
Una de las operaciones a las que con mayor frecuencia se enfrenta cualquier desarrollador de bases de datos es la detección y tratamiento de datos duplicados, ya sea para encontrar varios registros exactamente iguales en una tabla, debido a problemas en el diseño y consistencia de la propia base de datos, o bien para localizar determinados subconjuntos de datos con condiciones que se repitan dentro de una misma tabla.
En el presente artículo vamos a explorar diversas técnicas para enfrentarnos a este tipo de escenario, que nos permitan localizar casos de información duplicada en tablas, para proceder a su análisis, o bien para poder eliminar los datos sobrantes en el caso de repeticiones innecesarias.
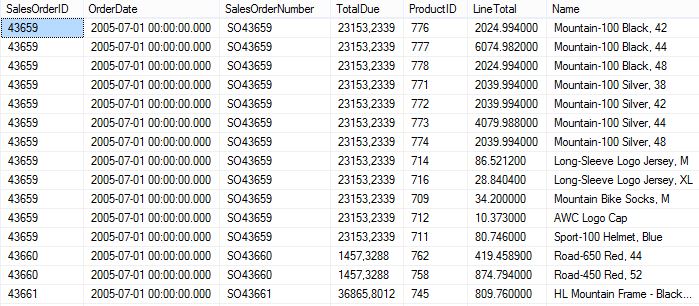
En primer lugar crearemos una nueva base de datos con el nombre PruebasDuplicados, y dentro de esta, una tabla que llamaremos Ventas, cuyas filas procederán de la siguiente sentencia sobre la base de datos AdventureWorks, que devuelve datos duplicados con los que podremos realizar nuestras pruebas.
IF (OBJECT_ID('Ventas','U') IS NOT NULL) BEGIN DROP TABLE Ventas END SELECT h.SalesOrderID, h.OrderDate, h.SalesOrderNumber, h.TotalDue, d.ProductID, d.LineTotal, p.Name INTO Ventas FROM AdventureWorks.Sales.SalesOrderHeader AS h INNER JOIN AdventureWorks.Sales.SalesOrderDetail AS d ON h.SalesOrderID = d.SalesOrderID INNER JOIN AdventureWorks.Production.Product AS p ON d.ProductID = p.ProductID
GROUP BY…HAVING…COUNT
La combinación de las cláusulas GROUP BY y HAVING de la sentencia SELECT, junto con la función COUNT representa la forma más sencilla de detectar si en una tabla existen valores duplicados para una columna o combinación de columnas, como podemos apreciar en la siguiente consulta sobre nuestra tabla de ejemplo Ventas, donde obtendremos aquellos valores de la columna SalesOrderNumber en los que se está produciendo una duplicidad, y la cantidad de filas en las que se produce para cada ocurrencia de la mencionada columna.
SELECT SalesOrderNumber, COUNT(*) AS RecuentoFilas FROM Ventas GROUP BY SalesOrderNumber HAVING COUNT(*) > 1 ORDER BY SalesOrderNumber

Si además queremos ver el detalle de los registros que cumplen esta condición de duplicidad, situaremos la anterior sentencia (con ligeros retoques) como una subconsulta sobre la tabla Ventas, cruzando por el campo SalesOrderNumber.
SELECT * FROM Ventas WHERE SalesOrderNumber IN ( SELECT SalesOrderNumber FROM Ventas GROUP BY SalesOrderNumber HAVING COUNT(*) > 1 ) ORDER BY SalesOrderNumber

Empleando en la consulta externa la instrucción DELETE junto a una condición adicional, podemos borrar selectivamente ciertas filas de cada grupo de datos duplicados, como vemos en el siguiente ejemplo, donde eliminamos aquellos registros con el valor 711 en la columna ProductID.

ROW_NUMBER
Supongamos ahora que del conjunto de resultados con valores duplicados queremos operar sobre una fila muy concreta de las que componen la repetición. Mediante la siguiente consulta tomaremos en primer lugar una muestra de registros para ilustrar mejor nuestro propósito.
SELECT * FROM Ventas WHERE SalesOrderNumber IN ('SO58536','SO68514') ORDER BY SalesOrderNumber, ProductID
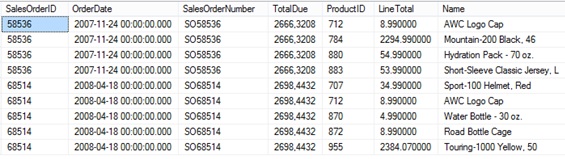
Al igual que en los anteriores ejemplos, por cada valor distinto en la columna SalesOrderNumber existe un número variable de registros con dicho valor repetido. Si tuviéramos que seleccionar de cada grupo la fila situada en una determinada posición podríamos conseguirlo mediante la función ROW_NUMBER, como demostraremos posteriormente.
ROW_NUMBER, como su nombre indica, asigna un número de fila a cada registro del conjunto de resultados obtenidos a partir de una consulta.
En su forma de uso más básica, junto al nombre de la función hemos de utilizar la cláusula OVER, y dentro de esta la partícula ORDER BY, para que la asignación del número de fila se haga en un orden concreto. En el siguiente ejemplo generamos un número de fila para la tabla Ventas, ordenando el resultado por la columna LineTotal.
SELECT *, ROW_NUMBER() OVER(ORDER BY LineTotal) AS NumeroFila FROM Ventas WHERE SalesOrderNumber IN ('SO58536','SO68514')
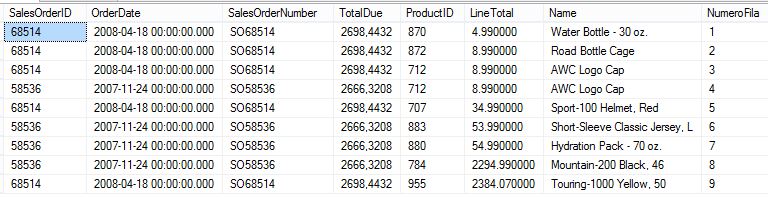
Resulta importante resaltar que la columna utilizada dentro de ROW_NUMBER para ordenar las filas no tiene que ser obligatoriamente la misma que empleemos en la sentencia SELECT. Variando el ejemplo anterior, a continuación vemos que los números de fila asignados por la función seguirán siendo los mismos, pero la ordenación del conjunto de resultados obtenido se hará por la columna Name.
SELECT *, ROW_NUMBER() OVER(ORDER BY LineTotal) AS NumeroFila FROM Ventas WHERE SalesOrderNumber IN ('SO58536','SO68514') ORDER BY Name

ROW_NUMBER se encuentra entre el grupo de funciones englobadas en la categoría conocida como funciones de ventana (Window functions), debido a que aparte del funcionamiento que acabamos de ver, nos permiten definir particiones (ventanas) de filas dentro de un conjunto de resultados sobre los que actuar de forma independiente, generando un número para cada fila de la partición, la cual especificaremos en la cláusula OVER de esta función mediante la partícula PARTITION BY.
Al aplicar, por tanto, ROW_NUMBER sobre nuestra consulta, particionaremos por la columna SalesOrderNumber de la siguiente manera.
SELECT *, ROW_NUMBER() OVER(PARTITION BY SalesOrderNumber ORDER BY ProductID) AS NumeroFila FROM Ventas WHERE SalesOrderNumber IN ('SO58536','SO68514')

Obsérvese que, tal y como hemos mencionado anteriormente, la columna mediante la que establecemos la partición es independiente de la columna que utilizamos para ordenar las filas dentro de la partición, es decir, que mientras que definimos la partición sobre SalesOrderNumber, dentro de cada partición las filas se ordenarán por ProductID.
Como vemos en el actual apartado, y como tendremos ocasión de comprobar en los siguientes, la cláusula OVER es el denominador común a todas las funciones de ventana, ya que representa el elemento que determina la forma en la que el conjunto de filas de la consulta se particiona y ordena antes de que la función de ventana sea aplicada. Una vez establecidas las particiones y el orden en las filas, se aplica el cálculo correspondiente a cada una de ellas según la función de ventana utilizada: asignación de un número de fila, obtención del primer o último valor, etc.
Eliminar una fila con posición intermedia dentro de un grupo de datos duplicados
Como continuación de lo expuesto en el apartado anterior, supongamos que del siguiente conjunto de datos particionado mediante ROW_NUMBER, queremos eliminar la fila de cada partición que ocupa la tercera posición.
SELECT *, ROW_NUMBER() OVER(PARTITION BY SalesOrderNumber ORDER BY ProductID) AS NumeroFila FROM Ventas WHERE SalesOrderNumber IN ('SO43670','SO43676','SO43693','SO43853') ORDER BY SalesOrderNumber, NumeroFila
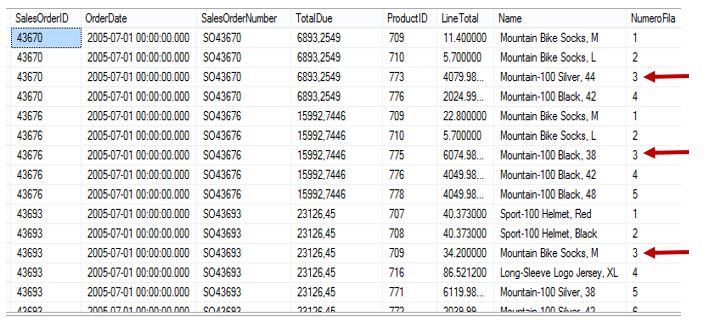
La solución pasa por situar la anterior consulta dentro de una expresión común de tabla (CTE, common table expression) y realizar el borrado de registros desde la sentencia externa a la CTE como vemos a continuación, especificando en la cláusula WHERE el número de fila a borrar.
WITH cteFilas AS ( SELECT *, ROW_NUMBER() OVER(PARTITION BY SalesOrderNumber ORDER BY ProductID) AS NumeroFila FROM Ventas WHERE SalesOrderNumber IN ('SO43670','SO43676','SO43693','SO43853') ) DELETE FROM cteFilas WHERE NumeroFila = 3
Llegados a este punto concluimos la primera parte del presente artículo. En la siguiente entrega veremos la forma de seleccionar valores en la primera y última fila de las particiones de datos duplicados.


anonymous
Tal y como apuntábamos al finalizar la primera parte del artículo, en esta segunda entrega
Jhunior
hola; estoy verificando valores duplicados en mi base de datos y estoy usando la siguiente consulta:
SELECT NUMERO_PEDIDO, COUNT(NUMERO_PEDIDO) AS CANTIDAD FROM TB_VENTAS
GROUP BY NUMERO_PEDIDO
HAVING COUNT(NUMERO_PEDIDO)>1
ORDER BY NUMERO_PEDIDO ASC
pero lo que necesito es ejecutarlo con un UPDATE para que se quede actualizado en el campo Cantidad y se visualice al exportar dicha tabla.
lmblanco
Hola Jhunior
Para hacer el recuento de los registros duplicados puedes utilizar la función COUNT() junto a la cláusula OVER, particionando por el número de pedido, para obtener la cantidad de registros que tienen el mismo número de pedido. Esa sentencia la encierras en una expresión de tabla mediante la palabra clave WITH y en la sentencia externa a la expresión de tabla realizas la asignación al campo que contendrá la cantidad de registros repetidos. Te paso un ejemplo para que puedas hacerte una mejor idea:
;with
tblCalcularDuplicados as
(
select
SalesOrderNumber
,SalesOrderLineNumber
,count(*) over(partition by salesordernumber) as RecuentoFilasPedido
from FactInternetSales
)
update FactInternetSales
set Cantidad=tblCalcularDuplicados.RecuentoFilasPedido
from tblCalcularDuplicados
where FactInternetSales.SalesOrderNumber=tblCalcularDuplicados.SalesOrderNumber
Un saludo
kiquenet
Muy bueno , Luismi , qué siga la serie!!
lmblanco
Hola Enrique
Muchas gracias por el interés 🙂
Un saludo,
Luismi
daniel
buen dia
como se puede hacer esto mismo par a mysql ?
de antemano les agradesco su ayuda
lmblanco
Hola Daniel
Te adjunto algunos recursos en la web sobre este aspecto para MySQL, espero que te sean de utilidad:
http://stackoverflow.com/questions/854128/find-duplicate-records-in-mysql
http://www.w3resource.com/mysql/advance-query-in-mysql/find-duplicate-data-mysql.php
https://www.tutorialspoint.com/mysql/mysql-handling-duplicates.htm
Un saludo,
Luismi
roberto
Muy bueno y util, el tema es que no quier borrar los duplicados (son campo varchar) sino corregirlos. Agregar una letra o un numero diferente a cada duplicado para que no afecte mi tabla (Quiero poner una restricccion unique), El problema son los que son mas de dos duplicados. Gracias por tu atencion.
lmblanco
Hola Roberto
Gracias por tu interés en el artículo, celebro que te haya resultado de utilidad.
Respecto a la duda que planteas, si lo que necesitas no es eliminar duplicados sino diferenciarlos puedes probar a generar mediante una expresión de tabla un valor, por ejemplo un número de fila consecutivo para cada grupo de duplicados y añadirlo después a uno de los campos para diferenciar estos duplicados.
Si utilizas el último ejemplo de código fuente de este artículo, sustituimos la parte de borrado por una de actualización de la siguiente forma:
WITH
cteFilas AS
(
SELECT *,
ROW_NUMBER() OVER(PARTITION BY SalesOrderNumber ORDER BY ProductID) AS NumeroFila
FROM Ventas
WHERE SalesOrderNumber IN (‘SO43670′,’SO43676′,’SO43693′,’SO43853’)
)
update cteFilas
set SalesOrderNumber += ‘_’ + CONVERT(varchar,NumeroFila);
Aunque no está muy elaborado, espero que te sirva como punto de partida para adaptarlo a lo que necesitas.
Un saludo,
Luismi
kary
Hola necesito de tu ayuda….
En una tabla tengo esas 3 columnas NOMBRE, ROL y FECHA.
Al momento de hacer el Query, necesito borrar los campos repetidos, lo que va a definir el borrado será la fecha. El que sea más viejo se va y el más reciente se queda
lmblanco
Hola kary
Una forma de hacer el borrado de los datos que necesitas sería utilizar una consulta añadiendo dinámicamente una columna con row_number() que te permita identificar, para un grupo de registros correspondiente al mismo nombre, el número de registro dentro de dicho grupo. De esta forma el registro más viejo, que es el que quieres borrar, queda el primero.
Dicha consulta la incluyen en una expresión de tabla (CTE) y fuera de la expresión creas una sentencia de borrado para los registros que se hayan quedado clasificados con el número de fila 1, que corresponderían al más viejo de cada grupo, y que son los que quieres borrar. La sentencia a usar sería similar a la siguiente:
//———————————————————
with
tblDatos as (
select
nombre,rol,fecha,
row_number() over(partition by nombre order by fecha) as NumeroFila
from tabla
)
delete from tblDatos
where NumeroFila=1
//———————————————————
Espero que te sirva para lo que necesitas.
Un saludo,
Luismi
MARIANELA ANDREA MARCHANT
Por favor que alguien me ayude ; estoy tratado traer identificar los documentos repetidos de la siguiente consulta pero no me resulta (¿será porque tengo varias tablas enlazadas?) ejemplo:
Cotización | Fila
12345 1
12345 2
12345 3
12346 1
12346 2
y me consulta completa es:
seLECT Distinct
T0.[CardName][Cliente],
T0.[DocNum][Cotización],
t0.DocTotal as Total,
T0.[DocDate][Fecha],
t0.u_IND_Status,
Case
When T0.[DocStatus] = ‘O’ and T0.[Canceled] = ‘N’ Then ‘Abierto’
When T0.[DocStatus] = ‘C’ and T0.[Canceled] = ‘N’ Then ‘Cerrado’
When T0.[DocStatus] = ‘C’ and T0.[Canceled] = ‘Y’ Then ‘Cancelado’
End ‘Estado’,
–ORDEN DE VENTA
T2.[DocNum][Orden de venta],
T2.[DocDate][Fecha],
t2.Doctotal Total,
case
When T2.[DocStatus] = ‘O’ and T2.[Canceled] = ‘N’ Then ‘Abierto’
When T2.[DocStatus] = ‘C’ and T2.[Canceled] = ‘N’ Then ‘Cerrado’
When T2.[DocStatus] = ‘C’ and T2.[Canceled] = ‘Y’ Then ‘Cancelado’
End ‘Estado’,
–ENTREGA
t4.docentry,
T4.[DocNum][Entrega],
T4.[DocDate][Fecha],
t4.DocTotal Total,
–T4.[Doctime][Inicio],
–(T4.[DocTime] – T2.[DocTime])[Tiempo],
Case
When T4.[DocStatus] = ‘O’ and T4.[Canceled] = ‘N’ Then ‘Abierta’
When T4.[DocStatus] = ‘C’ and T4.[Canceled] = ‘N’ Then ‘Cerrada’
When T4.[DocStatus] = ‘C’ and T4.[Canceled] = ‘N’ Then ‘Cancelada’
End ‘Estado’,
–FACTURA
t6.docentry,
T6.[DocNum][Factura],
T6.[DocDate][Fecha],
t6.DocTotal Total,
Convert(Int,(T6.[DocDate]-T4.[DocDate]))[DíasEmF],
–T6.[DocTime][Inicio],
Case
When T6.[DocStatus] = ‘O’ and T6.[Canceled] = ‘N’ Then ‘Abierto’
When T6.[DocStatus] = ‘C’ and T6.[Canceled] = ‘N’ Then ‘Cerrado’
When T6.[DocStatus] = ‘C’ and T6.[Canceled] = ‘Y’ Then ‘Cancelado’
End ‘Estado’,
–DEVOLUCION
t11.DocNUm Dev,
–Nota de Credito
T9.DocNum NC
FROM [dbo].[OQUT] T0
Left Join RDR1 T1 On T1.BaseRef = T0.DocNum
Left JOIN ORDR T2 ON T1.DocEntry = T2.DocEntry
Left Join DLN1 T3 ON T3.BaseRef = T2.DocNum
Left JOIN ODLN T4 ON T3.DocEntry = T4.DocEntry
left Join INV1 T5 On T5.BaseRef = T4.DocNum
Left Join OINV T6 On T5.DocEntry = T6.DocEntry
LEFT JOIN OCRD T7 ON T7.CardCode = T0.CardCode
LEFT JOIN RIN1 T8 ON T8.BaseEntry=t5.DocEntry and T8.BaseType=t5.ObjType AND T8.BaseLine =T5.LineNum
LEFT JOIN ORIN T9 ON T9.DocEntry=T8.DocEntry
LEFT JOIN RDN1 T10 ON T10.BaseEntry=T3.DocEntry AND T10.BaseType=T3.ObjType AND T10.BaseLine=T3.LineNUM
LEFT JOIN ORDN T11 ON T11.DocEntry=T10.DocEntry
INNER JOIN DLN12 T12 ON T4.DocEntry =T12.DocEntry
WHERE (T0.DocDate Between ‘20170101’ and ‘20171231’)
AND T7.IndustryC = 2
AND T0.CANCELED = ‘N’
order by 2
lmblanco
Hola Marianela
Consulta la segunda parte de este artículo, en ella se proponen algunas técnicas adicionales de manejo de duplicados. Espero que te sirvan de ayuda.
Un saludo,
Luismi
Andres
Muy buena la información, estimado estoy tratando de aplicar lo que informas en este post, me gustaría que me ayudaras con una con una consulta:
necesito mostrar un select que lo ordene por los registros que mas se repiten al que menos se repite:
Ejemplo.. tengo una tabla que registra la la asistencia de trabajadores, tengo un filtro que busco los trabajadores que llegaron atrasados durante un mes pero me gustaría que quedaran ordenados por el trabajador que llego mas atrasado al que llego menos atrasados.
Gracias
lmblanco
Hola Andrés
Gracias por tu interés en el artículo. Respecto a la cuestión que planteas, una posibilidad sería algo parecido a lo siguiente:
SELECT
TrabajadorID,
FechaAsistencia,
ROW_NUMBER() OVER(PARTITION BY TrabajadorID ORDER BY FechaAsistencia) AS NumAsistenciaTrabajador
FROM Tabla
ORDER BY TrabajadorID, NumAsistenciaTrabajador DESC
Un saludo,
Luismi