
After the generation of data in Excel explained in the first part of the article, in this second installment we’ll show how to insert that information into a SQL Server database.
Database creation
After spreadsheet creation, we’ll transfer its contents into a SQL Server database running the following script from SQL Server Management Studio.
USE master GO CREATE DATABASE Poblacion GO USE Poblacion GO CREATE TABLE DatosPoblacion ( Fila_ID int NOT NULL, Edad_ID int NULL, Sexo_ID char(1) NULL, CCAA_ID int NULL, Pais_ID int NULL, Fecha_Alta datetime NULL, CONSTRAINT PK_DatosPoblacion PRIMARY KEY CLUSTERED (Fila_ID ASC)) GO CREATE TABLE Sexo ( Sexo_ID char(1) NOT NULL, Sexo_DS varchar(10) NULL, CONSTRAINT PK_Sexo PRIMARY KEY CLUSTERED (Sexo_ID ASC)) GO CREATE TABLE CCAA ( CCAA_ID int NOT NULL, CCAA_DS varchar(50) NULL, CONSTRAINT PK_CCAA PRIMARY KEY CLUSTERED (CCAA_ID ASC)) GO CREATE TABLE Pais ( Pais_ID int NOT NULL, Pais_DS varchar(50) NULL, CONSTRAINT PK_Paises PRIMARY KEY CLUSTERED (Pais_ID ASC)) GO
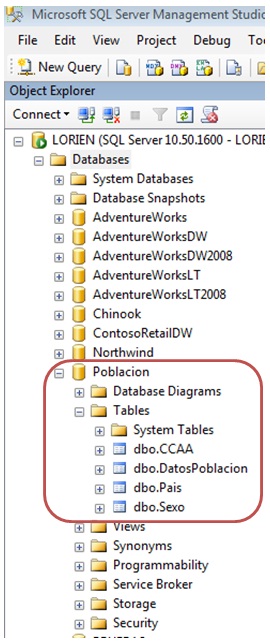
As we have seen, in addition to the table that will house the data generated from Excel, we will also create the catalog tables, which contain descriptions of some fields of code existing in DatosPoblacion table with which establish the necessary relationships.
Import Excel data from SQL Server
To insert data into DatosPoblacion table, we’ll use Transact-SQL’s OPENROWSET function as follows.
INSERT INTO DatosPoblacion SELECT Fila_ID,Edad_ID,Sexo_ID,CCAA_ID,Pais_ID,Fecha_Alta FROM OPENROWSET('Microsoft.ACE.OLEDB.12.0', 'Excel 8.0;Database=C:\DatosOrigen\GenerarDatosPoblacion.xlsx', 'SELECT * FROM [Hoja1$]')
However, it’s possible we get an error when trying to execute this insert sentence, which informs us that SQL Server is not configured to query in this way, called ‘Ad Hoc Distributed Queries’.
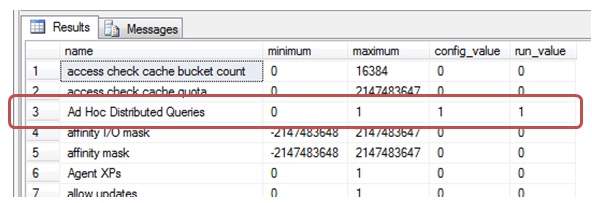
If we want to check the SQL Server settings, we must run the system stored procedure sp_configure. However, it is likely that among the options listed, we do not see the distributed queries configuration. If we are in this case, we must enable the advanced options display using the following sentences.
EXECUTE sp_configure 'show advanced options',1 GO RECONFIGURE GO
Now we see the value of ‘Ad Hoc Distributed Queries’ option by executing sp_configure.To enable it execute the following.
EXECUTE sp_configure 'Ad Hoc Distributed Queries',1 GO RECONFIGURE GO
When we run sp_configure back, we will already see activated the ability to run distributed queries.
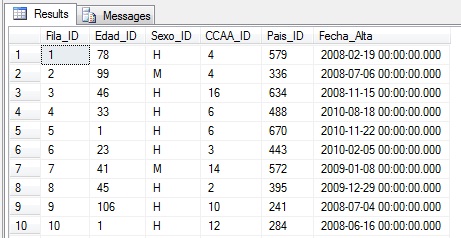
Thus, the previous sentence with OPENROWSET will work properly, filling the DatosPoblacion table with the content of the GenerarDatosPoblacion.xlsx file.
Optimizing data import from Excel
However, at the current point we may face a performance problem, because if we followed the above steps for creating the Excel file, we have a spreadsheet with one million rows, which can take about fifteen minutes to load into SQL Server table. For the sample developed in this article, we have used a virtual machine with Windows 7 operating system and 1.5 GB RAM, so that the above times may vary depending on the configuration used for these tests.
If we want to reduce these load times we may opt an alternative technique for transferring data which explain below.
In first place we will open back the file GenerarDatosPoblacion.xlsx, saving it as «CSV (Comma delimited)» type.
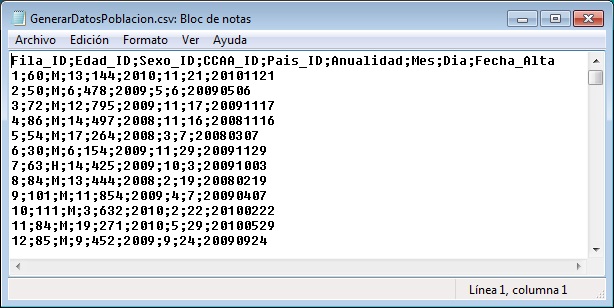
In this way we’ll get a text file with fields delimited by the semicolon character. We can see its contents by opening it with Notepad.
Then we will create a new table in the database with the following structure.
CREATE TABLE DatosPoblacionExcel ( Fila_ID varchar(20) NULL, Edad_ID varchar(20) NULL, Sexo_ID varchar(20) NULL, CCAA_ID varchar(20) NULL, Pais_ID varchar(20) NULL, Anualidad varchar(20) NULL, Mes varchar(20) NULL, Dia varchar(20) NULL, Fecha_Alta varchar(20) NULL)
Into this new table we will import the contents of GenerarDatosPoblacion.csv, using the Transact-SQL statement BULK INSERT. Through the FIELDTERMINATOR option, we’ll specify the character used as field separator, while the option FIRSTROW indicate that the reading of data starts in the second row of the file, because the first contains the column names.
BULK INSERT DatosPoblacionExcel FROM 'C:\DatosOrigen\GenerarDatosPoblacion.csv' WITH (FIELDTERMINATOR =';', FIRSTROW=2)
The time consumed by the bulk insert operation in the table DatosPoblacionExcel be about thirty seconds.
To finish this process, we will insert in the table DatosPoblacion the records from DatosPoblacionExcel table, excluding the unnecessary fields, as shown in the following statement, whose execution will take approximately 15 seconds.
INSERT INTO DatosPoblacion SELECT Fila_ID,Edad_ID,Sexo_ID,CCAA_ID,Pais_ID,Fecha_Alta FROM DatosPoblacionExcel
As we have seen, this inserting data technique, but requires us to perform an additional step, is a significant gain in time, employing less than a minute in the transfer of data to the table DatosPoblacion, compared to the fifteen minutes used by the OPENROWSET function.
Importing the other catalog tables
For tables CCAA and Pais, we will use two Excel files containing, respectively, the official classification of regions and countries .These files are available in compressed format on the website of the Institute of Statistics of the Community of Madrid . Once downloaded and unzipped we’ll run the following SQL statements for import into our database.
INSERT INTO CCAA SELECT DISTINCT ccaa, liteccaa FROM OPENROWSET('Microsoft.Jet.OLEDB.4.0', 'Excel 8.0;Database=C:\DatosOrigen\ccaaprov.xls', 'SELECT * FROM [ccaaprov$]') INSERT INTO Pais SELECT DISTINCT isopais,lpaisc FROM OPENROWSET('Microsoft.Jet.OLEDB.4.0', 'Excel 8.0;Database=C:\DatosOrigen\cozonu.xls', 'SELECT * FROM [cozonu$]')
Note that depending on the version of Excel file to import, in OPENROWSET function we’ll use a different provider to get the data.If the file is for Excel 2007-2010 will use ‘Microsoft.ACE.OLEDB.12.0 ‘, while for earlier versions will be «Microsoft.Jet.OLEDB.4.0 ‘.
Setting the country code in the table DatosPoblacion
A closer look at the records of the Pais table will unveil that Pais_ID field values are uncorrelated, being also the lowest value 4 and the highest 894.
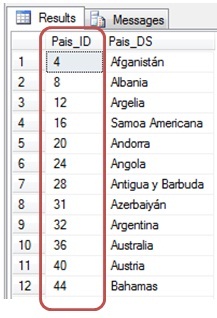
This contrasts with existing data in the field of the same name for the table DatosPoblacion because, although the maximum and minimum value of this field is also between 4 and 894, we find a lot of records where the field Pais_ID not correspond to any value in the Pais table.
To solve this problem we resort to a couple of techniques, of which the first will be taken from DatosPoblacion table, each Pais_ID field values that do not exist in the Pais table, adding one until we reach a value which does exist in the countries catalog table mentioned. We will implement this process in the SQL Server function below.
CREATE FUNCTION dbo.ObtenerPais(@nPais_ID int) RETURNS int AS BEGIN WHILE (SELECT COUNT(*) FROM Pais WHERE Pais_ID = @nPais_ID) = 0 BEGIN SET @nPais_ID = @nPais_ID + 1 END RETURN @nPais_ID END GO
The update of field Pais_ID in table DatosPoblacion the take out with the next statement.
UPDATE DatosPoblacion SET Pais_ID = dbo.ObtenerPais(Pais_ID) WHERE Pais_ID NOT IN (SELECT Pais_ID FROM Pais)
The second technique is more direct, as it avoids the use of the search function of the field Pais_ID in the countries table.What we do here is an update of the field Pais_ID for the entire table DatosPoblacion, looking in the Pais table, the value of Pais_ID closest to that exists in the same field in the table DatosPoblacion.
UPDATE DatosPoblacion SET Pais_ID = (SELECT TOP 1 Pais.Pais_ID FROM Pais WHERE Pais.Pais_ID >= DatosPoblacion.Pais_ID ORDER BY Pais.Pais_ID)
In both cases, we get that all the records in the DatosPoblacion table join correctly with the Pais table through Pais_ID field.
Manual data entry
After the above operations, the only remaining empty table is Sexo, so we’ll run the following statements, which will create the necessary records.
INSERT INTO Sexo VALUES ('H','Hombre') INSERT INTO Sexo VALUES ('M','Mujer')
Establishing relationships between tables
To finish the database creation, we will establish the appropriate relationships between fields in the table DatosPoblacion and other catalog tables using the following sentences.
ALTER TABLE DatosPoblacion WITH CHECK ADD CONSTRAINT FK_DatosPoblacion_Sexo FOREIGN KEY(Sexo_ID) REFERENCES Sexo (Sexo_ID), CONSTRAINT FK_DatosPoblacion_CCAA FOREIGN KEY(CCAA_ID) REFERENCES CCAA (CCAA_ID), CONSTRAINT FK_DatosPoblacion_Pais FOREIGN KEY(Pais_ID) REFERENCES Pais (Pais_ID)
After this operation we finish this article, which explained the different parts of a process for generating, from Excel, a considerable amount of test data that can be used later from SQL Server. We hope you find useful.
Regards,


anonymous
This article addresses the challenge of develop a process to create a database with demographic information