
Tal y como apuntábamos al finalizar la primera parte del artículo, en esta segunda entrega expondremos algunas técnicas adicionales para la manipulación de datos duplicados, consistentes en el acceso a valores situados en la primera y última fila de las particiones que constituyen nuestros conjuntos de resultados.
Pero antes de proseguir, puesto que en el último ejemplo de la anterior entrega realizábamos un borrado de filas en la tabla Ventas, tendremos que volver a ejecutar la sentencia de creación e inserción de datos en dicha tabla, que podemos encontrar al comienzo de la primera parte de este artículo.
Encontrar la primera fila en un conjunto de datos duplicados
Si necesitamos obtener de un conjunto de resultados con datos repetidos el valor de una columna situada en la primera fila podemos emplear la función FIRST_VALUE. Aunque es cierto que lograríamos el mismo efecto mediante el uso de TOP 1, FIRST_VALUE, al ser una función de ventana, presenta como ventaja adicional la definición de particiones mediante la cláusula OVER (al igual que ROW_NUMBER), con lo cual obtendremos el primer valor de cada partición. Veamos este aspecto de forma práctica.
SELECT *, FIRST_VALUE(LineTotal) OVER(PARTITION BY SalesOrderNumber ORDER BY ProductID) AS PrimerValor FROM Ventas WHERE SalesOrderNumber IN ('SO58536','SO68514') ORDER BY SalesOrderNumber, ProductID
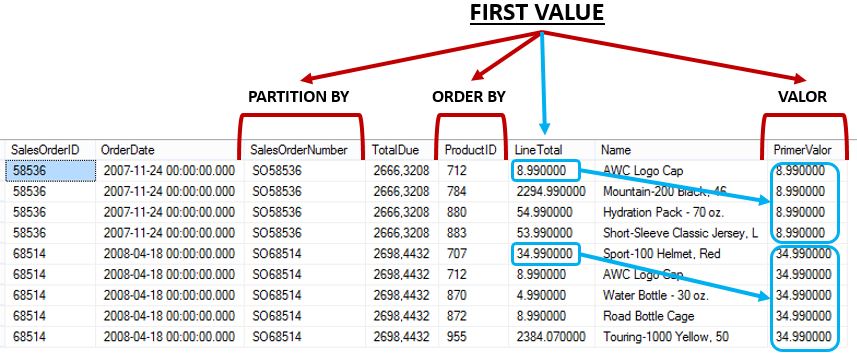
Lo que hace la anterior consulta es añadir una nueva columna al conjunto de resultados con el primer valor de cada partición, pero lo que nosotros perseguimos es la obtención de la primera fila de cada una de dichas particiones. Para conseguir dicho objetivo situaremos dentro de una CTE (expresión común de tabla) una consulta que nos devuelva la información necesaria de cada primera fila. Cruzando este resultado con la tabla Ventas mediante una combinación de tipo INNER JOIN, obtendremos única y exclusivamente las primeras filas objeto de nuestra búsqueda.
WITH ctePrimeraFila AS ( SELECT DISTINCT SalesOrderNumber, FIRST_VALUE(LineTotal) OVER(PARTITION BY SalesOrderNumber ORDER BY ProductID) AS PrimerValor FROM Ventas WHERE SalesOrderNumber IN ('SO58536','SO68514') ) SELECT Ventas.* FROM Ventas INNER JOIN ctePrimeraFila ON Ventas.SalesOrderNumber = ctePrimeraFila.SalesOrderNumber AND Ventas.LineTotal = ctePrimeraFila.PrimerValor

En el caso de que nuestra versión de SQL Server (por ejemplo 2005) no disponga de FIRST_VALUE, y queramos crear una columna calculada conteniendo el valor de la primera fila de cada partición, también acudiremos al uso de expresiones de tabla (CTE), pero combinándolas esta vez con la función ROW_NUMBER.
WITH cteCalcularPrimerValor AS ( SELECT SalesOrderNumber, LineTotal, ROW_NUMBER() OVER(PARTITION BY SalesOrderNumber ORDER BY ProductID) AS NumeroFila FROM Ventas WHERE SalesOrderNumber IN ('SO58536','SO68514') ) , ctePrimerValor AS ( SELECT SalesOrderNumber, LineTotal AS PrimerValor FROM cteCalcularPrimerValor WHERE NumeroFila = 1 ) SELECT v.*, p.PrimerValor FROM Ventas AS v INNER JOIN ctePrimerValor AS p ON v.SalesOrderNumber = p.SalesOrderNumber ORDER BY v.SalesOrderNumber, v.ProductID
En el anterior bloque de código necesitamos dos CTEs: la primera nos ayuda a generar un número de orden para cada una de las filas del conjunto de resultados, mientras que en la segunda filtramos las filas de la primera CTE que en la columna del número de orden tengan el valor 1. Finalmente, en la consulta externa a las CTEs combinamos la tabla Ventas con la segunda CTE para obtener la columna correspondiente a los primeros valores, es decir, la columna que obtendríamos en caso de disponer de la función FIRST_VALUE.
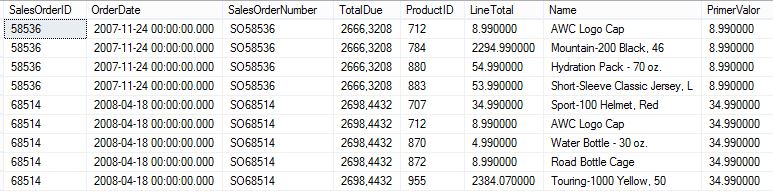
Por otro lado, y basándonos en la anterior consulta, quizá nos interese recuperar solamente las filas de cada partición que correspondan al primer valor, por lo que la consulta se simplificaría, filtrando en el resultado de la CTE aquellas filas en las que la columna calculada NumeroFila sea igual a 1.
WITH cteCalcularPrimerValor AS ( SELECT *, ROW_NUMBER() OVER(PARTITION BY SalesOrderNumber ORDER BY ProductID) AS NumeroFila FROM Ventas WHERE SalesOrderNumber IN ('SO58536','SO68514') ) SELECT * FROM cteCalcularPrimerValor WHERE NumeroFila = 1

Encontrar la última fila en un conjunto de datos duplicados
De igual forma nos hallaremos en algún momento ante la necesidad de obtener la última fila de un conjunto de resultados, con la dificultad añadida de que si hemos definido particiones, en un buen número de ocasiones la última fila de cada bloque de datos repetidos no estará en la misma posición, es decir, en una partición puede que la encontremos en la cuarta fila, en otra la sexta y así sucesivamente.
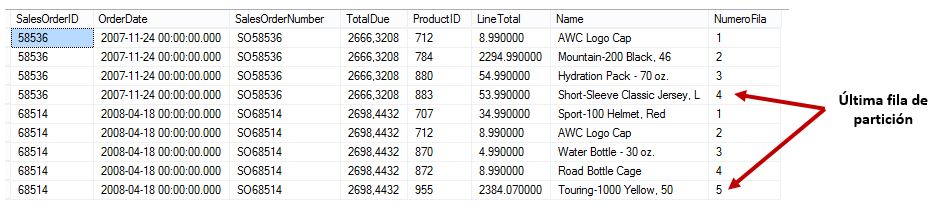
Para abordar este escenario disponemos de la función LAST_VALUE, que representa la versión opuesta de la función explicada en el apartado anterior, ya que su finalidad consiste en devolver un valor correspondiente a la última fila de un conjunto de resultados. Si dicho conjunto tuviera varias particiones creadas con la cláusula obligatoria OVER, obtendríamos el último valor de cada una de ellas. No obstante, comencemos por un ejemplo simple, sin particiones.
SELECT *, LAST_VALUE(LineTotal) OVER(ORDER BY Name) AS UltimoValor FROM Ventas WHERE SalesOrderNumber IN ('SO58536','SO68514') ORDER BY Name
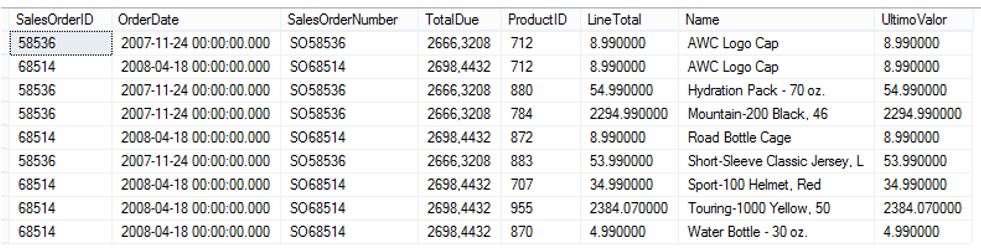
¿Qué ha ocurrido aquí? Aparentemente el uso que hacemos de LAST_VALUE es correcto: pasamos como parámetro la columna LineTotal, de la cual queremos obtener el valor de la última fila, y mediante la cláusula OVER establecemos el orden que tendrán las filas a efectos de esta función. Sin embargo, la columna calculada UltimoValor no devuelve en todos los casos 4.990000, que es el valor que debería tener si observamos los datos resultantes en la columna LineTotal de la última fila., por lo que podemos deducir que el uso de LAST_VALUE no resulta, a priori, tan intuitivo como el de FIRST_VALUE.
El problema radica en que dentro de OVER no hemos especificado el criterio que establece los límites de la ventana/partición (si no declaramos una partición, SQL Server toma implícitamente todas las filas de la consulta como una especie de partición predeterminada), por lo que una función de ventana como LAST_VALUE no sabe «orientarse» a la hora de calcular el último valor, puesto que no tiene los puntos de referencia necesarios para determinarlo.
Consultando la documentación relativa a OVER veremos que existe un conjunto de palabras clave (ROWS, CURRENT ROW, PRECEDING, FOLLOWING, UNBOUNDED, etc.) que serán las encargadas de dotar a las filas de este comportamiento, por lo que si escribimos la sentencia de la siguiente manera obtendremos el resultado deseado.
SELECT *, LAST_VALUE(LineTotal) OVER( ORDER BY Name ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING ) AS UltimoValor FROM Ventas WHERE SalesOrderNumber IN ('SO58536','SO68514') ORDER BY Name
Lo que hemos indicado ahora en la función de ventana se podría traducir como: “Obtener el valor de la última fila (LAST_VALUE) ordenando (ORDER BY) por la columna Name las filas (ROWS) que se encuentran entre (BETWEEN) la actual (CURRENT ROW) y el final de la ventana/partición (UNBOUNDED FOLLOWING)».
De la sentencia y explicación del párrafo anterior lo que quizá pueda ocasionar una mayor confusión al lector sea la mención al concepto de fila actual (CURRENT ROW), por lo que esta cuestión merece que le dediquemos un tratamiento más detallado.
En la consulta sobre la que estamos trabajando, una vez que se realiza la extracción principal de registros de la tabla, la cláusula OVER de la función LAST_VALUE toma el control para ordenar internamente las filas por la columna Name. Hecho esto, comienza el cálculo del valor para cada fila de la columna UltimoValor, siguiendo la pauta explicada a continuación.
La primera fila del conjunto de resultados pasa a ser la fila actual (CURRENT ROW), LAST_VALUE se desplaza hasta la última fila del conjunto de resultados, toma el valor de la columna LineTotal, vuelve a la fila actual y deposita dicho valor en la columna calculada UltimoValor.
A continuación, la segunda fila del conjunto se convierte en fila actual, realizando idéntica operación que en el caso anterior. Esta acción continuará repitiéndose hasta haber completado la asignación de valor en la columna UltimoValor para todas las filas.
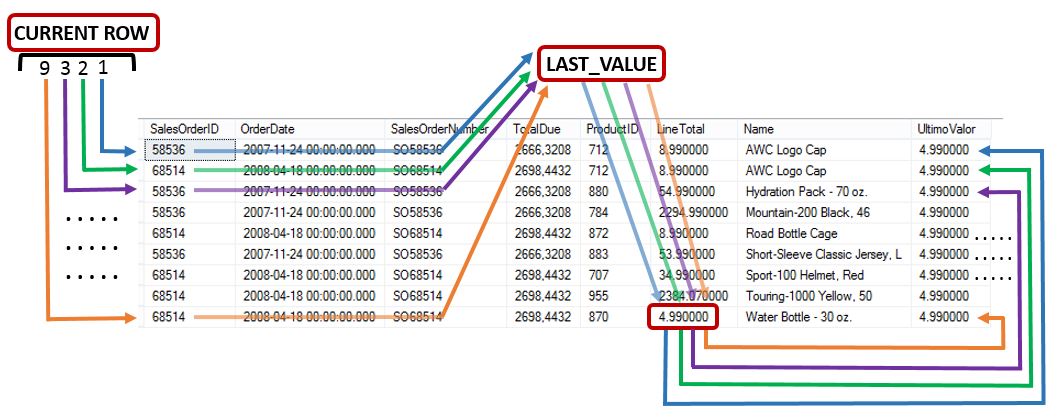
Volviendo a nuestro objetivo original: encontrar la última fila en un conjunto compuesto por grupos de datos duplicados; el único cambio que tendríamos que añadir a nuestra consulta sería la cláusula PARTITION BY, especificando el modo de particionamiento.
SELECT *, LAST_VALUE(LineTotal) OVER( PARTITION BY SalesOrderNumber ORDER BY Name ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING ) AS UltimoValor FROM Ventas WHERE SalesOrderNumber IN ('SO58536','SO68514') ORDER BY SalesOrderNumber, Name

Con la anterior sentencia, como habrá comprobado el lector, lo que realmente obtenemos es la información acerca de un valor en la última fila de cada partición en forma de columna calculada. Si al igual que ocurría al utilizar FIRST_VALUE, lo que ahora queremos conseguir con LAST_VALUE son las últimas filas de cada partición del conjunto de datos, volveremos a utilizar una CTE que devuelva esas filas, que cruzaremos en la consulta externa a la CTE con la tabla Ventas mediante INNER JOIN, logrando de esta manera las últimas filas de cada partición.
WITH cteUltimaFila AS ( SELECT DISTINCT SalesOrderNumber, LAST_VALUE(LineTotal) OVER( PARTITION BY SalesOrderNumber ORDER BY Name ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING ) AS UltimoValor FROM Ventas WHERE SalesOrderNumber IN ('SO58536','SO68514') ) SELECT Ventas.* FROM Ventas INNER JOIN cteUltimaFila ON Ventas.SalesOrderNumber = cteUltimaFila.SalesOrderNumber AND Ventas.LineTotal = cteUltimaFila.UltimoValor

Supongamos ahora que necesitamos implementar esta funcionalidad en una versión de SQL Server que no soporta la función LAST_VALUE, en cuyo caso tendremos que optar por una solución al problema un poco más artificiosa a través de ROW_NUMBER.
SELECT *, ROW_NUMBER() OVER(PARTITION BY SalesOrderNumber ORDER BY Name) AS NumeroFila FROM Ventas WHERE SalesOrderNumber IN ('SO58536','SO68514')
Aplicando ROW_NUMBER a la consulta en la forma que acabamos de mostrar obtendremos dos particiones, en una de ellas la última fila será la cuarta, y en la otra la quinta.

Como hemos comentado anteriormente, si trabajamos con un conjunto de resultados compuesto por muchas particiones, la variación en la posición de la última fila para cada partición será muy grande, por lo que para acceder a dicha fila de un modo uniforme podemos recurrir a un sencillo truco, consistente en ordenar de forma descendente la partición usando la partícula DESC en la cláusula ORDER BY de OVER. De este modo, en la columna calculada NumeroFila, a las últimas filas se les asignará el número 1.
SELECT *, ROW_NUMBER() OVER(PARTITION BY SalesOrderNumber ORDER BY Name DESC) AS NumeroFila FROM Ventas WHERE SalesOrderNumber IN ('SO58536','SO68514')
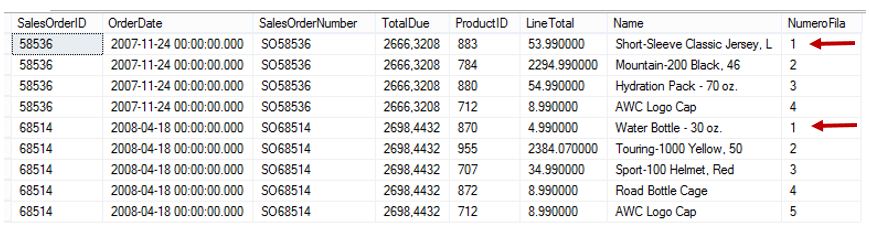
Si ahora queremos conseguir el mismo efecto que la función LAST_VALUE utilizaremos una combinación de dos CTEs: en la primera de ellas, cteCalcularUltimoValor, calcularemos el número de posición para la última fila tal y como acabamos de ver, mientras que en la siguiente, cteUltimoValor, filtraremos las filas obtenidas de cteCalcularUltimoValor, quedándonos sólo con las que tienen el valor 1 en la columna NumeroFila, o lo que es lo mismo, las últimas filas de cada partición. Por último, en la consulta externa a las CTEs combinaremos la tabla Ventas y cteUltimoValor para obtener todos los datos, incluyendo la columna calculada del último valor.
WITH cteCalcularUltimoValor AS ( SELECT SalesOrderNumber, LineTotal, ROW_NUMBER() OVER(PARTITION BY SalesOrderNumber ORDER BY Name DESC) AS NumeroFila FROM Ventas WHERE SalesOrderNumber IN ('SO58536','SO68514') ) , cteUltimoValor AS ( SELECT SalesOrderNumber,LineTotal AS UltimoValor FROM cteCalcularUltimoValor WHERE NumeroFila = 1 ) SELECT v.*, u.UltimoValor FROM Ventas AS v INNER JOIN cteUltimoValor AS u ON v.SalesOrderNumber = u.SalesOrderNumber ORDER BY v.SalesOrderNumber, v.Name
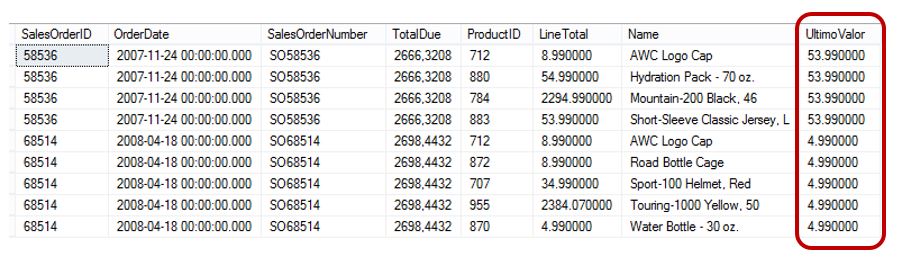
En el caso de que solamente necesitemos los últimos registros de cada grupo, retocaremos la anterior sentencia, filtrando aquellos en que la columna NumeroFila tenga el valor 1.
WITH cteCalcularUltimoValor AS ( SELECT *, ROW_NUMBER() OVER(PARTITION BY SalesOrderNumber ORDER BY Name DESC) AS NumeroFila FROM Ventas WHERE SalesOrderNumber IN ('SO58536','SO68514') ) SELECT * FROM cteCalcularUltimoValor WHERE NumeroFila = 1

Conclusión
La incorporación progresiva de las funciones de ventana al motor de datos de SQL Server constituye una potente herramienta, aplicable a multitud de operaciones tales como la gestión de duplicados presentada en el presente artículo. Confiamos en que los ejemplos aquí expuestos ayuden al lector a la hora de resolver los problemas que pueda encontrar en su trabajo de tratamiento de datos duplicados.


JUAN CASTRO ISLAS
Saludos Luis.
Mil gracias por tu articulo, tenia varios días tratando de hacer una consulta sin duplicados.
Por fin ya me quedo, gracias a tus ejemplos.
Espero sigas adelante con tu blog, me salvaste la chamba.
lmblanco
Hola Juan
Muchas gracias por tu opinión y celebro que el blog te haya resultado de ayuda.
Un saludo,
Luismi