

Al desarrollar nuestras aplicaciones (independientemente si llevamos a cabo una aplicación web, una aplicación nativa para dispositivos móviles, una aplicación de escritorio…) si necesitamos consumir datos desde un servidor utilizaremos llamadas REST. Generalmente tendremos un conjunto de endpoints en nuestro servidor que llamamos desde la aplicación cliente para obtener dichos datos.
El problema viene cuando nuestra aplicación es intensiva en el uso de datos desde servidor. Generalmente o bien realizamos muchas llamadas simultáneas para conseguir obtener los datos que necesitemos o comenzamos a crear endpoints específicos para cada momento. Otro problema aparece cuando coexisten diferentes aplicaciones que utilizan el mismo servidor como proveedor de datos. Cuando queramos introducir cambios, hemos de empezar a versionar el API para asegurarnos que todas las aplicaciones continúen funcionando.
GraphQL trata de establecer una nueva forma de comunicación entre cliente y servidor en la cual el cliente puede especificar exactamente los datos que necesita en cada momento. No vamos a entrar en conceptos teóricos (todo está muy bien explicado en su página oficial), sino que pasamos directamente al grano.
1.- Introducción
La aplicación que vamos a montar es relativamente sencilla. Supongamos que tenemos un blog de noticias, donde cada noticia tiene un autor y puede tener asociado un número indeterminado de comentarios. A su vez cada comentario puede tener «likes» asociado a un usuario. El esquema de datos quedaría tal que así:

Tecnológicamente, montaremos un servidor Node.js, con Express, utilizando una base de datos MongoDB, atacándola con Mongoose. Sobre este stack situaremos GraphQL.
Trabajaremos usando Atom, sobre Windows 10.
2.- Configuración previa
2.1.- Base de datos
- El primer paso consiste en instalar MongoDB en nuestro sistema. Desde la siguiente dirección: https://www.mongodb.com/download-center#community podemos descargar la versión correspondiente a nuestro sistema operativo.
- Una vez instalada, hemos de definir un directorio que MongoDB utiliza para almacenar información de las base de datos que tengamos. En nuestro caso crearemos un directorio llamado mongoDB en la raíz de la unidad d:. A la hora de ejecutar mongo, hemos de indicarle la ruta al directorio que queramos, ya que por defecto buscará el directorio /data/db desde su carpeta de instalación. Lo más sencillo es situarse en el directorio de instalación que hayamos elegido (por defecto C:\Program Files\MongoDB\Server\3.2\bin\, en la versión que hemos descargado) ejecutar lo siguiente: mongod –dbpath «d:\mongodb»
- El siguiente paso es crear una nueva base de datos y un usuario genérico para poder conectarnos a la misma. Para ello, nos situamos (en otro terminal) en el mismo directorio de instalación que hemos citado anteriormente, y abrimos el shell de mongoDB utilizando el comando mongo:

- Creamos una nueva base de datos utilizando el comando use <nombreBBDD>. En nuestro caso: use graphqltest
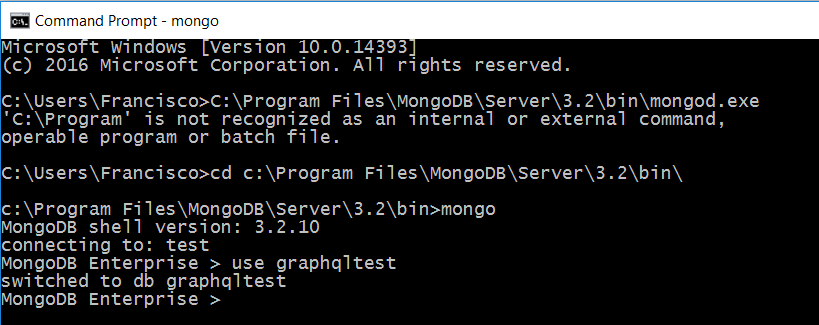
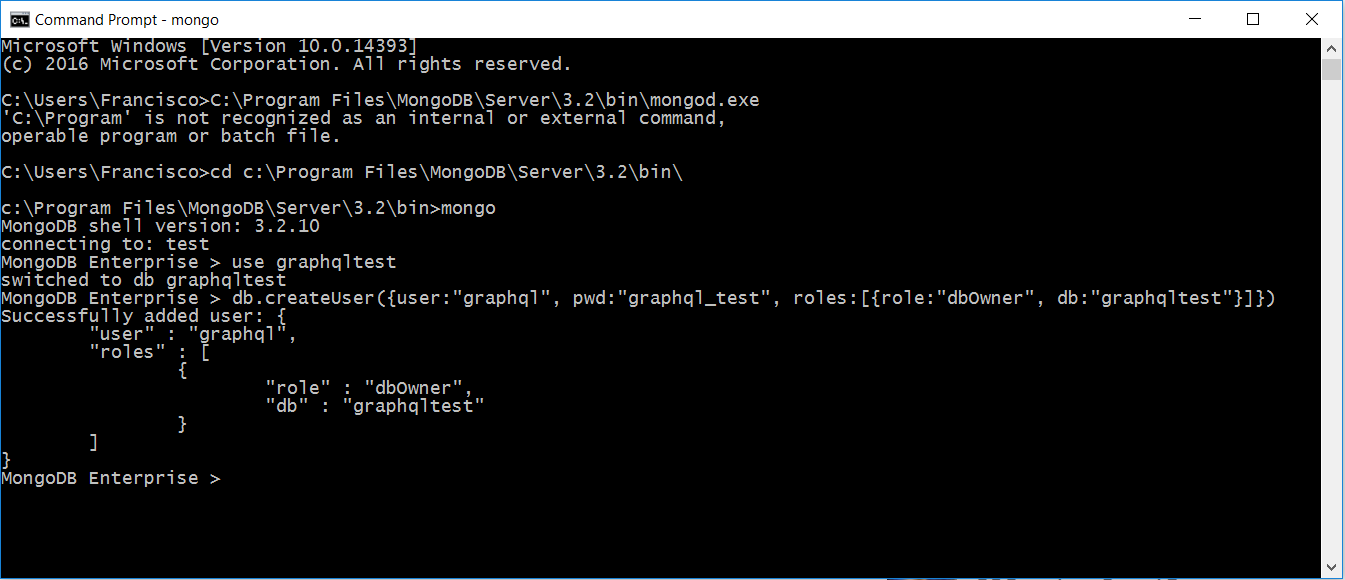
- Creamos un usuario para poder conectarnos a nuestra base de datos. Para ello, utilizamos el comando siguiente: db.createUser({user: «USERNAME», pwd: «PASSWORD», roles: [{role: «dbOwner», db: «DATABASE»}]}). Lo ejecutamos con los parámetros que deseemos (tanto para el nombre de usuario, el password y el rol que queramos asignarle) y deberíamos recibir una respuesta correcta desde el terminal:
- Vamos a utilizar una herramienta de gestión de base de datos en mongoDB, denominada robomongo (https://robomongo.org/), que pasaremos a configurar:
- Una vez instalada, creamos una nueva conexión y configuramos los parámetros con los siguientes valores:

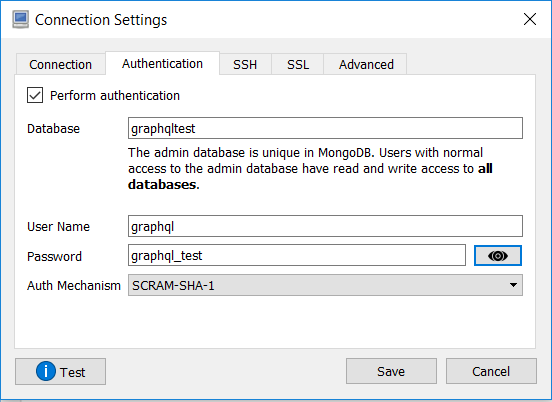
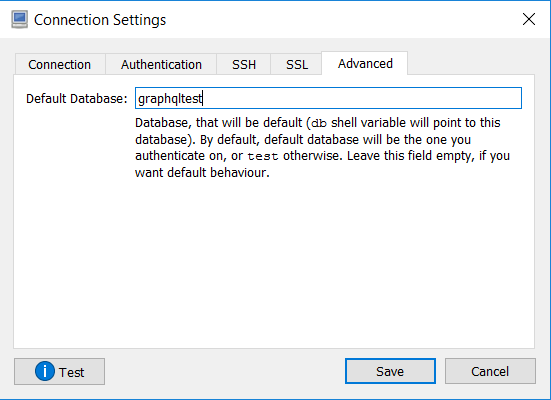
- Guardamos la configuración y pulsamos en conectar. Si todo se ha configurado correctamente deberemos ver algo parecido a lo siguiente:

En resumen, tenemos un servidor de base de datos ejecutándose en http://localhost:27017 (creado en la instalación de mongoDB por defecto) y nos estamos conectando a la base de datos que hemos creado (graphqltest) con los credenciales del usuario definido anteriormente.
2.2.- Configurando el entorno de trabajo
2.2.1.- Requisitos previos
- Necesitamos tener instalado node.js en nuestro sistema. Lo podemos descargar desde https://nodejs.org/es/download/ (o, si usamos chocolatey en Windows, choco install nodejs).
- Una vez instalado node.js, instalaremos yarn de forma global utilizando el siguiente comando: npm install -g yarn (o bien choco install yarn, si usamos chocolatey).
- Nosotros usaremos atom (https://atom.io/), con el skin nuclide (https://nuclide.io/) , que aunque no esté totalmente soportando en Windows, sí nos aporta algunas características interesantes para debugging y desarrollo javascript.
2.2.2.- Creando el proyecto
- Creamos una carpeta para trabajar (en nuestro caso d:\repos\graphqltest) e inicializamos un repositorio git, utilizando el comando git init. Posteriormente, creamos el proyecto en sí, utilizando el comando yarn init (con los valores por defecto). Como resultado, nos habrá creado el fichero package.json en nuestra carpeta de trabajo:
- Antes de empezar a trabajar, hemos de realizar un par de configuraciones más. La primera es el linter. Definiremos unas reglas mínimas de código que queremos cumplir, y el linter nos avisará en el momento en que no cumplamos alguna de ellas. Lo primero es añadir las dependencias necesarias:
yarn add –dev eslint-plugin-node eslint-plugin-smells
- Instaladas las dependencias, hemos de configurar las reglas que queremos que aplique nuestro linter. Abrimos atom y creamos el archivo .eslintrc en la carpeta base de nuestro proyecto. (Es importante instalar también el plugin eslint para atom para que nos vaya avisando en vivo de los errores que vayamos cometiendo):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
{ "plugins": ["node", "smells"], "extends": ["eslint:recommended", "plugin:node/recommended"], "env": { "node": true, "es6": true, "mongo": true }, "parserOptions": { "sourceType": "module" }, "rules": { "node/exports-style": ["error", "module.exports"], "node/no-unpublished-bin": "error", "node/process-exit-as-throw": "error", "smells/no-switch": 1, "smells/no-complex-switch-case": 1, "smells/no-setinterval": 1, "smells/no-this-assign": 1, "no-console": "off", "node/no-unsupported-features": "off" } } |
- Por último, vamos a instalar babel, ya que queremos utilizar la sintaxis de es2015 en nuestro proyecto (aunque las nuevas versiones de node ya soportan muchas características de es2015). Para ello, como siempre, instalamos las dependencias necesarias:
yarn add babel-cli babel-preset-node5 –dev
- Una vez instaladas, creamos el fichero .babelrc, indicando los presets que queremos utilizar:
|
1 2 3 4 5 |
{ "presets": [ "node5" ] } |
3.- Trabajando en el servidor
3.1.- Creando los modelos de dominio
Creamos una nueva carpeta en nuestro proyecto (llamada domain) donde detallaremos nuestros modelos. Utilizaremos mongoose para definir estos modelos. Al no ser el propósito del artículo, sólo presentaremos los esquemas que utilizaremos, sin detallarlos en profundidad. Lo primero, como siempre, es incluir la dependencia de mongoose:
yarn add mongoose
Crearemos tres archivos diferentes, cada uno correspondiente al modelo que estamos creando (post.js, user.js y comment.js):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
import mongoose from 'mongoose'; const UserSchema = new mongoose.Schema({ firstName:{ type: String }, lastName:{ type: String }, email: { type: String }, contacts: [{ type: mongoose.Schema.Types.ObjectId, ref: 'User' }], posts:[{ type: mongoose.Schema.Types.ObjectId, ref: 'Post' }], comments:[{ type: mongoose.Schema.Types.ObjectId, ref:'Comment' }], createdAt: { type: Date, default: Date.now }, modifiedAt: { type: Date, default: Date.now } }); export const UserModel = mongoose.model('User', UserSchema); |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
import mongoose from 'mongoose'; const PostSchema = new mongoose.Schema({ title: { type: String }, content:{ type: String }, category: { type: String }, comments:[{ type: mongoose.Schema.Types.ObjectId, ref: 'Comment' }], author:{ type: mongoose.Schema.Types.ObjectId, ref: 'User' }, createdAt: { type: Date, default: Date.now }, modifiedAt: { type: Date, default: Date.now } }); export const PostModel = mongoose.model('Post', PostSchema); |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
import mongoose from 'mongoose'; const CommentSchema = new mongoose.Schema({ comment:{ type: String }, likes: [{ type: mongoose.Schema.Types.ObjectId, ref: 'User' }], post:{ type: mongoose.Schema.Types.ObjectId, ref: 'Post' }, author:{ type: mongoose.Schema.Types.ObjectId, ref:'Comment' }, createdAt: { type: Date, default: Date.now }, modifiedAt: { type: Date, default: Date.now } }); export const CommentModel = mongoose.model('Comment', CommentSchema); |
El código previo no tiene nada especial:
- Importamos mongoose.
- Declaramos las propiedades que va a tener cada esquema (incluyendo las referencias a otros modelos, tanto las relaciones one-to-many como las many-to-many).
- Exportamos el modelo que hemos creado para poder utilizarlo posteriormente.
También crearemos un archivo index.js, dentro de la carpeta domain, que nos servirá para exportar los modelos para que sean usados desde otras partes de la aplicación. De esta forma, es más sencillo importarlos desde fuera, porque no tenemos que conocer la estructura interna de la carpeta domain y en este fichero se detallarán todos los modelos que podemos utilizar:
|
1 2 3 4 5 |
import { CommentModel } from './models/comment'; import { PostModel } from './models/post'; import { UserModel } from './models/user'; export { CommentModel, PostModel, UserModel } |
Para finalizar con esta parte, vamos a popular nuestra base de datos con datos de prueba. Para ello, haremos uso de dos librerías: mongoose-seeder (https://github.com/SamVerschueren/mongoose-seeder), que introduce datos en la base de datos a partir de un fichero .json y faker (https://github.com/marak/Faker.js/) , que permite crear valores aleatorios de diferentes tipos y tamaños. Añadimos, por lo tanto, estas dependencias:
yarn add mongoose-seeder faker
Creamos una carpeta, dentro de domain, que llamaremos seed, donde añadimos dos archivos: seed.data.json, donde detallaremos nuestros datos de prueba, y seed.js, donde ejecutaremos el servidor que se encarga de añadir estos datos a la base de datos. Detallamos sólo el segundo de ellos:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
import seeder from 'mongoose-seeder'; import mongoose from 'mongoose'; // Mandatory import(define moongose schemas) import {} from '../models'; import { database } from '../../config' import seedData from './seed.data.json'; const { name, username, password, host, port } = database; mongoose.Promise = global.Promise; mongoose.connect(`mongodb://${username}:${password}@${host}:${port}/${name}`); function seedError(error) { mongoose.connection.close(); console.log(`Seed finished with errors: ${error}`); process.exit(1); //eslint-disable-line } seeder.seed(seedData, {dropDatabase: false}).then((dbData) => { const { users, posts, comments} = dbData; const { usera, userb, userc } = users; const { posta, postb, postc, postd } = posts; const { commenta, commentb, commentc, commentd, commente, commentf, commentg } = comments; usera.posts.push(...[posta, postb]); usera.comments.push(...[commenta, commentb, commentc, commentd]); userb.posts.push(postc); userb.comments.push(...[commente, commentf]); userc.posts.push(postd); userc.comments.push(commentg); posta.author = usera; posta.comments.push(...[commenta, commentb, commentf]); postb.author = usera; postb.comments.push(...[commentc, commentd, commente]); postc.author = userb; postc.comments.push(commentg); postd.author = userc; Promise.all([ Object.keys(posts).map((post) => posts[post].save()), Object.keys(users).map((user) => users[user].save()) ]).then(() => { mongoose.connection.close(); console.log('Seed finished OK!'); process.exit(0); //eslint-disable-line }).catch((error) => seedError(error)); }).catch((error) => seedError(error)); |
Algunas consideraciones interesantes:
- La librería que hemos utilizado para hacer el seed, no permite (en la versión actual), detallar dependencias hacia objetos que no hayan sido declarados previamente; por lo tanto, tras realizar el seed a partir del archivo .json, hemos de actualizar las dependencias que faltaban.
- Es necesario importar los modelos que hemos realizado anteriormente antes de establecer la conexión a la base de datos.
- Los parámetros de conexión se obtienen desde un archivo config.js, situado en la raíz del proyecto, que queda tal que así:
|
1 2 3 4 5 6 7 |
export const database = { name : 'graphqltest', username: 'graphql', password: 'graphql_test', host: 'localhost', port: '27017' }; |
- La idea de trabajo es la siguiente:
- Tras crear la conexión con la base de datos, llamamos al método seed que nos provee la librería mongoose-seeder, pasándole como parámetro el json con los valores de prueba. Esta llamada es una promesa, que al resolverse nos pasa como parámetro de nuestro callback dbData que contiene los datos que se han añadido a base de datos.
- A partir de estos datos actualizamos las referencias necesarias: incluimos los comentarios y los posts a los usuarios y añadimos el autor y los comentarios a los posts.
- Ahora necesitamos actualizar cada uno de los documentos en base de datos. Cada llamada a save() es una promesa que incluimos en nuestro array de promesas (Promise.all([promises])). Una vez se resuelvan todas, cerramos la conexión, mostramos el mensaje de éxito o error según corresponda y terminamos el proceso.
Para ejecutar nuestro seed, añadimos en el fichero package.json lo siguiente:
|
1 2 3 |
"scripts": { "seed": "babel-node ./domain/seed/seed.js" } |
Una vez añadido, nos vamos a nuestro terminal y ejecutamos dicho script:
yarn seed
Por último, si nos vamos a robomongo y refrescamos nuestra base de datos, nos aparecerá que tenemos tres colecciones. Pulsando con el botón derecho en una de ellas y eligiendo View Documents, podemos ver los datos de prueba que hemos insertado:

3.2.- Generando los esquemas GraphQL
Todos los esquemas los vamos a situar dentro de una carpeta llamada graphql/schemas. Lo primero es añadir la dependencia con GraphQL:
yarn add graphql
Presentaremos el modelo que necesitaremos para usuarios e iremos detallando todos los pasos que se han ido siguiendo para generarlo:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 |
import { GraphQLObjectType, GraphQLString, GraphQLList } from 'graphql'; import { Post } from './post'; import { Comment } from './comment'; import { UserModel, PostModel, CommentModel } from '../../domain' const User = new GraphQLObjectType({ name: 'User', description: 'General user of the app', fields: () => ({ firstName: { type: GraphQLString }, lastName: { type: GraphQLString }, email: { type: GraphQLString }, id: { type: GraphQLString }, contacts: { type: new GraphQLList(User), resolve: user => UserModel.find({ '_id': { $in: user.contacts } }, (_ , values) => values) }, posts: { type: new GraphQLList(Post), resolve: user => PostModel.find({ '_id': { $in: user.posts } },(_, values) => values) }, comments: { type: new GraphQLList(Comment), resolve: user => CommentModel.find({ '_id': { $in: user.comments } }, (_, values) => values) } }) }); const UsersSchema = { type: new GraphQLList(User), args: { firstName: { type: GraphQLString }, lastName:{ type: GraphQLString } }, resolve: (root, args) => UserModel.find(args, (_, values) => values) } const UserSchema = { type: User, args: { id: { type: GraphQLString }, email:{ type: GraphQLString } }, resolve: (root, args) => UserModel.findOne(args, (_, value) => value) } export { User, UserSchema, UsersSchema }; |
Los aspectos más relevantes son:
- Importamos los modelos que hemos generado anteriormente, ya que los necesitaremos para detallar las consultas que se han de realizar a base de datos para recuperar los datos que necesitemos.
- Declaramos un objeto del tipo GraphQLObjectType, donde hemos de detallar:
- El nombre del objeto. En este caso User.
- Una descripción (campo opcional).
- Una función que devuelve un objeto donde se detallan todos los campos que tiene nuestro objeto (fields). Cada uno de los elementos que conforman el objeto respuesta de la función fields puede tener:
- type: Es obligatorio e indica el tipo del campo. Utilizaremos los tipos que importamos desde la librería graphql; como, por ejemplo: GraphQLString, GraphQLList….
- description: También opcional, donde podemos indicar información sobre el campo concreto.
- resolve: Esta función devuelve una promesa y en ella tenemos que indicar cómo recuperar el campo concreto a partir de un objeto del tipo en cuestión. Esta función es opcional y no hace falta incluirla en aquellos campos que sean extraíbles directamente desde el objeto que tratamos. Veamos algunos ejemplos:
- firstName: No necesita función resolve, ya que el campo firstName se recupera directamente desde nuestro objeto de dominio (si el nombre fuera diferente, sí sería necesario indicar la función resolve).
- posts: En este caso, sí debemos de indicar una función resolve que nos indique cómo obtener los posts relacionados con el usuario. Recordemos que en nuestro modelo de dominio, sólo guardamos los ids de los posts que corresponden al usuario; por lo tanto, la función tiene que, a partir de esos ids, obtener el objeto post completo. Para ello, utilizamos la función find que nos proporciona mongoose.
- Una vez definido nuestro objeto User, hemos de crear un objeto que represente el esquema de usuarios. En este caso, hemos definido dos esquemas: uno de ellos para obtener una lista de usuarios y otro para obtener un sólo usuario.
- Cada objeto necesita tener los siguientes campos:
- type: Indica el tipo de objeto que que define este esquema. En el caso de UsersSchema, es del tipo GraphQLList(User).
- args: argumentos que podemos tener a la hora de recuperar los objetos de este tipo. En el caso de UsersSchama hemos indicado firstName y lastName (por el hecho de ilustrar que con esos parámetros podemos encontrar más de un usuario) y en el caso de UserSchema hemos indicado como argumentos el id y el email. En cada uno de estos argumentos hemos de indicar su tipo.
- Una función resolve. Como hemos visto, esta función se utiliza para indicar cómo obtener los datos requeridos a partir de los argumentos. Esta función toma dos parámetros: root, que conforma el contexto de operación y args, donde se incluirán, si existen, los argumentos que hemos indicado en la sección previa. En este caso, igualmente, utilizamos las funciones find o findOne de mongoose para obtener los valores requeridos.
- Cada objeto necesita tener los siguientes campos:
- Por último, hemos de exportar tanto el objeto básico User, que utilizaremos en los otros modelos para indicar el tipo de objetos vinculados que sean de tipo usuario, como los dos esquemas (UserSchema y UsersSchema) que necesitaremos incluir en la declaración de nuestro esquema global, como veremos posteriormente.
- Es importante hacer hincapié en la nomenclatura. Nosotros estamos usando la coletilla Model para identificar los tipos de objeto de dominio, mientras que el nombre del objeto sin coletilla sirve para señalar los tipos definidos para GraphQL.
La definición de los esquemas para Posts y Comentarios se hacen de igual forma a como hemos hecho el de Usuarios.
Crearemos ahora un nuevo fichero llamado schema.js en la raíz de la carpeta GraphQL, donde vamos a definir nuestro esquema general de consulta:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
import { GraphQLSchema, GraphQLObjectType } from 'graphql'; import { UserSchema, UsersSchema } from './schemas/user'; import { PostSchema, PostsSchema } from './schemas/post'; import { CommentSchema, CommentsSchema } from './schemas/comment'; const QueryType = new GraphQLObjectType({ name: 'Query', description: 'This is the root query type', fields: () => ({ user: UserSchema, users: UsersSchema, post: PostSchema, posts: PostsSchema, comment: CommentSchema, comments: CommentsSchema }) }); export const Schema = new GraphQLSchema({ query: QueryType }); |
Seguimos la estructura básica que hemos detallado previamente:
- Definimos un esquema creando un nuevo GraphQLSchema, que es un objeto que, como mínimo, tiene un campo query donde se detallan los tipos de querys que se pueden realizar.
- Este campo query es un GraphQLObjectType donde, aparte del nombre y de la descripción, tenemos que definir una función fields, que devolverá un objeto con todos los esquemas que queramos proveer. En nuestro caso, tenemos los esquemas para usuarios, posts y comentarios.
3.3.- Creamos el servidor
Para finalizar, crearemos nuestro servidor express, donde configuraremos nuestro endpoint GraphQL. Lo primero de todo, es añadir las dependencias que necesitaremos, que en este caso son express y express-graphql:
yarn add express express-graphql
Creamos una carpeta server y, dentro de ella, un archivo llamado server.js:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
import express from 'express'; import graphQLHTTP from 'express-graphql'; import { server } from '../config'; import { Schema } from '../graphql/schema'; import {} from './database'; const app = express(); app.use(graphQLHTTP({ schema: Schema, graphiql: true })); app.listen(server.port, () => { console.log(`App listen on ${server.port}`) }); |
Esta parte no tiene mucha complicación:
- Importamos express y graphQHTTP desde las librerías que acabamos de instalar.
- Importamos la configuración de servidor desde nuestro fichero config.js. Para ello, lo actualizamos de la siguiente forma:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
const database = { name : 'graphqltest', username: 'graphql', password: 'graphql_test', host: 'localhost', port: '27017' }; const server = { port: 3001 } export { database, server } |
- Importamos la configuración necesaria para conectarnos a nuestra base de datos. Esta configuración la realizaremos en un fichero index.js situado dentro de una carpeta database, que crearemos.
|
1 2 3 4 5 6 7 8 9 10 11 |
import mongoose from 'mongoose'; // Mandatory imports (define moongose schemas) import {} from '../../domain' import { database } from '../../config' const { name, username, password, host, port } = database; mongoose.Promise = global.Promise; mongoose.connect(`mongodb://${username}:${password}@${host}:${port}/${name}`); |
- Es un esquema muy parecido al que seguimos en el fichero seed.js. Importamos los parámetros de configuración de la base de datos, importamos los modelos de dominio que hemos creado y creamos una conexión a la base de datos.
- Continuando en nuestro server.js, nos queda crear nuestra aplicación express e indicarle que use graphQL (app.use(graphQLHTTP)). En este último hemos de indicarle que utilice el esquema que hemos terminado de detallar en el apartado anterior y que active graphiql. Esta última es una herramienta que nos permite probar y lanzar querys a nuestro endpoint graphql. Lógicamente, cuando estemos en producción habría que desactivarlo.
- Por último, hemos de añadir en nuestro package.json el script para arrancar nuestro servidor:
|
1 2 3 4 |
"scripts": { "start": "babel-node ./server/server.js", "seed": "babel-node ./domain/seed/seed.js" }, |
3.4.- Probando nuestro servidor
Con todo lo anterior, ya podríamos lanzar nuestro servidor y probar a ejecutar nuestras primeras consultas. Para ello, ejecutamos en nuestro terminal:
yarn start
En nuestro navegador favorito, nos vamos a localhost:3001/graphql y veremos la interfaz de GraphiQL:
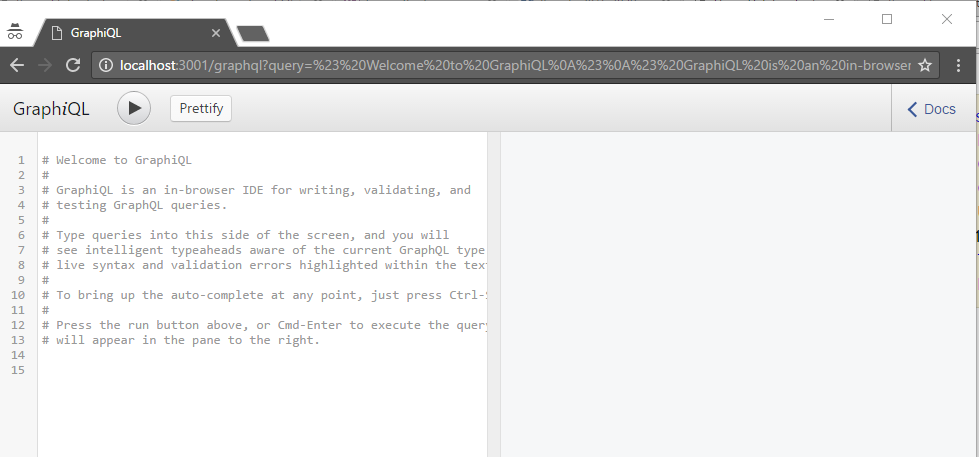
Esta herramienta nos va dando todas las posibilidades que tenemos utilizando Ctrl+Espacio. Así, si lo hacemos en este instante, podemos observar los distintos tipos de consultas que podemos realizar:
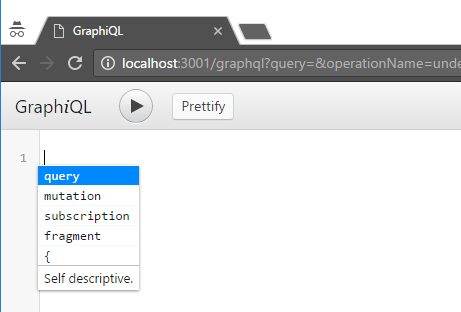
Vemos que nos ofrece la posibilidad de elegir entre query, mutation, subscription y fragment. En nuestro esquema sólo hemos definido querys, que se refiere a obtener o consultar datos. Mutations son aquellas consultas donde realizaremos modificaciones de los datos almacenados. Subscription es un tipo especial de consulta donde los datos se envían automáticamente al cliente conforme haya cambios. Fragments son agrupaciones de datos que se pueden reutilizar en varios tipos. Como vemos, en nuestro ejemplo, sólo estamos tratando la superficie de todo lo que graphql puede ofrecer, en otros posts podemos adentrarnos en funcionamientos más avanzados.
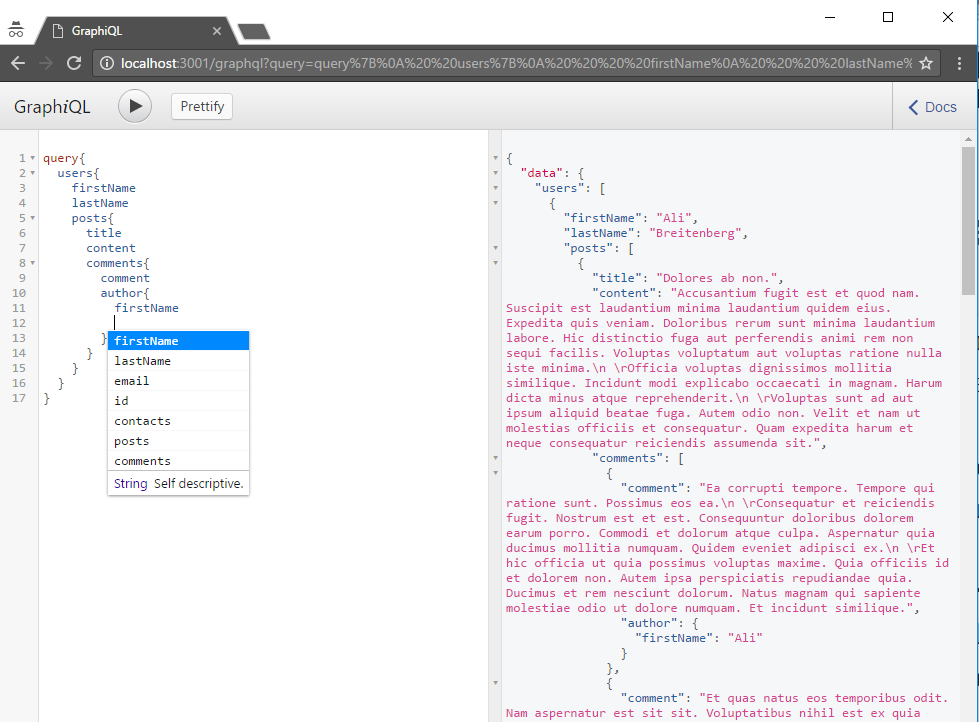
Como vemos, una vez elaborada una consulta válida, el servidor nos responde añadiendo los datos correspondientes a la estructura de la consulta.

En este ejemplo, vemos como podemos añadir argumentos a nuestra query.
4.- Añadiendo pequeñas mejoras
4.1.- DataLoaders
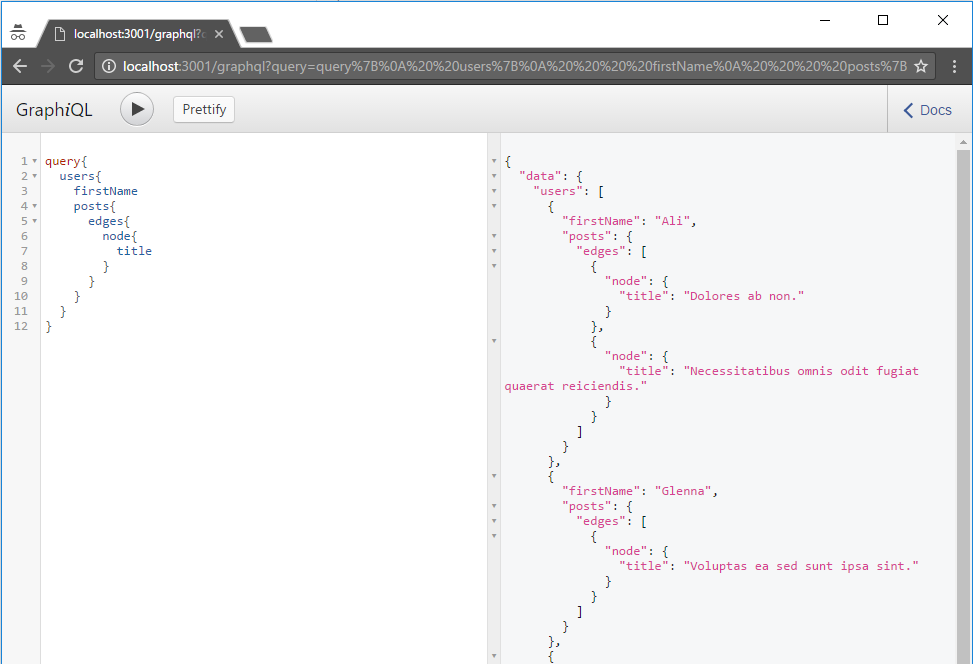
Imaginemos que queramos realizar una consulta parecida a la siguiente:
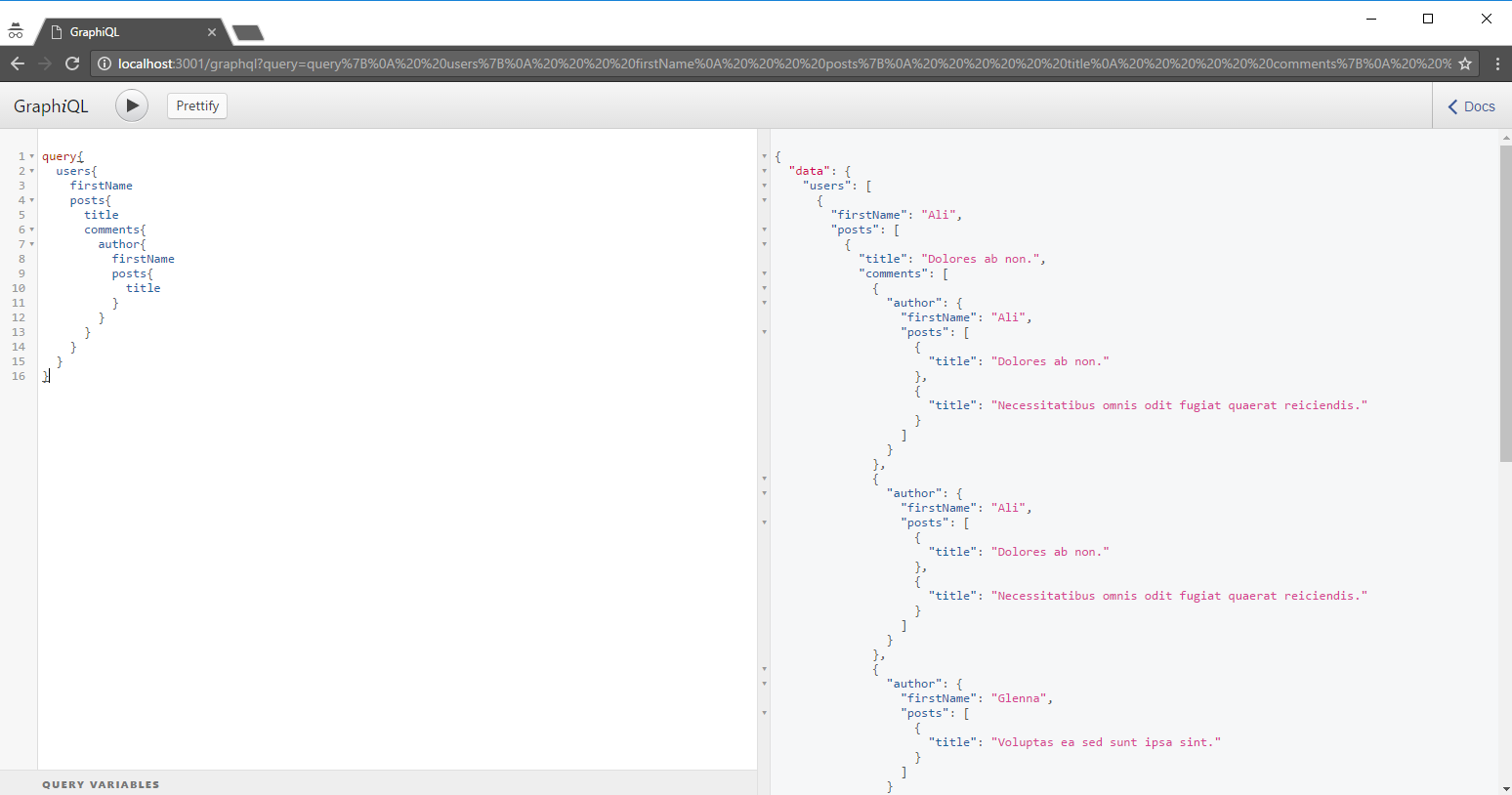
Si vemos las consultas a base de datos que se realizan para llevar a cabo esta llamada, hay muchas que se repiten. Esto ocurre porque cada vez que vamos adentrándonos en nuestra query hay objetos repetidos. En nuestro ejemplo, pedimos la lista de usuarios. De todos los usuarios, pedimos sus posts. De cada post, pedimos sus comentarios. De cada comentario, su autor y de cada autor sus posts.
El resumen de las llamadas que se realizan es el siguiente:
find { find: «users», filter: {} }
find { find: «posts», filter: { _id: { $in: [ ObjectId(‘583c24ce6ad77c26f82bf058’), ObjectId(‘583c24ce6ad77c26f82bf059’) ] } } }
find { find: «posts», filter: { _id: { $in: [ ObjectId(‘583c24ce6ad77c26f82bf05a’) ] } } }
find { find: «posts», filter: { _id: { $in: [ ObjectId(‘583c24ce6ad77c26f82bf05b’) ] } } }
find { find: «comments», filter: { _id: { $in: [ ObjectId(‘583c24ce6ad77c26f82bf05c’), ObjectId(‘583c24ce6ad77c26f82bf05d’), ObjectId(‘583c24ce6ad77c26f82bf061’) ] } } }
find { find: «comments», filter: { _id: { $in: [ ObjectId(‘583c24ce6ad77c26f82bf05e’), ObjectId(‘583c24ce6ad77c26f82bf05f’), ObjectId(‘583c24ce6ad77c26f82bf060’) ] } } }
find { find: «comments», filter: { _id: { $in: [ ObjectId(‘583c24ce6ad77c26f82bf062’) ] } } }
find { find: «users», filter: { _id: ObjectId(‘583c24ce6ad77c26f82bf055’) }, limit: 1, batchSize: 1, singleBatch: true }
find { find: «users», filter: { _id: ObjectId(‘583c24ce6ad77c26f82bf055’) }, limit: 1, batchSize: 1, singleBatch: true }
find { find: «users», filter: { _id: ObjectId(‘583c24ce6ad77c26f82bf056’) }, limit: 1, batchSize: 1, singleBatch: true }
find { find: «users», filter: { _id: ObjectId(‘583c24ce6ad77c26f82bf055’) }, limit: 1, batchSize: 1, singleBatch: true }
find { find: «users», filter: { _id: ObjectId(‘583c24ce6ad77c26f82bf055’) }, limit: 1, batchSize: 1, singleBatch: true }
find { find: «users», filter: { _id: ObjectId(‘583c24ce6ad77c26f82bf056’) }, limit: 1, batchSize: 1, singleBatch: true }
find { find: «users», filter: { _id: ObjectId(‘583c24ce6ad77c26f82bf057’) }, limit: 1, batchSize: 1, singleBatch: true }
find { find: «posts», filter: { _id: { $in: [ ObjectId(‘583c24ce6ad77c26f82bf058’), ObjectId(‘583c24ce6ad77c26f82bf059’) ] } } }
find { find: «posts», filter: { _id: { $in: [ ObjectId(‘583c24ce6ad77c26f82bf05a’) ] } } }
find { find: «posts», filter: { _id: { $in: [ ObjectId(‘583c24ce6ad77c26f82bf058’), ObjectId(‘583c24ce6ad77c26f82bf059’) ] } } }
find { find: «posts», filter: { _id: { $in: [ ObjectId(‘583c24ce6ad77c26f82bf058’), ObjectId(‘583c24ce6ad77c26f82bf059’) ] } } }
find { find: «posts», filter: { _id: { $in: [ ObjectId(‘583c24ce6ad77c26f82bf05a’) ] } } }
find { find: «posts», filter: { _id: { $in: [ ObjectId(‘583c24ce6ad77c26f82bf05b’) ] } } }
DataLoader es una utilidad que ha introducido Facebook que se puede utilizar para llevar a cabo un procesamiento por lotes y caché de las consultas que se realizan. Se puede entender que trata de resolver el problema N+1, que surge cuando tienes una colección de datos y, a su vez, cada elemento de esa colección puede tener otra colección de datos. A la hora de crear un nuevo dataloader lo haremos con una función, que a partir de un array de keys, devuelve una promesa que se resuelve a un array de values, y un conjunto de opciones (activar caché o no, si queremos que las consultas se ejecuten por lotes o no…)
Lo que haremos es lo siguiente:
- Definiremos nuestros dataloaders. Para ello, creamos una carpeta llamada dataLoaders dentro de la carpeta schemas. Creamos tres archivos: userLoader, postLoader y commentLoader. El contenido de ellos es muy parecido, así que mostraremos userLoader:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
import DataLoader from 'dataloader'; import { UserModel } from '../../../domain'; const getUsersById = keys => UserModel.find({'_id': { $in: keys }}, (_, values) => values); const UserLoader = new DataLoader( keys => getUsersById(keys).then(values => keys.map(key => values.find(elem => elem._id.toString() === key.toString()) )) ); export { UserLoader } |
- Hemos creado nuestro dataloader, definiendo una función que va a recibir un array de keys y devuelve una promesa, que es getUsersById(keys) que es la consulta que realizamos a nuestra base de datos utilizando mongooose. Cuando la promesa se resuelve, iteramos por cada una de las keys y devolvemos el valor que hemos encontrado en el array devuelto desde base de datos, donde el id del objeto coincida con la key.
- Añadimos un nuevo fichero index.js en la raíz de la carpeta graphql; donde vamos a recoger el esquema general que hemos definido anteriormente y todos los loaders que hemos creado. Quedaría de la siguiente forma:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
import { Schema } from './schema'; import { UserLoader } from './schemas/dataLoaders/userLoader'; import { PostLoader } from './schemas/dataLoaders/postLoader'; import { CommentLoader } from './schemas/dataLoaders/commentLoader'; const Loaders = { user: UserLoader, post: PostLoader, comment: CommentLoader } export { Schema, Loaders } |
- Modificamos nuestro server.js, importando los dataloaders y el esquema desde la nueva localización. Así mismo, hemos de indicar que en el contexto de la petición se incluyan los loaders, para tenerlos disponibles allí donde los necesitemos:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
import express from 'express'; import graphQLHTTP from 'express-graphql'; import { server } from '../config'; import { Schema, Loaders } from '../graphql'; import {} from './database'; const app = express(); app.use(graphQLHTTP({ context: {Loaders}, schema: Schema, graphiql: true })); app.listen(server.port, () => { console.log(`App listen on ${server.port}`) }); |
- Por último, hemos de modificar las funciones resolve de nuestros esquemas GraphQL para que utilicen los loaders. Ilustraremos el cambio a partir del esquema de usuarios:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
import { GraphQLObjectType, GraphQLString, GraphQLList } from 'graphql'; import { Post } from './post'; import { Comment } from './comment'; import { UserModel} from '../../domain' const User = new GraphQLObjectType({ name: 'User', description: 'General user of the app', fields: () => ({ firstName: { type: GraphQLString }, lastName: { type: GraphQLString }, email: { type: GraphQLString }, id: { type: GraphQLString }, contacts: { type: new GraphQLList(User), resolve: (user, args, {Loaders}) => Loaders.user.loadMany(user.contacts) }, posts: { type: new GraphQLList(Post), resolve: (user, args, {Loaders}) => Loaders.post.loadMany(user.posts) }, comments: { type: new GraphQLList(Comment), resolve: (user, args, {Loaders}) => Loaders.comment.loadMany(user.comments) } }) }); const UsersSchema = { type: new GraphQLList(User), args: { firstName: { type: GraphQLString }, lastName:{ type: GraphQLString } }, resolve: (root, args) => UserModel.find(args, (_, values) => values) } const UserSchema = { type: User, args: { id: { type: GraphQLString }, email:{ type: GraphQLString } }, resolve: (root, args) => UserModel.findOne(args, (_, value) => value) } export { User, UserSchema, UsersSchema }; |
- Como vemos, las funciones resolve tienen tres argumentos: el objeto, un conjunto de argumentos y el contexto (que utilizamos aplicando destructoring y quedándonos con los Loaders). A partir del objeto Loaders accedemos al loader correspondiente (en este caso user) y llamamos a la función loadMany (en este caso es loadMany ya que queremos cargar varios modelos, si sólo cargaramos un modelo utilizaremos load) a la que le pasamos por parámetro un array con los ids de los objetos que queremos recuperar.
- Un aspecto a mejorar es que en las funciones resolve de los esquemas no hemos utilizado dataloaders. Esto es debido a que al hacer uso de otros argumentos para recuperar entidades, deberíamos crear dataloaders específicos.
Por último, vemos las consultas a base de datos que se realizan para resolver la misma consulta que hemos visto anteriormente:
find { find: «users», filter: {} }
find { find: «posts», filter: { _id: { $in: [ ObjectId(‘583c24ce6ad77c26f82bf058’), ObjectId(‘583c24ce6ad77c26f82bf059’), ObjectId(‘583c24ce6ad77c26f82bf05a’), ObjectId(‘583c24ce6ad77c26f82bf05b’) ] } } }
find { find: «comments», filter: { _id: { $in: [ ObjectId(‘583c24ce6ad77c26f82bf05c’), ObjectId(‘583c24ce6ad77c26f82bf05d’), ObjectId(‘583c24ce6ad77c26f82bf061’), ObjectId(‘583c24ce6ad77c26f82bf05e’), ObjectId(‘583c24ce6ad77c26f82bf05f’), ObjectId(‘583c24ce6ad77c26f82bf060’), ObjectId(‘583c24ce6ad77c26f82bf062’) ] } } }
find { find: «users», filter: { _id: { $in: [ ObjectId(‘583c24ce6ad77c26f82bf055’), ObjectId(‘583c24ce6ad77c26f82bf055’), ObjectId(‘583c24ce6ad77c26f82bf056’), ObjectId(‘583c24ce6ad77c26f82bf055’), ObjectId(‘583c24ce6ad77c26f82bf055’), ObjectId(‘583c24ce6ad77c26f82bf056’), ObjectId(‘583c24ce6ad77c26f82bf057’) ] } } }
find { find: «posts», filter: { _id: { $in: [ ObjectId(‘583c24ce6ad77c26f82bf058’), ObjectId(‘583c24ce6ad77c26f82bf059’), ObjectId(‘583c24ce6ad77c26f82bf05a’), ObjectId(‘583c24ce6ad77c26f82bf05b’) ] } } }
Hemos pasado a realizar sólo 5 llamadas a base de datos para resolver la misma consulta que antes, con lo que la mejora resulta más que evidente. E, incluso, podríamos mejorar aún más si añadimos los dataloaders específicos que hemos comentado anteriormente.
4.2.- Graffiti
Recopilando todo el desarrollo que hemos llevado a cabo, al final hemos tenido que implementar dos esquemas para cada modelo, uno de mongoose y otro para GraphQL. Graffiti (https://github.com/RisingStack/graffiti) es un paquete que se encarga de recopilar todos los modelos que hemos implementado en mongoose, generar los esquemas GraphQL y exponerlos a través de nuestro servidor. Actualmente sólo tiene adaptador para mongoose, pero funciona tanto en express como en Koa o Hapi. Los esquemas GraphQL que genera son Relay compilant, con lo que es muy útil si nuestro cliente implementa Relay (https://github.com/facebook/relay).
Lo implementamos en nuestro ejemplo:
- Eliminamos todo el contenido de la carepta graphql y la carpeta database dentro de server.
- Quitamos las dependencias de express-graphql, graphql y dataloader
yarn remove express-graphq graphql dataloader
- Añadimos las dependencias de graffiti, graffiti-mongoose, body-parser y de graphql versión 0.7.0 (en el momento de hacer el post no funciona con la versión actual de graphql):
yarn add @risingstack/graffiti @risingstack/graffiti-mongoose body-parser graphql@0.7.0
- Dentro de la carpeta graphql, creamos un archivo index.js, en el cual definimos nuestra conexión a base de datos y luego utilizamos la función getSchema de graffiti-mongoose pasándole como parámetro un array con los modelos mongoose a partir de los que queramos generar nuestro esquema GraphQL:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
import mongoose from 'mongoose'; import { getSchema } from '@risingstack/graffiti-mongoose'; import { database } from '../config'; import { UserModel, PostModel, CommentModel } from '../domain' const { name, username, password, host, port } = database; mongoose.Promise = global.Promise; mongoose.connect(`mongodb://${username}:${password}@${host}:${port}/${name}`); export default getSchema([UserModel, PostModel, CommentModel]); |
- Modificamos el archivo server.js, importando el esquema generado y utilizando la implementación de graffiti para express:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import express from 'express'; import graffiti from '@risingstack/graffiti'; import { json } from 'body-parser'; import schema from '../graphql'; import { server } from '../config'; const app = express(); app.use(json()); app.use(graffiti.express({schema})); app.listen(server.port, () => { console.log(`App listen on ${server.port}`) }); |
Lanzamos nuestro servidor y en http://localhost:3001/graphql, abriendo el desplegable de docs, observamos lo siguiente:


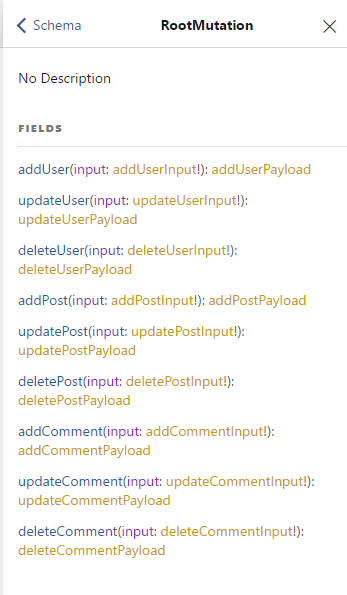
Observamos que, a parte de poder consultar, también implementa mutations, con lo que nos posibilita a hacer escrituras en base de datos. Otro punto a considerar lo hemos comentado previamente: el esquema que genera es compatible con Relay. Por ello, las consultas han de hacerse de forma diferente, considerando los interfaces Node y Edge, entre otras cosas:
5.- Cliente básico
Sólo para ilustrar el ejemplo, montaremos un cliente básico que ataque al servidor que acabamos de crear. Partiremos de un starter react-redux que teníamos desarrollado previamente y construiremos nuestro cliente integrando apollo-client con redux:
- Clonamos el repositorio https://github.com/franmolmedo/react-redux-starter
- Añadimos las dependencias de apollo-client, graphql-tag react-apollo:
yarn add apollo-client graphql-tag react-apollo
- Creamos un fichero llamado client.js en la raíz de la carpeta app; donde definiremos nuestro cliente de apollo:
|
1 2 3 4 5 6 7 8 9 10 |
import ApolloClient, { createNetworkInterface } from 'apollo-client'; const networkInterface = createNetworkInterface({uri: 'http://localhost:3001'}); const client = new ApolloClient({ networkInterface, reduxRootSelector: 'root' }); export default client; |
- Tenemos que actualizar el fichero reducers.js para incluir el reducer básico de nuestro cliente:
|
1 2 3 4 5 6 7 8 9 |
import { combineReducers } from 'redux'; import client from './client'; const reducers = combineReducers({ root : client.reducer() }); export default reducers; |
- Actualizamos app.js, añadiendo el nuevo provider de Apollo y componiendo la nueva store con el cliente que acabamos de crear:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
import React from 'react'; import ReactDOM from 'react-dom'; import { createStore, applyMiddleware, compose } from 'redux'; import { ApolloProvider } from 'react-apollo'; import { Router, browserHistory } from 'react-router'; import reducers from './reducers'; import client from './client'; import routes from './routes'; const store = createStore( reducers, {}, compose( applyMiddleware(client.middleware()), window.devToolsExtension ? window.devToolsExtension() : f => f ) ); ReactDOM.render( <ApolloProvider store={store} client={client}> <div> <Router history={browserHistory} routes={routes}/> </div> </ApolloProvider> , document.querySelector('#root')); |
- Por último, actualizamos uno de los dos componentes (lo haremos sobre master) que están en el starter para importar una lista de usuarios:
- Creamos un fichero master.data.js, donde definiremos la query de GraphQL que queramos lanzar para recuperar los datos de usuarios:
|
1 2 3 4 5 6 7 8 9 10 11 |
import gql from 'graphql-tag'; const GET_USERS = gql`query users { users{ firstName lastName id } }`; export default GET_USERS; |
- Actualizamos master.js para crear un componente que reciba los datos. Como vemos, utilizamos la función connect para conectarlo con redux y a su vez usamos graphql de react-apollo para indicarle la query con la que conseguir los datos.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
import { graphql } from 'react-apollo'; import { connect } from 'react-redux'; import { UserItem } from './user-item'; import GET_USERS from './master.data'; import masterStyles from './master.sass'; class Master extends Component{ render(){ const { loading, error, users } = this.props.data; if (loading) return <div>loading...</div>; if (error) return <div>Error!!!!</div>; const usersList = users.map(user => { return <UserItem key={user.id} user={user} />; }); return ( <ul className={masterStyles.list}> {usersList} </ul> ) } } Master.propTypes = { data: React.PropTypes.shape({ loading: React.PropTypes.bool, users: React.PropTypes.array, error: React.PropTypes.bool }) }; const MasterContainer = connect(null, null)(graphql(GET_USERS)(Master)) export { MasterContainer }; |
- Por último, creamos un componente funcional que se encargue de pintar cada elemento recuperado:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
import React from 'react'; const UserItem = ({user}) => { return ( <ul> <li> <div>First Name: {user.firstName}</div>; <div>Last Name: {user.lastName}</div>; </li> </ul> ) } UserItem.propTypes = { user: React.PropTypes.object, }; export { UserItem }; |
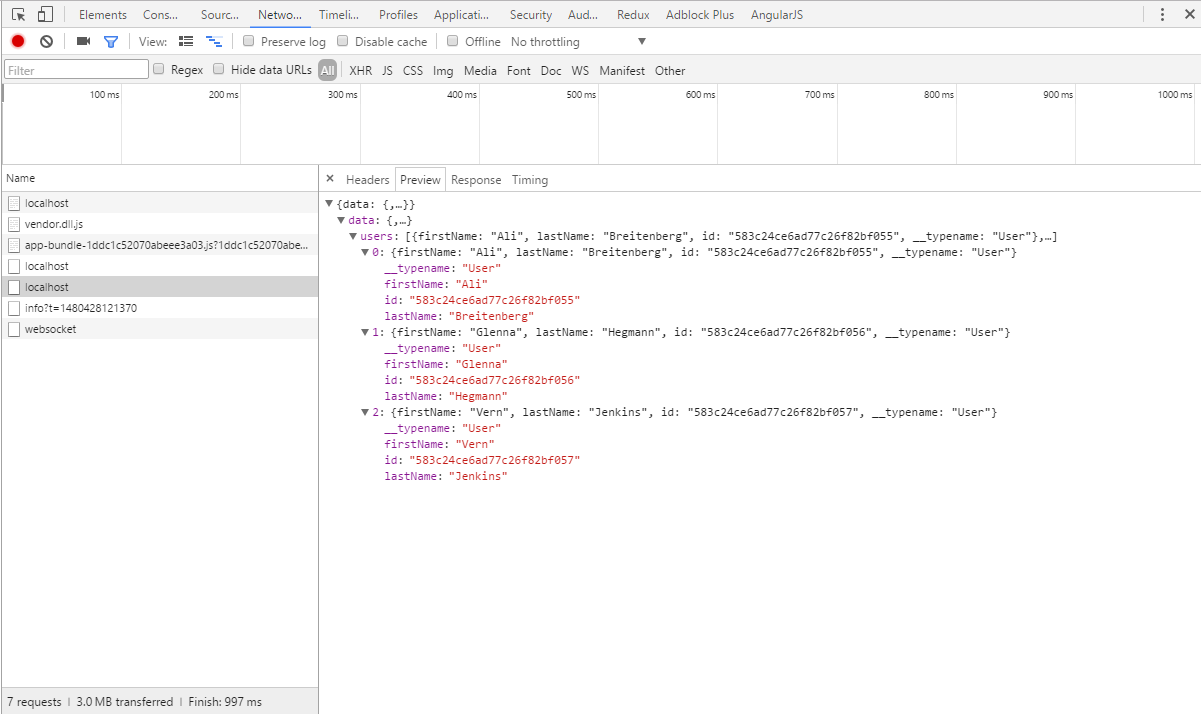
- Cuando arrancamos el proyecto (teniendo el servidor GraphQL arrancado), observamos que nos aparece un error de consola. Esto se debe a que no hemos habilitado cors en el servidor.

- Para habilitar cors en servidor, añadimos el paquete cors y en server.js indicamos que la aplicación utilice cors:
app.use(cors())
- Con ello, volvemos a probar y obtenemos el resultado esperado:

6.- Conclusiones y trabajo futuro
Todo lo mostrado no es más que una pequeña introducción al uso de GraphQL. Quedarían muchos temas por tocar como el hecho de implementar autenticación, modificaciones de los datos almacenados (mutations), actualización de los datos en tiempo real (suscriptions), además de ahondar en el sistema de tipos, utilizando fragments, interfaces, directives…
Sin embargo, sí nos podemos hacer una idea de lo que propone y usarlo como punto de partida para realizar pruebas en proyectos algo más serios. Además que nos posibilita empezar a trabajar con otras tecnologías como Relay o ApolloClient en nuestras aplicaciones cliente.
En nuestro caso hemos trabajado montando GraphQL en un servidor express, porque es la plataforma que mantiene oficialmente facebook. Sin embargo, existen librerías que permiten montar un edpoint GraphQL en otros entornos:
- Python: https://github.com/graphql-python/graphene
- Ruby: https://github.com/rmosolgo/graphql-ruby
- C#: https://github.com/graphql-dotnet/graphql-dotnet
- Java: https://github.com/graphql-java/graphql-java
También es de interés compararlo con otras implementaciones, como Falcor (https://github.com/Netflix/falcor), para ver cual de todas las opciones de adapta mejor a cada proyecto en concreto.
Sin más os dejo los enlaces a los repositorios con el código utilizado, junto con otros enlaces de interés relativo a todos estos temas.
- React-Redux Starter: https://github.com/franmolmedo/react-redux-starter
- Servidor de ejemplo básico con dataloaders: https://github.com/franmolmedo/graphql-server-example
- Servidor de ejemplo con graffiti: https://github.com/franmolmedo/graphql-server-graffiti
- Ejemplo de cliente utilizando apollo-client: https://github.com/franmolmedo/graphql-example-client-apollo
- Uso de dataloaders: http://gajus.com/blog/9/using-dataloader-to-batch-requests
- Curso de GraphQL: https://learngraphql.com/basics/introduction
- Repositorio de GitHub con lecciones de GraphQL: https://github.com/mugli/learning-graphql
- Apollo-client: https://github.com/apollostack/apollo-client
- Página oficial de GraphQL: http://graphql.org/
- Video de Stephen Luscher donde enseña a montar un endpoint GraphQL en python, ruby y node.js: https://www.youtube.com/watch?v=UBGzsb2UkeY
Happy GraphQLing! 😛
1 Pingback