
PowerPivot is a technology for information analysis whose peculiarity lies in the ability of working with massive amounts of data using Excel as user interface, so it becomes an attractive offer, given the popularity of this tool belonging to the Office suite. This article introduce the reader to PowerPivot as well as DAX (Data Analysis eXpressions), the analytical expression language that accompanies it, reeling off the most important features of this technology, which coupled with traditional Analysis Services and MDX (MultiDimensional eXpressions) language, make SQL Server 2012 one of the most robust and powerful solutions in the Business Intelligence arena.
With increasing frequency, organizations must perform diverse analysis about their status in the most varied perspectives (business, financial, HR, etc.) and on an increasingly vast amount of data, for which require suitable tools to enable them to obtain a reliable and valid information of such state.
As explained in this blog’s article, OLAP data cubes are one of the key elements in this data analysis ecosystem called Business Intelligence (BI).
However, a BI system, as occurs in other areas such as Web applications, desktop, etc., requires a development team and time to its creation, this latter factor sometimes extends for longer than initially estimated.
Given the problems posed above, we can propose as a solution to improve development tools of the information system, which accelerate its creation time, and allow handling a greater data volume, given the widespread increase of this aspect in all corporate areas.
It would also be necessary to promote the development team, incorporating new players into the system development cycle, which so far have played a role of mere validators, but they can bring great value to it, given his extensive knowledge about the structure of the various data sources available within the organization.
PowerPivot comes with the aim of providing solutions to the challenges posed above, covering a number of specific areas in the development of an information system based on BI.
Self-service BI
When we talk about self-service, usually framed this concept within the product sales activity, where a person, the client, moves to a place, the supermarket, where products are exposed, and once there the client picks up the products, all generally without requiring the intervention of any intermediary.
Within the BI context we can make an analogy with the self-service model, using a concept called self-service BI, which advocates that end users (advanced or other profile) of an information system can elaborate their own analysis and reports on the system contents, to meet the specific needs emerging in several company departments, without having on these situations to rely from the enterprise BI development team.
As requirements are the access need by these users to those data sources that require analysis and it is also crucial that self-service BI oriented applications have a learning curve as small as possible, so users can start being productive with them almost immediately.
PowerPivot meet these requirements, since being a technology built into Excel has a wide user base already working with both, the functionality of the spreadsheet and access to external data sources, thus reducing or eliminating training in the use of user interface, and focuses on learning specific features about additional support for data analysis.
Incorporating new user profiles to the development cycle
In addition to release development teams a significant workload, providing self-service BI tools to end users; we get as a bonus the possibility that advanced users from various departments of the organization, through the use of such tools, to assist in the development cycle of the information system, providing ideas and suggestions.
VertiPaq. High performance data processing engine
PowerPivot introduces a new data processing engine: VertiPaq, which through a column-based storage, implements a series of algorithms for data compression, by which is capable of loading millions of records in memory.
However, due to the execution in memory nature of VertiPaq is recommended, whenever possible, work on a 64-bit environment, with adequate software version to this architecture: operating system, SQL Server, Office 2010, PowerPivot, etc., since it does not suffer the memory address limitations found in the 32-bit systems.
Architectural elements
PowerPivot, as seen in next image, consists of an assembly that is loaded into Excel process; VertiPaq engine, which handles data loading, query management and DAX expressions execution against the data warehouse, as well as PowerPivot’s pivot tables and charts, and finally, the OLAP provider, the Analysis Management Objects (AMO) objects and ADOMD.NET provider, allowing communication with analysis services, for gathering information from data cubes if applicable.

Collaboration environment. PowerPivot for SharePoint
Using PowerPivot is expected that the number of analysis models created by users grows noticeably, and it is therefore very important to have a management mechanism, with respect to the publishing and access security within the organization.
This is the purpose of PowerPivot for SharePoint, a plug-in extending Excel Services for SharePoint, in the above paragraphs about management and collaboration.
Additionally, PowerPivot for SharePoint allows users to view PowerPivot models published in the organization simply using a web browser, so you only need to install Excel and PowerPivot for Excel on the machines of users who will develop analytical models using this tool.
PowerPivot. BISM cornerstone
(Note: for a more accurate description of BISM than below, we recommend read in first place the SSAS Tabular Models article which includes updated information about this technology).
SQL Server 2012 ships with a new BI model called Business Intelligence Semantic Model (BISM). This model doesn’t replace or displace Unified Dimensional Model (UDM), the existing BI model from SQL Server 2005 but coexist with it, complementing and enriching the SQL Server offer in BI area, allowing us to have both models to work with the one that best suits our needs.
SQL Server has been traditionally blamed, referring to UDM, that its implementation in BI area has a difficult learning curve with complex concepts: cubes, dimensions, measures, etc., and that the time needed to develop a solution extends too much when it comes to creating a simple analysis system.
From our point of view, this learning curve isn’t much more complicated than we find in other aspects of software development, although we admit that from the perspective of developers used to working with a relational data model, getting familiar with the UDM-OLAP multidimensional model to build a business analytics solution may involve some initial complexity until the developer master the concepts and features of the technology.
BISM comes to solve this problem, providing a simpler way of work, distinguished by its relational philosophy supported by PowerPivot and VertiPaq. While BISM is primarily oriented to the development of self-service analytical solutions or for small teams, UDM is focused in the development of corporate BI solutions, which require more planning.
BISM is a model with a distributed architecture in three layers: data access, business logic and data model.
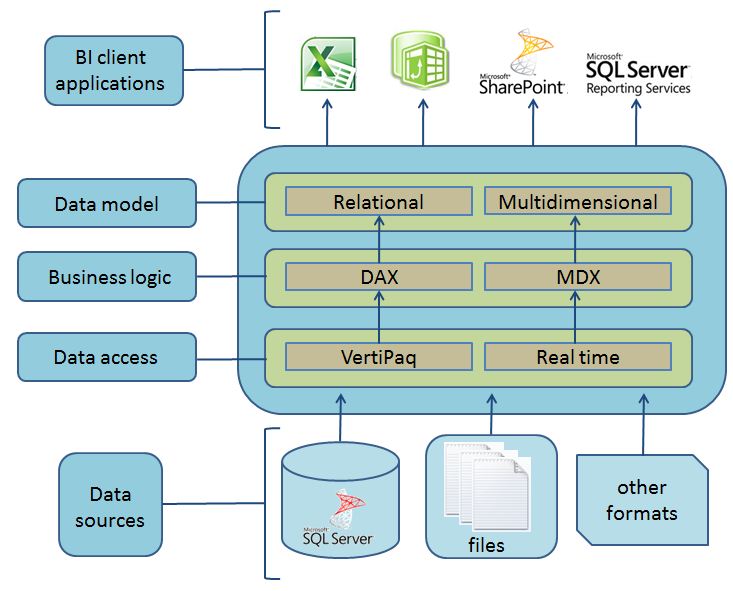
The data access layer is responsible for connecting to data sources to load the data they contain, existing two ways to operate with them: cached or real time. In the case of cached mode, data is loaded using VertiPaq, whereas if we use the real-time mode, this task is left to the original data source from which data are extracted.
The business logic layer will implement the managing and processing of data that allow us to make them relevant information. We will use for this any expression languages at our disposal: DAX or MDX.
DAX is the expression language for data analysis built-in PowerPivot. We’ll use it to build queries against the data store located in VertiPaq, while MDX is the language usually employed in UDM to query OLAP cubes.
DAX is not as powerful as MDX, but it is much easier to use, and aims to query data located in a self-service BI model, which theoretically should not require the use of complex queries, reserved to be made against the corporate BI system, which under normal conditions will have been developed by UDM.
Finally, the data model layer will be used by client applications (Excel, SharePoint, Reporting Services, etc.) gathering information from the proper model: relational or multidimensional. Among the reporting tools that use this model is Power View, a project whose objective is to provide a better user experience for data visualization and reporting against BISM based models.
Some prominent voices in the BI-related technical community have expressed concern about the UDM-OLAP position with the BISM arrival in SQL Server 2012, although from Analysis Services development team wanted to send a reassuring message, insisting that BISM is not a replacement for UDM but a complementary technology.
PowerPivot in practice
After architectural features review made in previous paragraphs, it’s time to get down to working to develop a PowerPivot model, which help us to get our first impressions about the scope of this technology.
First of all we need to have Office 2010 installed, and download and install PowerPivot for Excel plug-in. In the event that our system is 32 bit, we’ll download the file PowerPivot_for_Excel_x86.msi, but if we work on a 64 bit we must download the file PowerPivot_for_Excel_amd64.msi. For the sake of testing, in this article we use a Windows 7 operating system virtual machine with 1.5 GB of RAM and Intel Core 2 Duo processor.
Although the name of the download page referred to SQL Server 2008 R2, it is not necessary to have it installed if we are going to work with other data formats such as Access, text files, etc. However, in our case, we will use SQL Server as data engine and the database ContosoRetailDW. Through the latter link we’ll download the ContosoBIdemoBAK.exe file containing the database in format backup.
The reason why we use this database is that it has some tables with millions of records, allowing us to test one of the salient features of PowerPivot: the ability to handle large volumes of data.
Creating a model
After restoring the database we’ll open Excel, then clicking on the ribbon tab PowerPivot. Among the options on this tab we will click PowerPivot window, belonging to Launch group, which as its name suggests, will open the PowerPivot working window.
The first task in creating the model will be to connect to a data source to import its content, so that from the Home tab of the PowerPivot window, in the Get External Data group, we’ll click From database option, selecting From SQL Server among the available items.
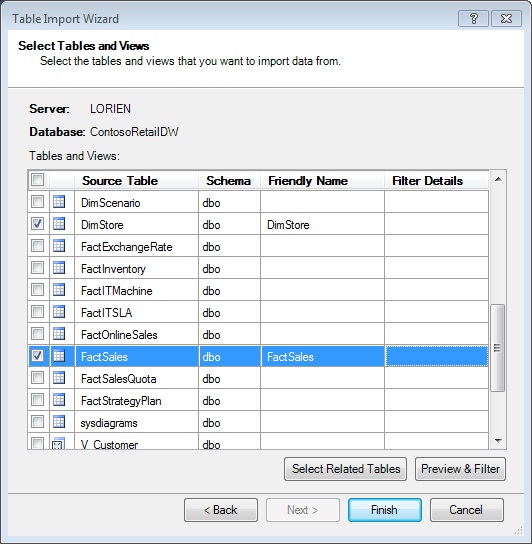
As a result will open the Table Import Wizard, where we’ll include information to connect to the database ContosoRetailDW. In the Select Tables and Views step we will check FactSales, DimDate, DimStore and DimProduct.
After this step will begin the import process, once completed will show each of the imported tables in different tabs in PowerPivot window.

Querying the model
The set of tables we have just import will conduct an analysis of company sales, according to data related to the sales table: dates, products, stores, etc.
To do this we will click on PivotTable option in Reports group reports, creating a PowerPivot’s PivotTable with which to perform our analysis operations. This action will move the focus to Excel window, where a dialog box will ask you the coordinates to place the PivotTable in the spreadsheet. Accepting the default values the new PivotTable will be created.

On the pivot table’s right side we find the PowerPivot Field List panel where we select the fields to use for our analysis, either as axis labels of rows and columns, numeric values, filters, and slicers.
Those readers with expertise in creating OLAP cubes will verify that querying a PowerPivot model is very similar to the query against a data cube, but without the existence of a real cube, as in the field list panel, the items in block Values represent the cube measures or metrics, while the rest of the block fields, represent the dimension attributes, displayed either in rows, columns or filter the PivotTable.
We will begin creating our query by checking the field SalesAmount, from FactSales table. Due this is a numeric field, it will automatically be placed as a measure in the Values block. PowerPivot will apply then an addition operation on all records in the table to which it belongs.
The current state of the PivotTable does not offer, however, great analytical possibilities, since we only have total by SalesAmount field. We need to add additional elements to the query relating to the table FactSales such as DimProduct table. This table contains each product’s name and additional information as manufacturer, type, color, size, etc.
Suppose we want to find out the number of sales by product, but instead of using his name, we need to analyze by manufacturer. What we do in this case is check the field Manufacturer, belonging to the field list of DimProduct table. This action will place the field in the Row Labels block and their values in the PivotTable row axis. In this way we will know how sales have meant by each of the manufacturers.
Since the SalesAmount field values are not shown formatted, as additional work we right-click any cell in this field, choosing Number Format… option. In the format dialog box select type Currency with two decimal places and euro symbol, being applied to all cells in this field in the pivot table.

Writing DAX expressions
As noted earlier, DAX is the expression language through which we’ll build the business logic in PowerPivot, both as PivotTable and data model.
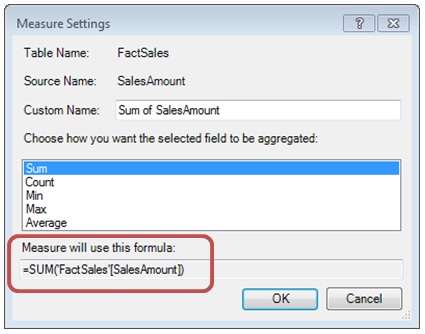
Before starting to write our first sentences in this language, we must know that without us aware of this, we have already written a DAX expression! If we right-click Sum of SalesAmount in Values block and select Edit Measure…, a dialog box will open with the expression automatically created by PowerPivot.
=SUM ( 'FactSales'[SalesAmount] )
The creation of a DAX expression is very similar to writing a formula in Excel, since then the equal sign, write one or more functions with their corresponding parameters, forming the whole expression. In the expression currently under review, the SUM function will make a sum of SalesAmount field for all records in the table FactSales. If the table name has spaces or other special characters we enclose it in quotes, in other cases not necessary. With respect to the field name should always be enclosed in brackets.
Now let’s approach to writing our own expressions, through two major elements PowerPivot: computed columns and measures.
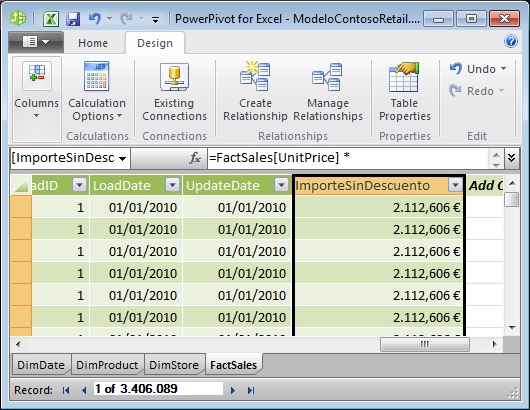
First we will create a computed column in the table FactSales, to obtain the sales amount without discounting. To this end, in PowerPivot window we should be on the last available empty column, writing in the formula bar as follows:
=FactSales[UnitPrice] * FactSales[SalesQuantity]
To assist in the writing of expressions, the AutoComplete feature will suggest at all times a list of functions, tables and fields, depending on what we go on writing.
After writing the expression, the new column will be filled with the resulting values. Double-clicking the column header we’ll assign the name ImporteSinDescuento, ending the creation of computed column.
Another way to create a computed column is to click on Add option from Columns group, belonging to Design tab.
Because the fields used in the formula belong to the same table on which we are creating the calculated column, in the expression syntax we can circumvent the name of the table, being as follows:
=[UnitPrice] * [SalesQuantity]
To use the new column in the pivot table we’ll back to the Excel window, finding a warning in PowerPivot Field List which informs us that data was modified. Clicking the Refresh button of the warning the field list will update, adding the new field ImporteSinDescuento, which we’ll check to include in the PivotTable.
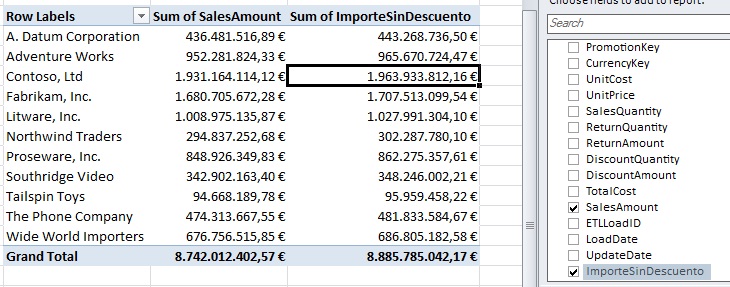
Our next step is creating a measure to calculate, for each manufacturer, the percentage of his sales with respect to total sales of the company.
In PowerPivot tab, within Measures group, we click the New Measure option, opening the Measure Settings window, where we’ll type PorcentajeVentas as measure’s name and the following expression in formula field:
=SUM ( FactSales[SalesAmount] )
/ CALCULATE ( SUM ( FactSales[SalesAmount] ), ALL ( FactSales ) )
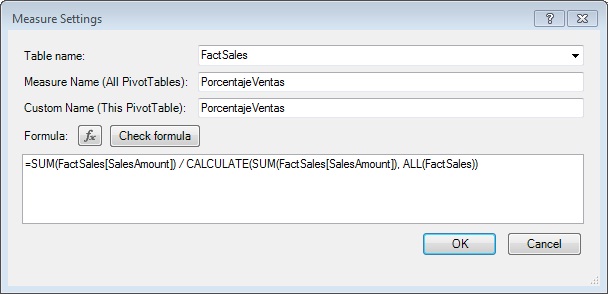
The first part of this expression, as we have seen, is responsible for adding the field SalesAmount. This sum will be made for each manufacturer, because this field is used in PivotTable labels row.
The second part of the expression returns, for all rows, the total sum of SalesAmount field, which we accomplish combining the functions CALCULATE, SUM and ALL. CALCULATE function evaluates the expression passed as the first parameter, which is a sum of SalesAmount field, and requires that the sum is over all FactSales table records by using the ALL function, regardless of the filters that are applied in the PivotTable.
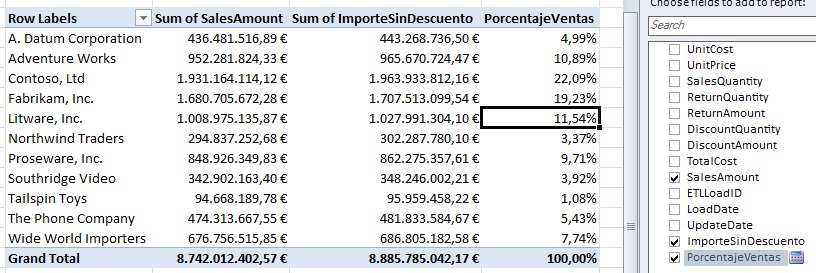
Finally, add the new measure to the pivot table by applying the percentage format.
Filters and slicers
Our PivotTable now shows arranged by product manufacturers, a series of measures obtained from fields and calculations of FactSales table belonging to PowerPivot data model.
The results of these measurements are made from all records of that table, but at some point we may also be interested to have the ability to apply filters on the model’s information, in order to obtain different perspectives of analysis.
PowerPivot pivot tables provide the user with filters and slicers as data filtering tools. Next, we’ll explain to the reader to use them as a means to narrow the results of the report.
Let’s suppose we want to filter information in the pivot table depending on the type of store where are the products. We get this data from field StoreType in DimStore table.
To create a filter of this type, in the field list pane we’ll open out the field list of table DimStore and drag the StoreType field to the Report Filter block. As a result this filter is inserted in the top of the pivot table.
By clicking on the filter selecting values button, we’ll select «Almacén». This action will activate the filter, causing all numeric cells in the pivot table refreshing sales information depending on the filter set.
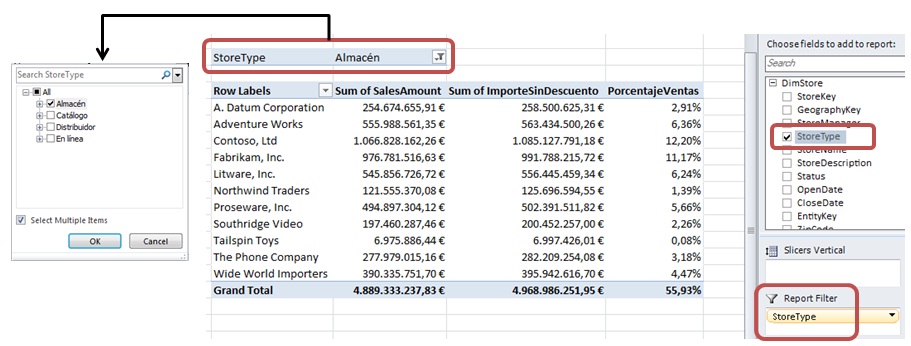
Slicers, moreover, they behave as filters, although its handling by the user is slightly different.
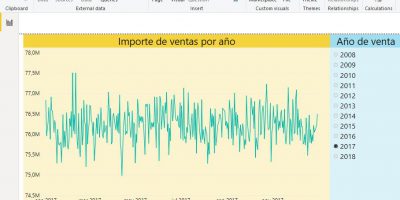
Let’s create a slicer that allows us to filter the results by sales year, for which we will drag the CalendarYear field from DimDate table and drop in Slicers Horizontal block. This action will create the slicer with all filter values placed above the pivot table.
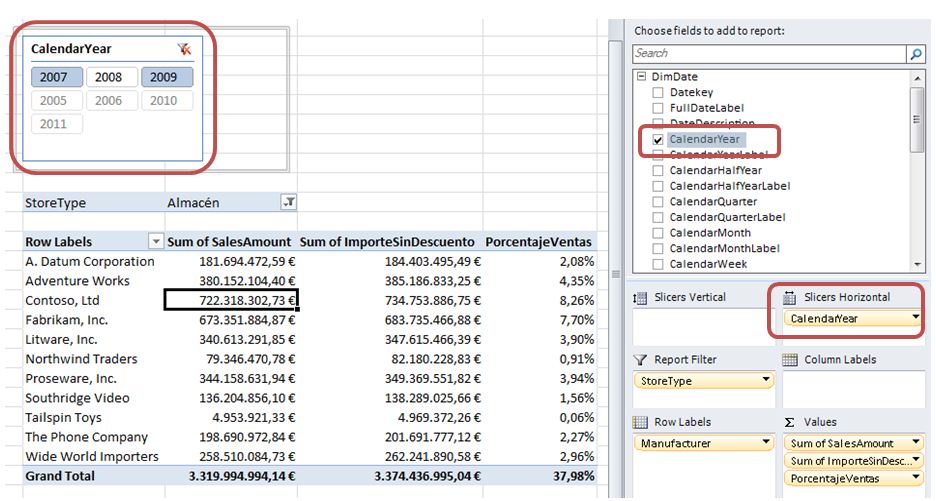
Slicer values that appear in a darker color tone are those with which we can make effective filters, while the use of those with a lighter shade will not produce results as there are no sales in those years.
If we want to use more than one value in the slicer, we must keep down the CTRL key while clicking on the different values. The result of the filter is not effective until we release the CTRL key. To remove all filters from the segmentation will click the funnel-shaped icon situated at the top right.
Creating a PivotChart
In certain circumstances, the numerical data provided by a PivotTable it may not be sufficient to analyze the content of a PowerPivot model, so we also have pivot charts at our disposal, as an alternative in the information display.
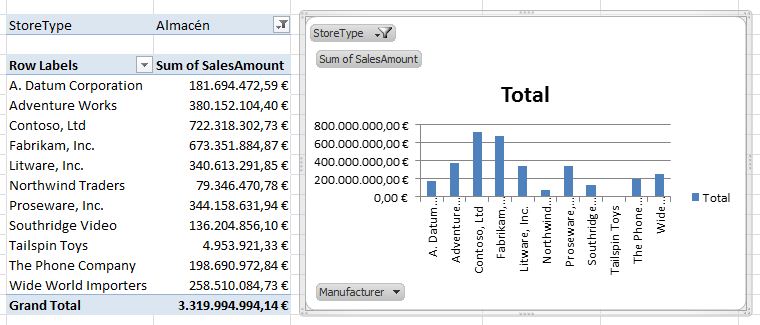
We can create a pivot chart from scratch or use an existing pivot table as chart’s foundation. In this case we’ll choose the latter method, for which, once positioned in the pivot table, we’ll click on Options tab belonging to PivotTable Tools category, and then select PivotChart option, located in the group Tools. This opens the Insert Chart dialog box, offering us a wide range of chart types to insert into the worksheet. Having made our choice, we will accept this dialog inserting the chart next to the PivotTable.
From this point, both the table and chart will be synchronized, so that the modifications of filters, measures axes labels, etc. performed in one will be reflected immediately in the other. Next image shows the appearance of our report including pivot table and pivot chart.
Conclusions
PowerPivot represents a technology with great potential to become an important part of the toolkit available for BI development with SQL Server. If we add capacity in handling large volumes of data, the power of its query expressions language, and the fact of using Excel as user interface, we obtain a product that allows users to create their own analysis models to address specific information needs. At the same time, these models can be of assistance to BI development teams in building corporate information systems.


Deja un comentario