Diapositivas de la formación de C++ que imparto de vez en cuando. No están totalmente actualizadas, pero cubren hasta C++ 11, las pequeñas mejoras en C++ 14 no están, pero tampoco son significativas.
Industría 4.0 2017 – Almacenamiento y procesamiento de datos en la nube
Presentación del evento Industria 4.0 que Plain Concepts organiza anualmente en Bilbao. Hablé de almacenamiento y procesamiento de grandes volumenes de datos en la nube. Hablamos de Data Lake, Cosmos DB, SQL Azure y bases de datos de series temporales como InfluxDb y OpenTSDB.
Seguridad en SQL Server: Mis ppts del Master de Ciberseguridad de la Universidad de Mondragón
¿Cómo liberar espación de disco en MySql?
Un problema habitual en las base de datos es reclamar el espacio ocupado por los datos. Una situación contraintuitiva que se da a menudo, sobre todo en usuarios noveles, es que tras borrar datos de una base de datos el espacio ocupado en disco por los archivos de la base de datos. Esto es completamente normal, de hecho es una optimización, asignar espacio de disco a una base de datos es un proceso costoso y devolverlo también. Una vez asignado el espacio de disco a la base de datos se asume que aunque se borren datos este se volverá a utilizar y por lo tanto no se devuelve de manera automática (aunque algunas bases de datos permiten configurar esa ‘autodevolución’ de espacio, cosa que por lo general no es buena idea).
En MySql la situación no es diferente que en otras base de datos. Lo que voy a describir en este post es como reclamar este espacio. El procedimiento aquí descrito sirve para versiones relativamente modernas de MySql y para el gestor de tablas InnoDB.
El primer paso, obviamente es borrar los datos.
Una vez borrados los datos el comando OPTIMIZE TABLE es lo que necesitas. Ojo, este comando lo que hace es una copia completa de la tabla optimizando el espacio usado por la misma. Es decir si tenemos una tabla que ocupa N necesitaremos aproximadamente N – ESPACIO_LIBRE_EN_LA_TABLA para poder optimizarla y liberar espacio. Esto puede ser un serio problema si el disco está lleno hasta arriba.
Para saber cuanto espacio libre, y ocupado tenemos en nuestras tablas y por tanto cuanto podremos recuperar esta consulta es muy útil:
SELECT TABLE_SCHEMA, TABLE_NAME, DATA_FREE FROM INFORMATION_SCHEMA.TABLES
ORDER by DATA_FREE DESC
Espero que os sea útil.
¿Hasta donde podemos llegar?
 Un anuncio de Microsoft decia: ‘hasta donde quieres llegar hoy’ o algo así, pero la pregunta es más bien ¿hasta donde puede llegar la ingeniería del software?. Comenta Gustavo, vecino de blog y uno de los grandes de Sharepoint (y no solo de Sharepoint) que cada vez la complejidad de los proyectos de Sharepoint es mayor, tanto como para que en muchas ocasiones lo mejor sea esconder la cabeza como un avestruz. Yo lo se bien, pase de conocer a fondo la versión 2003 a caer en la sima de la transición a 2007. Hace tiempo que deje de ser un experto en Sharepoint, si es que alguna vez lo fui del todo, el salto a la versión 2007 me supero, demasiada complejidad para un humano mortal.
Un anuncio de Microsoft decia: ‘hasta donde quieres llegar hoy’ o algo así, pero la pregunta es más bien ¿hasta donde puede llegar la ingeniería del software?. Comenta Gustavo, vecino de blog y uno de los grandes de Sharepoint (y no solo de Sharepoint) que cada vez la complejidad de los proyectos de Sharepoint es mayor, tanto como para que en muchas ocasiones lo mejor sea esconder la cabeza como un avestruz. Yo lo se bien, pase de conocer a fondo la versión 2003 a caer en la sima de la transición a 2007. Hace tiempo que deje de ser un experto en Sharepoint, si es que alguna vez lo fui del todo, el salto a la versión 2007 me supero, demasiada complejidad para un humano mortal.
En mi opinión lo que Gustavo comenta no solo está ocurriendo en Sharepoint. Es un problema generalizado, cada vez más voces importantes del mundo de la ingeniería de software se preguntan si no hemos alcanzado un punto de singularidad en el que la complejidad de los problemas a resolver se ha incrementado más allá de lo manejable.
Hace poco veía un proyecto que han hecho una compañeros de Plain Concepts. La interfaz es realmente acojonante, lo que antes serían aburridas cajitas de texto y etiquetas ahora son preciosos controles de WPF que informan visualmente del estado de los aparatos que la aplicación monitoriza. Se cae la baba viendo la interfaz. Pero eso tiene un precio. Hay miles de líneas de WPF y XAML. ¡Miles de líneas en la interfaz de usuario!. Se que muchas son generadas, pero me da igual, generadas o no son fuente de complejidad. La herramienta las genera, pero tu las mantienes y cuando la herramienta falla o la abstracción fuga, el problema es tuyo. Más código más problemas.
Los sistemas son cada vez más complejos, exponencialmente más complejos, pero las herramientas han cambiado solo sutilmente. Ya nos sabemos eso de KISS, si, pero no es suficiente. En esencia, desde que Grace Murray, almirante de la marina estadounidense y probablemente la mujer más influyente en la historia de la ingeniería de software, invento el compilador, no se ha producido un cambio cualitativo importante en la forma en que se hace software. Codificar, compilar, depurar. Solo se han añadido billones de horas hombre al desarrollo de software. Fuerza bruta. El problema es hasta donde escala esta aproximación… cada vez parece más que hemos tocado techo. Hay quien incluso ha puesto nombre a este problema: el dilema de la divergencia del software. Ahí es nada…
Para que os hagáis una idea. Un avión de caza de los años 60, tenía típicamente unas cincuenta mil líneas de código, un caza moderno unos cinco millones de líneas de código. Cada vez me da más por los aviones para hablar de software :). En este periodo, pese a la evolución de las herramientas, los estudios más optimistas sostiene que se ha doblado la productividad de los desarrolladores. Y mucha de esa productividad se ha ido en actividades de coordinación entre los miembros el equipo.
Barry Boehm, padre del modelo COCOMO y padre del ciclo de vida en espiral, comentaba en 2004, en un conferencia auspiciada por el DoD (Department of Defence, el mayor contratista de software del mundo por mucho), que ‘la cantidad de software que el DoD necesita crece exponencialmente, por lo tanto nunca podremos completarlo en un tiempo finito de tiempo’, para echarse a llorar… o no, también se puede hacer la lectura positiva: los informáticos tenemos una cantidad de trabajo infinita por hacer.
Yo personalmente soy pesimista. Todos los intentos de atajar la complejidad que hemos realizado han sido en vano. Los patrones parecían prometedores, pero aunque útiles no han supuesto una revolución. Las herramientas 4GL se postularon como una especie de bálsamo de Saxafrax, que se quedo en nada ¿alguien usa 4GL?. Las herramientas de modelado… en fin… esperemos a Oslo, pero mucho me temo que tampoco será mágico… y necesitamos mucha magia. Las herramientas no van a ser la solución al problema. Fijaros, llevo programando desde VB3.0. En la caja de todas la herramientas de programación que he usado desde entonces ponía algo parecido a ‘mejora tu productividad un X%, siendo X > 20’. He conocido VB4, VB5, VS6, VS2001 (productividad con esteroides gracias a .NET), VS2003… hasta VS2010. Si cada versión hubiese mejorado mi productividad lo que su marketing prometía ahora yo sería capaz de programar con la mente.
En el lado de los procesos de desarrollo, me conformo no ya con ganar productividad, sino simplemente con poner orden en el caos que se contempla en la gran mayoría de los equipos de desarrollo. Mejoras lo que se dice mejoras, se ven, pero no radicales no nos engañemos.
Ahora todos los proyectos dan miedo, mucho miedo, no hay proyectos sencillos. No los hay. Aun recuerdo cuando, en mi época de freelance, yo, con veinte añitos recién cumplidos era el rey del mambo: ¡sabia que existían los módulos de clase, sabía que existía DCOM y como hablar con SQL Server!, estaba a años luz del programador medio. Ahora todos los proyectos dan miedo. Hay unas frase de Linus Tordvals que son esclarecedoras: ‘No esperes hace nada grande en poco tiempo’ dijo, ‘he estado trabajado en Linux trece años, y creo que lo hare durante bastante tiempo más. Si hubiese pensando que me estaba metiendo en algo tan grande, nunca hubiese empezado’. Esclarecedor. Hay que tener un punto de incauto para meternos en los proyectos que nos metemos.
El tema se resume en dos frases, una de Donal Knuth: ‘hacer software es difícil’ y otra de Fred Brooks: ‘no hay balas de plata’ que da título a uno de los grandes ensayos de la historia de la ingeniería del software. Brooks es también el padre de la ley que lleva su nombre y que dice que ‘añadir desarrolladores a un proyecto retasado solo lo retrasa más’, luego extrapolando esta ley, añadir más fuerza de desarrollo no va a arreglar el problema como ya he comentado.
La paradoja es que dificultad es tal que necesitamos unas balas de plata que no tenemos en nuestra arsenal. Unamos a esto que la ley de Moore ya no está ahí para salvarnos el culo permitiéndonos cambiar complejidad por ciclos de reloj. Tenemos una tormenta perfecta. ¡Hemos llegado al límite!.
¿Sois vosotros igual de pesimistas que yo? Gustavo creo que sí.
Y la agilidad llegó a Visual Studio
Visual Studio 2012 es la cuarta versión de las herramientas de desarrollo de Microsoft que pone al equipo de desarrollo en el centro de la herramienta. Fue en la versión 2005 de Visual Studio cuando Microsoft pasó de construir herramientas enfocadas en el desarrollador a crear herramientas enfocadas en el equipo. Desde entonces se ha recorrido un larguísimo camino en el que los equipos de desarrollo versión tras versión hemos ido encontrando en Visual Studio novedades que extendían sus capacidades e integraban a todos los roles de un equipo de desarrollo en torno a una herramienta común. Un hito importante fue la llegada, en la versión 2010, de Test Manager y Lab Management como herramientas clave de ayuda a los perfiles de equipo centrados en la calidad. La adición de estas herramientas convirtió a nuestros testers en ciudadanos de primera clase dentro de Visual Studio dotándoles del soporte necesario para gestionar planes de prueba, resultados de pruebas y entornos en los que ejecutarlas. Pero sin duda la versión 2012 supone un salto cualitativo en Visual Studio: Visual Studio es la primera versión que es totalmente ágil, la primera versión que abraza los principios del desarrollo de software ágil en todas sus dimensiones.
¿Qué es la agilidad en el desarrollo de software?
Si bien este es un tema sobre el que se han escrito no decenas sino cientos de libros, la mejor síntesis sigue siendo sin duda el Manifiesto Ágil, que podéis encontrar en www.agilemanifesto.org. Este es un tema muy amplio, por lo tanto permitidme que me centre en lo relativo a que es una herramienta ágil. Una herramienta ágil es aquella que te ayuda a seguir los principios ágiles y sobre todo aquella que no se interpone en tu camino a la hora de trabajar. Si tuviésemos que resumir en un solo aspecto clave los valores del agilísimo, que son muchos, yo me quedaría con que ser ágil es crear software de valor para tus clientes de manera continua. Parece una definición simple y evidente, pero esconde muchas dificultades.
¿Por qué es importante ser ágil?
Está claro que la agilidad no es un fin en sí misma sino un medio para conseguir una mayor competitividad. Desde Plain Concepts hemos liderado la implantación de metodologías ágiles y de Visual Studio como herramienta de ALM en un gran número de organizaciones de todos los tamaños. Si algo han tenido en común todas estas empresas es cuál era el objetivo último: desarrollar más rápido y construir el software correcto. En la última encuesta sobre el estado del desarrollo ágil el 80% de los encuestados respondían que acelerar el time to market era uno de los principales motivos para para adoptar herramientas y meto. El segundo motivo para adoptar metodologías ágiles, con un 78%, es gestionar la respuesta ante cambios. Sin duda las metodologías ágiles ayudan a cumplir estos objetivos, que creo que muchos de los lectores compartirán. Si nos preguntamos cuál es la mejor manera de mejorar nuestra velocidad de desarrollo sin duda la respuesta es construir el software correcto, son dos realidades íntimamente relacionadas. Si algo he aprendido en los últimos años es que un aspecto vital del desarrollo de software es construir solo aquello que es de verdadero valor para los usuarios. No hay característica más rápida de construir, depurar y mantener que aquella que no se implementa. Sé que esto puede sonar a perogrullada pero es algo que a menudo olvidamos. Mirad el siguiente gráfico resultado de un estudio del Standish Group:
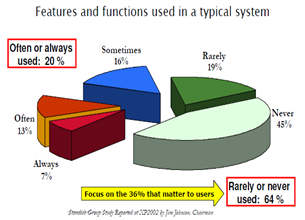
Es esclarecedor: el 64% por ciento de las características que construimos se utiliza raramente o nunca. Podemos pensar que a nosotros no nos pasa esto, que somos mejores que la media planificando qué características entran o no en nuestro software… De acuerdo, concedemos que somos mucho mejores, que solo el 30% o el 20% de lo que implementamos realmente no se usa… ¡es un desperdicio inaceptable en cualquier caso! A la vista de estos datos queda claro que nada es más efectivo a la hora de mejorar nuestra velocidad de desarrollo y construir el software adecuado que hacer una exquisita planificación de nuestro producto.
¿Cómo nos ayuda Visual Studio 2012?
Sin duda, versiones anteriores de Visual Studio brillaban con fuerza a la hora de ayudar a los equipos a implementar prácticas de ingeniería del software como pruebas unitarias, desarrollo guiado por pruebas, construcciones automatizadas, integración continua, etc… y no impedían el desarrollo ágil. Pero cojeaban en un aspecto clave: no nos ayudaban a planificar con agilidad y a visualizar nuestras planificaciones. Esto ha cambiado de manera radical en esta nueva versión. Todo ello gracias a que Microsoft ha puesto a disposición herramientas que permiten trabajar con nuestros requisitos, expresados como historias de usuario o no, de manera absolutamente ágil. Ahora basta con arrastrar y soltar elementos de nuestro backlog para mantener su prioridad actualizada, y lo que es mejor, en todo momento basándonos en nuestra velocidad de desarrollo podemos ver en qué iteración el equipo implementará una determinada característica. Además es más fácil que nuca recoger requisitos del usuario.

Pero recoger requisitos solo es una parte, asegurar que estos requisitos han sido correctamente entendidos y priorizados es tan importante como recogerlos. Para ello ahora contamos con una nueva herramienta en Visual Studio: la capacidad de construir storyboards con PowerPoint, herramienta con la que casi todos estamos más o menos familiarizados.

Además, aunque hayamos recogido los requisitos de manera adecuada todos sabemos que rara vez el cliente es capaz de expresar sus necesidades de manera correcta a la primera. Es aquí donde la mejora continua de las características implementadas en nuestro software, uno de los principios esenciales de las metodologías ágiles, toma el primer plano. Solo atendiendo a la voz de los usuarios y clientes podremos construir un software que les satisfaga y que logre un adecuado retorno de la inversión. Visual Studio 2012 nos proporciona una nueva herramienta gratuita, el Feedback Manager que nos permitirá recolectar el feedback de nuestros usuarios y compartirlo con el equipo de desarrollo de manera extremadamente simple.
En resumen, ninguna versión de Visual Studio anterior había permitido trabajar de manera tan ágil con requisitos, storyboards y, en general, colaborar con tanta facilidad con los clientes y usuarios para asegurarnos de que siempre estamos construyendo solo aquello que realmente aporta valor.
Emitiendo para toda la galaxia, ¿hay alguien ahí?: Lo que todo desarrollador debe saber sobre los eventos en .Net
La manera que las clases tiene de alertar a otras clases en los lenguajes orientados a objetos modernos es lanzar eventos. Una clase que no expone eventos, hace mucho más ardua la tarea de los desarrolladores que la consumen a la hora de detectar cambios en su estado. Una clase sin eventos es un clase incomunicada, que dirían los O’funk’illo.
En en sentido amplio, se podría decir que toda clase que diseñemos y que mantenga un estado, debería tener eventos. Si una clase mantiene estado, es evidente que ese estado va a cambiar a lo largo del ciclo de vida de los objetos que instanciemos. Es evidente también que si no exponemos eventos quien quiera enterarse de los cambios en el estado, no tendrá más opción que preguntar activamente a nuestro objeto, en lugar de esperar plácidamente a recibir notificaciones. Nada nuevo bajo el sol, el viejo conocido patrón Observer.
Los eventos son imprescindibles y en .Net son ciudadanos de primera categoría (no ocurre así en otros lenguajes como C++). Aun así, no es extraño ver malas implementaciones de eventos. Es un tema que muchos desarrolladores creen conocer bien y sin embargo se ven a menudo errores relacionados con la mala implementación de eventos. Y es que implementar bien un evento tiene más arte del que podría parecer y se pueden cometer más errores de los que uno puede pensar que varían en gravedad desde complicar la vida a las clases que deriven de nuestra clase que expone eventos hasta introducir condiciones de carrera difíciles de diagnosticar, pasando por simples incorrecciones de estilo. Lo peor de caso, es que al contrario que en otras ocasiones, por la propia naturaleza de estos errores, FxCop no es capaz de avisarnos de ellos.
Vamos al grano. Veamos la implementación más simple posible de un evento en .Net 2.0, los que hemos vivido los tiempos de .Net 1.0 y 1.1 sabemos que la palabra clave event solo es azúcar sintáctico que provoca que el compilador emita por nosotros un delegado. En los tiempos de 1.0 y 1.1 nosotros teníamos que declarar el tipo de delegado ‘a manopla’. Se trata de un evento que ni siquiera implementa su propia clase de argumento del evento. Sería algo como sigue:
class Publisher
{
public event EventHandler SampleEvent;
public void FunctionThatProducesTheEvent()
{
SampleEvent(this, EventArgs.Empty);
}
}
¿Cuántos errores puede ver en esta implementación? Uno, dos, tres… si no les ves sigue leyendo.
¿Qué pasa si no hay nadie escuchando?
Generalmente, en una conversación, para que se produzca una comunicación correcta debe haber una parte emitiendo y otra recibiendo. Evidentemente esto no aplica si se trata de un grupo de mujeres. Pueden estar todas emitiendo, ninguna escuchando y aun así todas enterarse… misterios de la naturaleza.
En .Net un clase que quiera escuchar los eventos de otra simplemente tiene que subscribirse a ellos:
class Subscriber
{
private Publisher _publiser = new Publisher();
public Subscriber()
{
_publiser.SampleEvent += new EventHandler(_publiser_SampleEvent);
}
void _publiser_SampleEvent(object sender, EventArgs e)
{
Console.Write(«Habemus evento»);
}
}
Como la hemos comentado lo eventos se implementan, simplificando el asunto, como delegados. Simplificando otro poco, podemos decir que los delegados son la versión orientada a objetos de los punteros a función. Básicamente la clase que declara el evento es declarando un tipo de puntero a función y un lugar en el que almacenar ese puntero. La clase que se subscribe proporciona la función que realmente se ejecutará, proporcionando el puntero a la función mediante la subscripción. Cuando la clase que lanza el evento hace la llamada al evento (SampleEvent en el ejemplo), simplificando, esta llamando a una función a través de un puntero. Es de lógica que si nadie se a subscrito dicho puntero será nulo, por lo tanto invalido, y en consecuencia recibiremos una fea excepción de tipo System.NullReferenceException. La moraleja: siempre debemos comprobar que alguien se ha subscrito a nuestro evento antes de lanzarlo. Más simple no puede ser:
class Publisher
{
public event EventHandler OnEvent;
public void FunctionThatProducesTheEvent()
{
//Comprobar que tenemos subcriptores
if (SampleEvent != null)
SampleEvent(this, EventArgs.Empty);
}
}
¿Que pasa si hay varios hilos?
El código anterior es más correcto. Pero aun tiene un error, además un bastante sutil, que solo se manifestaría en situaciones en las que haya varios hilos de ejecución. Es una típica condición de carrera. Estamos comprobando que tenemos alguien subscrito, en la siguiente instrucción de código estamos lanzando el evento. ¿Qué impide que la clase que estaba subscrita se haya desuscrito entre medias? Nada. La moraleja: debemos asegurar que si alguien estaba escuchando, siga escuchando cuando nosotros digamos algo.
La solución pasa por manejar nuestra propia copia local de la lista de subscriptores. La implementación de esta solución es:
public void FunctionThatProducesTheEvent()
{
//Copia local de las subcripciones al evento para
//evitar la condición de carrera entre la comprobación de
//que hay subscriptores y el lanzamiento del evento.
//Aunque que todos se desuscriban, nosotros tenemos la referencia.
EventHandler handler = SampleEvent;
//Comprobar que tenemos subcriptores
if (handler != null)
handler(this, EventArgs.Empty);
}
Aunque todos se desuscriban nosotros seguimos teniendo una referencia. Las consecuencias de esta solución (que es la implementación correcta si seguimos el patrón de eventos de .Net) son varias:
1) Una clase que se haya desuscrito de un evento, en un entorno multihilo, puede aun así recibirlo temporalmente. Si este comportamiento no es aceptable, tendremos que utilizar algún mecanismo de sincronización.
2) Si una clase está subscrito a un evento, no podrá ser recolectada por el recolector de basura, pues aun quedarán referencias a ella. Esta es una forma muy sutil de fugar objetos en .Net: olvidar desuscribir la clase de los eventos a los que está subscrita. Si esto no fuese así, no habría manera de garantizar que siempre hay alguien escuchando. La moraleja: si no desuscribes tus objetos de los eventos a los que estén suscritos de objetos con mayor tiempo de vida, el recolector de basura no puede llevárselos al otro mundo. Un patrón que funciona bastante bien es implementar IDisposable y desuscribirnos de todos los eventos a lo que la clase se a subscrito en el método Dispose.
¿Qué pasa si derivo de un clase que expone eventos?
Supongamos que derivamos una clase de la clase base que expone eventos. Todos sabemos que el motivo para derivar una clase de otra es modificar o extender su comportamiento. Lógicamente uno de los aspectos que no puede interesar modificar del comportamiento de una clase es como se comportan sus eventos, que ocurre cuando se lanzan, que información acompaña al evento, etc… Cuando se trata de una modificar el comportamiento de un método de una clase base, podemos sobreescribir dicha función, el problema es que no podemos sobreescribir un evento. La solución al problema es simple, lanzar todos los eventos desde una función protegida y virtual, en lugar de directamente, de tal manera que una clase derivada pueda redefinir el comportamiento del evento a su gusto o incluso anular su lanzamiento reescribiendo esta función. La moraleja: Debemos dar a las clases derivadas la oportunidad de modificar el comportamiento del lanzamiento del evento.
Además, con esa función damos a las clases derivadas la posibilidad de lanzar el evento si lo necesitan, simplemente invocando a la función que lanza el evento.
Con lo comentado anteriormente la implementación de nuestro evento quedaría como sigue:
class Publisher
{
public event EventHandler SampleEvent;
public void FunctionThatProducesTheEvent()
{
//Hacer algo aquí…
//Lanzar el evento
OnSampleEvent();
}
protected virtual void OnSampleEvent()
{
//Copia local de las subcripciones al evento para
//evitar la condición de carrera entre la comprobación de
//que hay subscriptores y el lanzamiento del evento.
//Aunque que todos se desuscriban, nosotros tenemos la referencia.
EventHandler handler = SampleEvent;
//Comprobar que tenemos subcriptores
if (SampleEvent != null)
SampleEvent(this, EventArgs.Empty);
}
}
De esta manera, cualquier clase que derivase de la nuestra podría modificar el comportamiento del evento a su gusto simplemente sobreescribiendo la función OnSampleEvent. La moraleja: si nuestro evento se llama XYZ la función virtual asociada debe llamarse OnXYX.
¿Qué pasa si además tengo algo que contar asociado al evento?
La firma de un evento declarado con EventHandler es
public delegate void EventHandler(object sender, EventArgs e);
Con esta firma, podemos detectar en la función que maneja el evento, cual es el objeto que origino el evento, en el parámetro sender e información asociada al evento, en el parámetro e, de tipo EventArgs. Si vemos la definición de la clase EventArgs, veremos que es de nula utilidad, ya que no tiene campos que contengan información. El propósito de esta clase es servir como clase base para nuestras propios argumentos de evento.
Supongamos que quisiésemos que cuando salte nuestro evento, quien lo reciba, reciba además cierta información. Por ejemplo nos podría interesar saber a que hora se produjo el evento. En esta situación lo primero es derivar una clase de la clase EventArgs que incluya la información que nos interesa:
class SampleEventArgs : EventArgs
{
readonly private DateTime _eventDateTime = DateTime.Now;
public DateTime EventDateTime
{
get { return _eventDateTime; }
}
}
Ahora lógicamente necesitamos cambiar la firma del delegado que manejará el evento. Para eso, desde .Net 2.0 tenemos una implementación genérica de la clase EventHandler que nos permite especificar el tipo de nuestro EventArgs. Basta por tanto cambiar la declaración del evento adecuadamente y corregir los errores de compilación. Con lo que la implementación de nuestra clase que expone eventos, quedaría definitivamente, como sigue:
class Publisher
{
public event EventHandler<SampleEventArgs> SampleEvent;
public void FunctionThatProducesTheEvent()
{
//Hacer algo aquí…
//Lanzar el evento
OnSampleEvent();
}
protected virtual void OnSampleEvent()
{
//Copia local de las subcripciones al evento para
//evitar la condición de carrera entre la comprobación de
//que hay subscriptores y el lanzamiento del evento.
//Aunque que todos se desuscriban, nosotros tenemos la referencia.
EventHandler<SampleEventArgs> handler = SampleEvent;
//Comprobar que tenemos subcriptores
if (SampleEvent != null)
SampleEvent(this, new SampleEventArgs());
}
}
La moraleja: Si necesitamos transmitir información junto con el evento debemos derivar una clase de EventArgs contenedora de la información y usar la implementación genérica de EventHandler.
Una clase subscrita podría extraer fácilmente la información adicional asociada al evento:
class Subscriber
{
private Publisher _publiser = new Publisher();
public Subscriber()
{
_publiser.SampleEvent += new EventHandler<SampleEventArgs>(_publiser_SampleEvent);
}
void _publiser_SampleEvent(object sender, SampleEventArgs e)
{
Console.Write(«Se lanzo el evento a las {0}», e.EventDateTime);
}
}
Corolario:
- No es extraño ver malas implementaciones de eventos.
- Siempre debemos comprobar que alguien se ha subscrito a nuestro evento antes de lanzarlo y esta comprobación debe ser ‘thread safe’.
- Una clase que se haya desuscrito de un evento, en un entorno multihilo, puede aun así recibirlo momentáneamente.
- Si nuestro evento se llama XYZ la función virtual asociada debe llamarse OnXYX.
- Si no desuscribes tus objetos de los eventos a los que estén suscritos, de objetos con mayor tiempo de vida, el recolector de basura no puede llevárselos al otro mundo.
- Debemos dar a las clases derivadas la oportunidad de modificar el comportamiento del lanzamiento de los eventos y de lanzarlos si lo necesitan.
- Si necesitamos transmitir información junto con el evento debemos derivar una clase de EventArgs contenedora de la información y usar la implementación genérica de EventHandler.
A que no pensabais que los eventos daban para tanto… ;).
He leído: The old new thing de Raymon Chen
 Una de las liturgias de mi familia y mía en particular es almorzar donde mi abuela Basi. La liturgia es muy simple, siempre que llego a mi pueblo, Belorado, a eso de media mañana, pongo el culo en una de las sillas de la cocina de mi abuela y degusto alguno de los manjares que prepara: unos huevos fritos o en salsa, una morcillita asada, un trocito de queso, chorizo, pancetita, asadurilla, bacalao… vamos el típico almuerzo castellano. Supongo que muchos ya estaréis salivando pero el tema no es la gastronomía. Ahora me explico, paciencia.
Una de las liturgias de mi familia y mía en particular es almorzar donde mi abuela Basi. La liturgia es muy simple, siempre que llego a mi pueblo, Belorado, a eso de media mañana, pongo el culo en una de las sillas de la cocina de mi abuela y degusto alguno de los manjares que prepara: unos huevos fritos o en salsa, una morcillita asada, un trocito de queso, chorizo, pancetita, asadurilla, bacalao… vamos el típico almuerzo castellano. Supongo que muchos ya estaréis salivando pero el tema no es la gastronomía. Ahora me explico, paciencia.
Mientras mi abuela concina y nosotros almorzamos, mi abuela no calla. No para de hablar ni un segundo. Generalmente sobre los pequeños asuntos familiares. Pero, en las grandes ocasiones en las que tengo el placer de ser el único comensal mi abuela me cuenta un motón de historias. Historias sobre mi pueblo, sobre su gente, sobre lo que ha pasado esa semana, sobre lo que paso en la guerra, sobre mi abuelo en Alemania, sobre la vida en el campo, sobre la infancia de mi padre y mi tío, sobre cuando vivían en San Nicolas … Historias inconexas, historias que a veces no tiene sentido para mi, , que divierten o que aburren soberamente (las menos de las ocasiones) y a veces autenticas perlas de sabiduría, historias que enseñan un motón casi siempre, sobre la vida, sobre mi pueblo, sobre mi familia. Muchas veces no conozco a la mayoría de los personajes: Si hombre, la hija de tal, que fue a vivir no se donde, que es prima de ese que es padre de aquella que es de tu cuadrilla que salía con el primo de tu amigo aquel de Galdakano, dice mi abuela y yo digo, si si ya se, no por que sepa sino por no liar más la madeja. Seguro que los que tenéis abuela sabéis lo que digo.
Pues bien, de eso va este libro de Raymon Chen, de historias sobre su pueblo, que da la casualidad que es Windows y su API, en el que lleva viviendo desde la versión 1.0. Las historias que recoge, son como las de mi abuela: entretenidas, aburridas, unas se entienden y otras no, todas tiene algo en común, aunque muchas veces sea difícil ver la línea argumental y en otras no exista.
Resumiendo, y aquí es donde vamos al grano del asunto, que Raymon Chen se ha puesto a contar todas sus historias de abuelo cebolleta. Se trata de un abuelo que lo sabe todo todo todo sobre Windows, su desarrollo, su historia y su interioridades.
El libro es de un valor inapreciable para entender la dificultad que entraña el tomar decisiones que pueden afectar a millones de usuarios y desarrolladores. Además explica un montón de interioridades de Windows y justifica por que muchas cosas son como son en nuestro sistema operativo favorito. Hay artículos sobre como se pintan las ventanas, como se manejan los mensajes (¡por fin lo he entendido! solo por esto ha merecido la pena leer el libro), chascarrillos sobre el equipo de desarrollo de Windows, interioridades de COM, trucos de depuración, etc… Hay artículos muy técnicos y artículos que podría entender cualquiera. Eso sí, si has peleado con el API de Windows desde C, te vas a sentir como en tu pueblo, sino el libro puede ser un poco árido, es la única pega que tiene. Hay que tener claro que el pueblo de Chen es Windows, su shell, el API, COM y C, nada de .Net. Vamos Windows de verdad de la buena.
Un libro bastante recomendable y que merece bastante la pena comprar. Si bien tiene pasajes difíciles de digerir (si si abuelo, ya se de que me hablas, sigue hacia adelante no te enrolles), es lo suficientemente ameno como para recomendar su lectura a cualquier desarrollador que disfrute desarrollando en Windows.
Por último, si queréis saber de antemano el tipo de historias que encontraréis, podéis revisar el blog de Raymon Chen, que lleva el mismo título que el libro.
Serías capaz de… ¡por supuesto! o Scrum también da respuestas
 Escribía un interesante post de Miguel Sierra, vecino de blog en Geeks.ms, sobre la implantación de CMMI que ha llevado a cabo su empresa. El post es interesante, y agradezco a Miguel que comparta su experiencias. Por mucho que para mi CMMI sea rara vez la elección metodológica adecuada, creo que es un marco metodológico que debemos conocer, aunque solo sea por la influencia que ha ejercido en el desarrollo de software en los últimos años. Además a mi ‘me va en el sueldo’, pues me toca apoyar técnicamente la implantación de TFS en organizaciones que han elegido CMMI como marco de trabajo.
Escribía un interesante post de Miguel Sierra, vecino de blog en Geeks.ms, sobre la implantación de CMMI que ha llevado a cabo su empresa. El post es interesante, y agradezco a Miguel que comparta su experiencias. Por mucho que para mi CMMI sea rara vez la elección metodológica adecuada, creo que es un marco metodológico que debemos conocer, aunque solo sea por la influencia que ha ejercido en el desarrollo de software en los últimos años. Además a mi ‘me va en el sueldo’, pues me toca apoyar técnicamente la implantación de TFS en organizaciones que han elegido CMMI como marco de trabajo.
Lo que motiva este post es el ‘reto’ que lanzaba Miguel preguntando si seríamos capaces de responder a una serie de preguntas relacionadas con el ciclo de vida de nuestros proyectos. Yo que llevo ya un tiempo viviendo en Bilbao, y se me ha pegado un poco la vena Vasca, no he podido remediar el recoger el guante y decir ‘que te apuestas a que sí»’. Es un poco como el chiste de meter cien vascos en un seiscientos… diciéndoles que no caben. Es un poco como las luchas fictícias entre superheroes tipo Lobezno contra Spiderman.
Aquí van las preguntas de Miguel y la respuesta que Scrum en particular y las metodologías ágiles en general darían, de la mano de TFS:
¿Serías capaz de …?
Identificar las tareas y pruebas funcionales relacionadas con un requisito concreto
Tras el Sprint Planning Meeting y antes de que cualquier trabajo de desarrollo se realice, el equipo de desarrollo desglosa las historias de usuario (requisitos) en tareas. Toda historia de usuario lleva explícitamente en su definición las condiciones de aceptación (versión ágil de las pruebas de aceptación). Luego la respuesta es si.
Identificar las partes de código fuente a las que afecta un cambio de requisito
Por supuesto. Todo cambio tendrá su historia de usuario asociada. En Scrum no se hace ningún desarrollo sin que pase por el backlog y por lo tanto sin que ese trabajo este definido. Apoyándonos en TFS podemos enlazar los cambios en el código con tareas o requisitos en el momento de hacer checkin… ¿a alguien se le ocurre algo más productivo, menos intrusivo para el desarrollador?. Además para que nadie se olvido lo podemos ‘imponer’ mediante políticas de código
Decir cuando se realizó una tarea en concreto y la cantidad de esfuerzo que supuso
Lo lleva el TFS. Sin salir del su entorno natural, el IDE de desarrollo (sea VS o Eclipse) el desarrollador puede actualizar el estado de sus tareas o bug en el mismo instante en el que comienza su trabajo o lo termina. Y sin cambio de contexto alguno. Evidentemente, aunque en Scrum no nos importa demasiado, es posible responder con facilidad el tiempo que te llevo implementar una determinada tarea, bug o requisito. Otra vez, gracias a TFS con burocracia cero para el desarrollador.
Realizar una estimación precisa de una tarea que ya realizaste en algún proyecto anterior
El Product Backlog se debe estimar, las tareas que forman parte de un Sprint se estiman. Scrum no dice nada sobre como debes estimar, pero la comparación con experiencias anteriores es la técnica que explicita o implícitamente todos usamos. Los equipos ágiles suelen preferir métodos más ligeros y más llevaderos de estimación, basados en mejorar el conocimiento, la responsabilidad compartida y el consenso.
Listar las tareas que tienes pendientes en un determinado módulo de tu proyecto
En Scrum el concepto de ‘hecho’ y ‘no hecho’ es clave para gestionar el avance del proyecto. Sabemos en todo momento que elementos del Product Backlog han sido completado y cuales no. Exactamente el mismo aplica a nivel de Sprint Backlog. No solo eso, además visualizamos este estado mediante los gráficos de burndown.
Decir el tiempo restante para terminar un módulo de tu proyecto
En Scrum evitamos construir por módulos. Un módulo por si mismo no suele se capaz de hacer algo de valor para le cliente. No se trata de completar módulos, sino de liberar en cada momento lo que más valor tiene para el cliente. Tratamos de construir el software en ‘tiras verticales’ que implementan toda la funcionalidad de una determinada historia de usuario. Logramos así un continuo flujo de valor. Mirando el Burdown Chart es muy simple decir cuanto queda para completar el proyecto. Evidentemente podemos filtrar este Burdown Chart para las historias de un area (módulo) concreto.
Sacar un listado de las incidencias de un proyecto y la desviación en esfuerzo, tiempo y coste
Una vez más la respuesta es el Burdown Chart que visualiza cualquier desviación en tiempo real. El Burdown Chart refleja las desviaciones en tiempo, pero todos sabemos que tiempo y coste son magnitudes convertibles en gestión de proyectos. Por ejemplo en este Burdown Chart se aprecia claramente una desviación de 60 puntos en un proyecto de 20 unidades de tiempo.
{kind=link}
Sacar un listado de las peticiones de cambio de un cliente
El Product Backlog recoge continuamente todas las peticiones del cliente. Todo lo solicitado por el cliente es gestionado por el Producto Owner utilzando el Product Backlog que permanece vivo a lo largo del proyecto. TFS nos proporciona informes sobre la tasa de cambio que ocurre en el Product Backlog.
Certificar que los requisitos del proyecto han sido entendidos y comprometidos por el equipo de trabajo
Evidentemente. Durante el Sprint Planning Meeting, los desarrolladores entienden los requisitos, hacen preguntas y mejoran su conocimiento. La primera parte del Sprint Planning Meeting se dedica a esto. El Sprint Planning Meeting termina con el compromiso de los desarrolladores de hacer todo lo humanamente posible para lograr implementar los requisitos comprometidos para el Sprint durante el mismo.
Identificar, si una prueba falla, que requisitos se ven afectados
TFS permite asociar pruebas de aceptación y sus resultados con cualquier tipo de work item. Si haces esto, es simple responder esta pregunta. Yo he trabajado con equipos que hacen esto y equipos que no lo hacen. Si hay un tester en el equipo, es muy recomendable.
Entregar una versión del producto, mas o menos estable, al cliente, ahora mismo
Lógicamente. Esto es un problema clásico de SCM. En cierto modo no está ligado a la metodología, sino que es una práctica de ingeniería del software más que recomendable. En Scrum todo Sprint debe terminar con un ‘incremento de funcionalidad potencialmente entregable’. Las políticas de SCM de un proyecto que use Scrum deben adecuarse a este objetivo. Una vez más, aperece aquí, el objetivo de Scrum y de las metodologías ágiles en general de ‘crear un flujo continuo del valor para le cliente’.
Decir el porcentaje de construcción del producto o proyecto y certificar el coste actual, «on the fly», del producto
Una vez más me remito al Product Backlog y a su primo visual, el Burndown Chart.
Decir los riesgos activos que hay en tu proyecto
Claro que gestionamos el riesgo, lo llamamos impedimentos y lo hacemos de una manera un poco diferente. No ponemos tanto énfasis pero todo proyecto Scrum tiene un backlog de impedimentos, que es ‘equivalente’ a la lista de riesgos. Otras metodologías ágiles, sobre todo MSF Agile, hace un gestión del riesgo mucho más explicita.
Enumerar las personas dedicadas al proyecto y el porcentaje de ocupación
Ufff… porcentaje de ocupación… es que alguien en alguna empresa no está ocupado al 100% :). Bromas a parte. En Scrum no nos importa tanto la ocupación del individuo como la del equipo. El concepto de equipo es vital. Pero lógicamente, en todo momento tratamos de ajustar la carga del equipo a su capacidad.
Decirme cuando queda liberado un recurso en concreto
Ummm… si por recursos te refieres a máquinas, servidores, fuentes de agua, y máquinas de café y refrescos… simplemente tratamos de tener los suficiente ;).
Decir las medidas correctivas que has tomado cuando has tenido desviaciones
Todo Sprint termina con una Sprint Retrospective. Se trata de saber que ha ido bien, que ha ido mal y plantear las acciones correctoras. Todas las conclusiones quedan reflejadas en TFS y las acciones correctores necesarias que impliquen un esfuerzo explicito se meten en Product Backlog para su gestión dentro de el marco de un Sprint.
Contar lo que se habló en la ante última reunión de seguimiento con el cliente
En Scrum las reuniones de seguimiento son obligatorias. Ocurren puntualmente con periodicidad predeterminada. En esta reuniones de seguimiento, Sprint Reviews en la jerga de Scrum, se muestra software que funciona mediante ‘demos’. Ocurre, sin excepción, al final de cada Sprint. El cliente puede ver el progreso, no imaginárselo en base a diagramas de Gantt o sesudos informes de seguimiento. Además puede y debe dar feedback sobre lo visto durante el Sprint Review.
Enumerar las tareas y esfuerzo que te va a suponer la puesta en producción
Los equipos ágiles tratamos de hacer de la puesta en producción una hábito. La idea es minimizar el esfuerzo de puesta en producción hasta limites tales que sea inapreciable. Para ello nos apoyamos en técnicas como la integración continua o frecuente y el testeo automatizado. Dicho esto, cualquier tarea que se realice, sea del tipo que sea, se debe meter en el marco de un Sprint.
Como podéis ver Scrum responde las mismas cuestiones que CMMI de una manera diferente, pero las responde. No podía se de otra manera, pues muchas de las cuestiones planteadas por Miguel, son cuestiones universales en la gestión de proyectos de software.
Esto me lleva a pensar… es posible usar Scrum + TFS, para cubrir CMMI Nivel 2… la respuesta es que sí. Precisamente de esto habló mi compañero Jose Luis Soria hace poco en un evento sobre CMMI, a ver si se anima y publica las ppts en Slideshare.
¡Un saludo!
Exprimiendo Scrum: ¿Cuál es tu definición de equipo?
 La problemática de la gestión de proyectos en las organizaciones que desarrollan software se deriva, simplificando el asunto, de dos situaciones: gestionar proyectos muy grandes o gestionar muchos proyectos pequeños. Todos estaremos de acuerdo en que cualquiera de estas dos situaciones es más compleja que la situación, más equilibrada, en la que tenemos un número limitado de proyectos con unas dimensiones limitadas.
La problemática de la gestión de proyectos en las organizaciones que desarrollan software se deriva, simplificando el asunto, de dos situaciones: gestionar proyectos muy grandes o gestionar muchos proyectos pequeños. Todos estaremos de acuerdo en que cualquiera de estas dos situaciones es más compleja que la situación, más equilibrada, en la que tenemos un número limitado de proyectos con unas dimensiones limitadas.
De estas tres posibilidades, sin duda la más compleja es muchos proyectos pequeños. Los grandes problemas siempre se pueden dividir en problemas de tamaño medio y reducir así la complejidad, llevarlos a la categoría de ‘un numero pequeños de proyectos medianos’.
El por qué la situación más compleja se da cuando tenemos muchos pequeños proyectos es simple: tendemos a tener más cambios de contexto. Los cambios de contexto se dan al ‘pasar’ de un proyecto a otro y son tiempos perdidos. Si a un número grande de proyectos pequeños, unimos que no hay concepto de equipo, los cambios de contexto son continuos y la caída de productividad acusada. Cuando un proyecto está en manos de una persona y no de un equipo, esta persona inevitablemente es un cuello de botella. No voy ha hablar hoy de los cambios de contexto, en otra ocasión volveré sobre el tema, que ya he tratado, someramente, en alguna otra ocasión.
Cuando tratamos de implantar Scrum en una organización este problema de la gestión de proyectos también nos afecta de manera decisiva. Como hemos comentado se trata de un problema de cambios del contexto y el antídoto de Scrum para los cambios de contexto es el concepto de equipo autoorganizado y autogestionado. La idea clave es que un equipo autoorganizado y autogestionado puede elegir en que momentos introducir los cambios de contexto, y por simple sentido común elegirá los momentos idóneos. Siguiendo con esta argumentación se hace patente que es precisamente en entornos que presentan muchos pequeños proyectos en los que más dificultoso es implantar Scrum y en los que más atención se debe prestar a un tema clave: definir que es un equipo en tu organización.
En empresas con ‘muchos pequeños proyectos’, como la gran mayoría de las pequeñas y medianas consultoras, la gran dificultad pasa por encontrar que es un equipo para esa organización, en primer lugar, y en segundo lugar definir cuantos product backlogs se van manejar.
Para hacer esto, no hay una receta universal. Depende mucho de la cultura y organización actual de la empresa. Pero es la clave. Pensad que ahora solo existen individuos y tenemos que pasar de esa situación a una en la que el trabajo de reparta entre equipos, no entre individuos. Esa es la gran dificultad.
El principal problema que tenemos en la situación actual es el tiempo que se os va en cambios de contexto, insisto. Probablemente estemos en la típica situación de prioridades difusas, de atender a los fuegos, al cliente que más grita… el antídoto para eso es Scrum y su modelo de equipos. Por ahí empezaría yo, por ahí empiezo yo toda implantación de Scrum en este tipo de situaciones, definir los equipos.
Esa definición de equipos se puede hacer atendiendo a numerosos factores y es particular de cada caso, muchas veces no resulta evidente, pero es vital hacerlo bien. Podemos particionar los equipos por numerosos criterios: tecnología, cliente al que se dedican, proyecto (la más evidente)… Lo vital, en mi opinión, es que esas particiones sean verdaderas particiones, que no existan individuos que están en n equipos a la vez.
Yo suelo analizar las particiones que me salen según las leyes de las particiones de Roger S. Sessions, y da buen resultado:
1ª Ley: Las particiones deben ser verdaderas particiones.
2ª Ley: Las particiones deben ser adecuadas al problema.
3ª Ley: El número de subconjuntos en una partición debe ser adecuado.
4ª Ley: El tamaño de las particiones debe ser aproximadamente igual.
5ª Ley: Las interacciones entre subconjuntos deben ser mínimas y bien definidas.
Si lográis hacer bien eso, habréis dado un gran paso. Luego, a la hora de determinar el número de backlogs, el enfoque más simple es un equipo, un backlog, un product owner. Aunque no siempre es posible, es el enfoque más simple y el que siempre se debe perseguir.
Hay una manera muy simple de saber si hemos hecho esto bien: elegimos un desarrollador al azar y le preguntamos:
¿Tu a qué equipo perteneces?
¿Dónde está vuestro product backlog?
¿Quién son vuestro Producto Owner y Scrum Master?
¿Cuáles son los objetivos de tu equipo para este sprint?
Si recibimos respuestas ambiguas, es que no tenemos un modelo de equipos. Sin un modelo claro de equipos no es posible una correcta implantación de Scrum.
El enfoque más simplista de Scrum persigue un proyecto, un backlog, un equipo. Pero esto no siempre es posible en consultoras donde lo que hay son muchos proyectos pequeños que gestionar como un todo en lugar de algunos proyectos grandes que respondan al modelo simple de Scrum.
Este post, se inspira en una interesante conversación mantenida sobre este tema en la lista de Agile Spain, quizás queráis leer los pensamientos allí expuestos.
¡Espero vuestros comentarios!