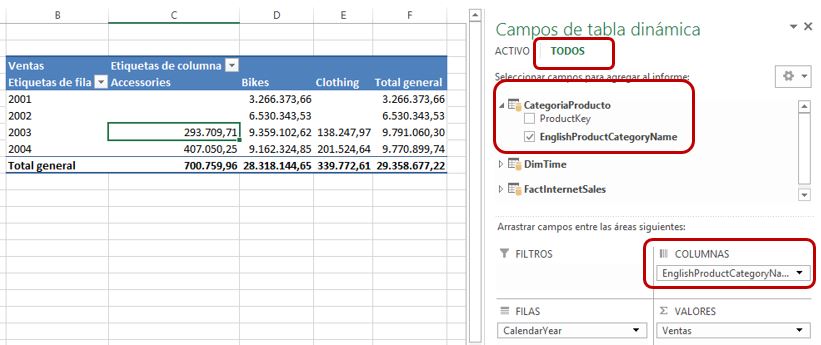
Aunque el esquema de estrella pueda producir una tabla de búsqueda más voluminosa en cuanto a cantidad de columnas, se recomienda su empleo en detrimento de copo de nieve, ya que en xVelocity proporciona un mejor rendimiento. Donde sí que debemos intentar mantener en todo lo posible un número reducido de columnas es en la tabla de datos, puesto que suele tener una elevada cantidad de filas, y este aspecto también influye en el rendimiento del motor.
Otro rasgo que igualmente puede afectar a las prestaciones del modelo, sobre todo con fuentes de datos muy grandes, reside en la cantidad de RAM y la potencia del procesador a nuestra disposición. En la medida de lo posible debemos intentar trabajar con al menos 4 GB de RAM y las versiones de 64 bits del sistema operativo y Excel, o bien SQL Server Analysis Services Tabular, en el caso de que utilicemos SQL Server para el desarrollo de los modelos.
Contando clientes
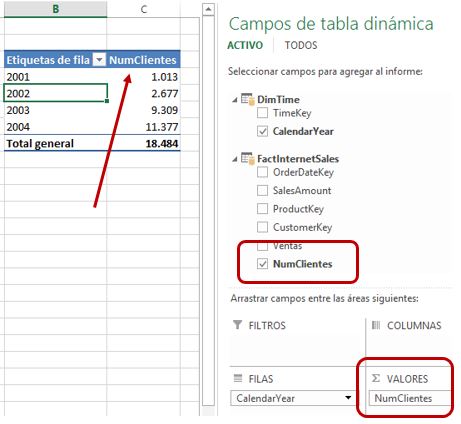
Seguidamente crearemos la medida NumClientes, también descrita en el apartado de requerimientos del modelo, y que consiste en un recuento del número de clientes distintos que han realizado compras.
Para ello traeremos a la tabla FactInternetSales del modelo la columna CustomerKey desde la tabla del mismo nombre del origen de datos (de forma idéntica a la explicada en el apartado anterior para la columna ProductKey), escribiendo a continuación la siguiente fórmula DAX, en la que utilizaremos la función DISTINCTCOUNT, que se encargará de contar los valores únicos del campo CustomerKey.
NumClientes:=DISTINCTCOUNT(FactInternetSales[CustomerKey])
Ahora volveremos de nuevo a la tabla dinámica para observar las cifras resultantes de esta nueva métrica.
Columnas calculadas. Preferiblemente en el origen de datos
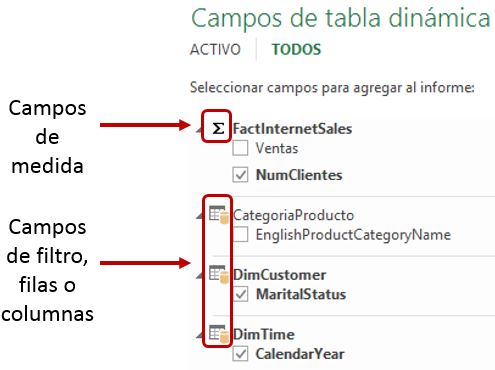
Pero recordemos que las cifras de la medida NumClientes debemos analizarlas a través del estado civil de dichos clientes. Por tal motivo necesitamos traer al modelo la tabla DimCustomer, y de dicha tabla, las columnas CustomerKey y MaritalStatus. De esta última columna, sus valores S y M corresponden a soltero (Single) y casado (Married) respectivamente. Una vez importados estos datos, relacionaremos esta tabla con FactInternetSales por la columna CustomerKey, y analizaremos la información en la tabla dinámica como muestra la siguiente figura.
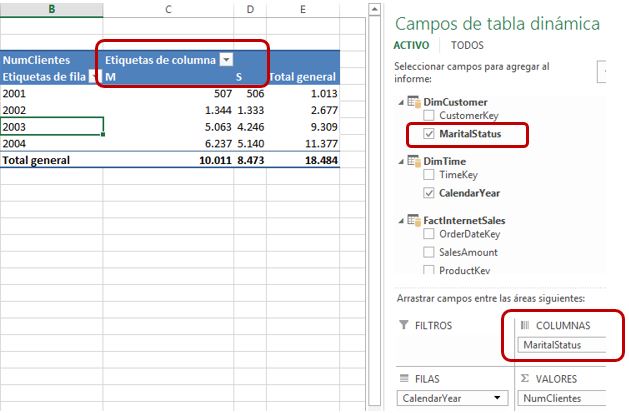
Sin embargo, creo que el lector estará de acuerdo en que los valores S y M del campo MaritalStatus no resultan muy adecuados para interpretar el estado civil de los clientes, por lo que debemos buscar un medio que nos permita visualizar un literal más apropiado.
Podemos solucionar este problema creando una columna calculada en la ventana de PowerPivot. Haciendo clic en la primera columna vacía disponible en la tabla, escribiremos la siguiente expresión DAX en el recuadro de fórmulas (el nombre de la columna será EstadoCivil).
=IF(DimCustomer[MaritalStatus]="S";"Soltero";"Casado")
Empleando la función IF comprobamos el valor de la columna MaritalStatus, generando el literal adecuado en cada caso.
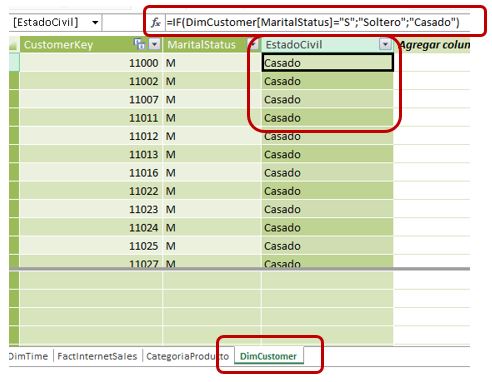
Como resultado de esta nueva columna creada dinámicamente mostraremos un literal más legible en la tabla dinámica.
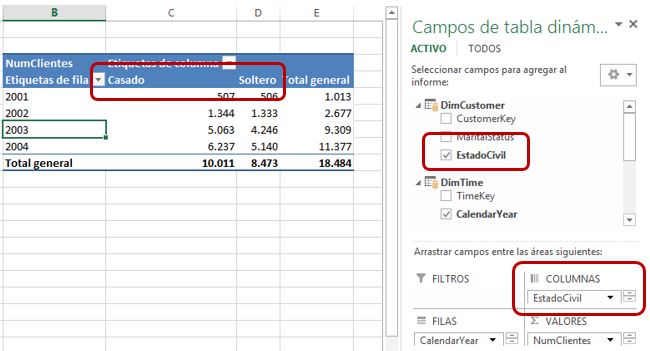
No obstante, siempre que sea posible, en lugar de crear la columna calculada en el modelo se recomienda considerar si la misma puede ser creada mediante alguna otra técnica, ya que este tipo de columnas introducen un potencial factor de penalización, puesto que necesitan almacenamiento extra.
Como demostración de lo que acabamos de exponer, eliminaremos del modelo la tabla DimCustomer y repetiremos la importación de la misma usando la siguiente consulta SQL, que contendrá una expresión para crear dinámicamente la columna MaritalStatus. Recuerde el lector que deberemos volver a relacionar esta tabla con la tabla de datos del modelo.
SELECT CustomerKey, CASE WHEN MaritalStatus = 'S' THEN 'Soltero' WHEN MaritalStatus = 'M' THEN 'Casado' END AS MaritalStatus FROM DimCustomer
La visualización de los datos en la tabla dinámica no se verá afectada salvo que el campo volverá a llamarse MaritalStatus.
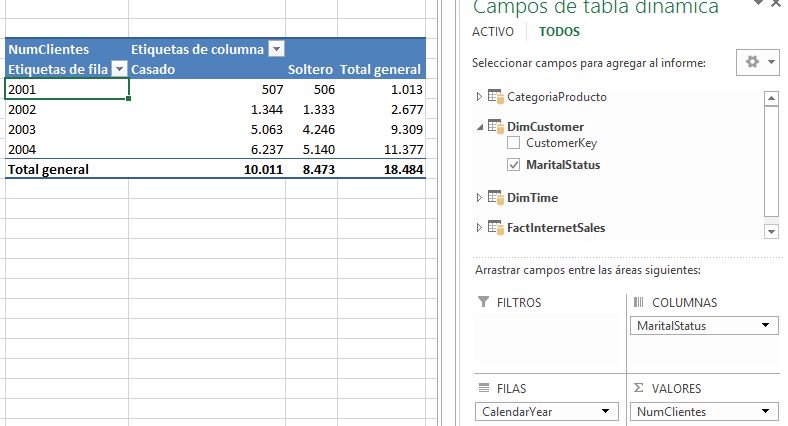
Ocultar columnas en herramientas cliente
De todas las columnas repartidas entre las tablas de un modelo de datos habrá un subconjunto que emplearemos en la tabla dinámica para analizar la información por filas, columnas o como filtro; pero también existirá otro grupo de columnas que no tendrán una participación visual, ya sea porque se utilicen como elementos de cálculo para medidas, como relaciones entre tablas, etc.
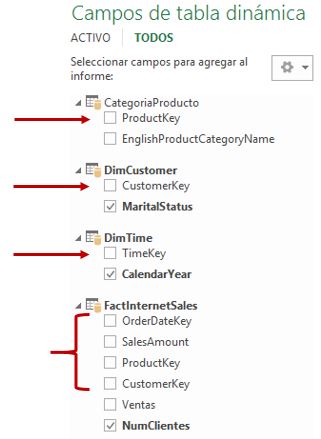
Este tipo de columna, utilizado para operaciones internas del modelo, no tiene mucho sentido que sea puesta a disposición del usuario de la tabla dinámica, ya que no aporta funcionalidad analítica. Por lo tanto resulta más oportuno ocultarlas desde la ventana de PowerPivot haciendo clic derecho en el título de la columna, y eligiendo la opción Ocultar en herramientas cliente.
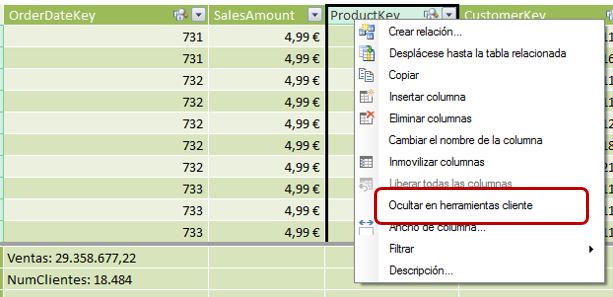
De esta forma conseguiremos en la tabla dinámica una visualización mucho más “limpia” de los campos realmente útiles a efectos de análisis.
Conclusiones
Y después de esta última mejora sobre el modelo de datos llegamos al final del artículo, en el que además de realizar una introducción a la creación de modelos de datos en PowerPivot, hemos descrito algunas técnicas de optimización que pueden ayudarnos a mejorar el rendimiento de nuestros modelos. Espero que os resulte de utilidad.


kiquenet
Tremendo!! Muy bueno !!
Eliminar claves FK por comodidad para crear relaciones en el modelo de PowerPivot?
Saludos.
lmblanco
Hola Enrique
Respecto a esta duda que indicas, la eliminación de las FK se hace simplemente por motivos ilustrativos, para demostrar posteriormente cómo crear las relaciones entre las tablas del modelo en PowerPivot. Por supuesto que si en la bbdd relacional tenemos establecidas FK, deben de mantenerse porque al importar los datos desde PowerPivot se crean automáticamente las relaciones entre las tablas del modelo. 🙂
Un saludo,
Luismi