
It is an undeniable fact that in recent times, the volume of data that organizations must manage has soared. Analyze so much data; in order to make strategic decisions has become a real problem. In this article we will make an introduction to OLAP data cubes in SQL Server 2008 R2 Analysis Services, a powerful tool that can transform vast amounts of data into useful information.
The excessive increase of the volume of data into information systems of a company, without proper organization and structure, can have negative effects such as slow in their status analysis, or worse, lead to inappropriate strategic decision making, since having millions of records distributed across multiple heterogeneous data sources (SQL Server and Access databases, flat files, Excel spreadsheets, etc..), need not be synonymous in all cases of a system that provides quality information.
To solve such problems we have the so-called Business Intelligence (BI) tools, and in the case we are working with SQL Server, one of its main components: SQL Server Analysis Services (SSAS), allow us to create a data cube, an element by which to generate information to analyze the state of the company from all its data sources.
Conceptual
From a conceptual perspective, a data cube is one more part into the gear of an information system called data warehouse. The cube is provided with internal machinery that can process high volumes of data in a relatively short period of time, and whose goal is always to obtain a numerical result (amount of sales, expenses, number of products sold, etc.). These results may change depending on one or more filters that apply on the cube. The response time is minimal because the cube processing engine precalculates the possible combinations of results that the user can request. The numerical results obtained are called measures, while the elements used to sort / filter information are called dimensions.
Represented graphically, a data cube is shown as the geometric shape which takes its name, horizontally and vertically partitioned into a series of divisions that give rise to multiple cells, which identify each of the possible outcomes of the measures, obtained by the intersection in each cell of the dimensions that make up the cube. Next figure shows such a graphical representation of a cube, with sales information by product, employees and currency. On the cube sides are placed the dimensions, whose cross produces numerical results in the cells.
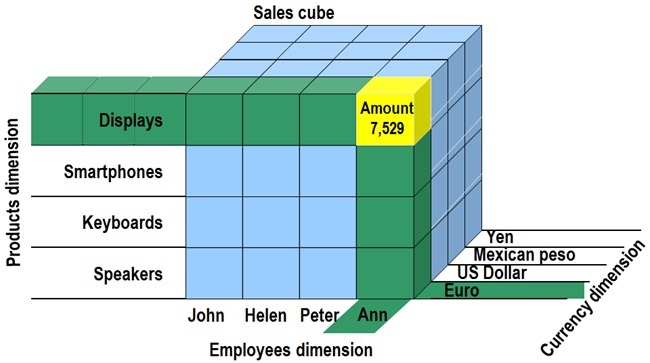
Watching the previous figure, the reader may think that the number of dimensions in a cube is limited to those we represent through that geometric shape. Nothing is further from reality, since a cube can withstand a high number of dimensions, which loosely cover the requirements of the information to be obtained.
We can find additional information about the conceptual aspects in a series of articles on data cubes in SQL Server, previously appeared in this publication.
Main elements in a data warehouse
As mentioned above, a data cube is one of the pieces of a more complex architecture: the data warehouse, in which creative process involved several components, which are responsible to take the original data in the rough and polish it until it becomes in information ready for analysis. Next figure shows a diagram where we can see the phases of this transformation process.
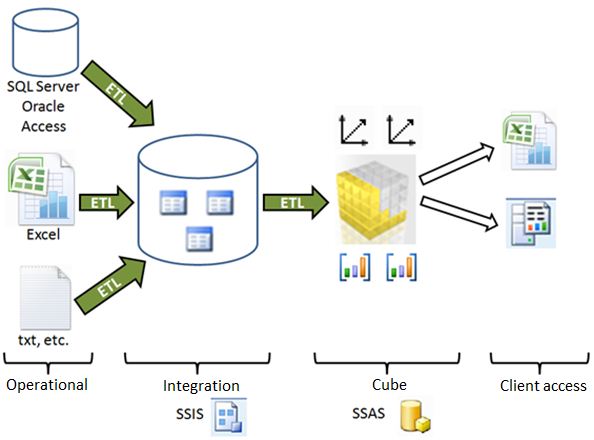
Broadly depicted, this process performs, in first place, an operation of extraction, processing and loading data from source origin, located in the operational area, to a database located in the integration area, using SQL Server Integration Services (SSIS) packages, which also performed data cleaning tasks.
Then we would pass to the cube construction phase, which we will develop using SQL Server Analysis Services (SSAS). Finally, we reach the stage of cube query by end users, using several products such as SQL Server Reporting Services (SSRS), Excel, etc.
Physical elements. Fact and dimension tables
At the physical level, to build a data cube we need a database containing a table called fact table, whose structure is formed by a series of fields, called measurement fields, from which we obtain the cube’s numerical results; and on the other hand, a set of fields called dimension fields, that we will use to join with the dimension tables, in order to get filtered results for the several dimensions integrating the cube.
The other main foundation in the cube creation is made from the dimension tables. For each dimension or query / filter category we incorporate into our cube will need a table that will join with the fact table by a key field. This dimension table will act as a catalog of values, also called attributes, which will be used independently or combined with other dimensions, to obtain results with greater accuracy.
Developing a data cube
Once explained the necessary basics, we enter into the practical part of the article, where we’ll develop our own data cube. We will focus all our efforts exclusively on the cube creation, without addressing the extraction, transformation and loading operations, which would be made using SSIS packages, since the latter are issues that fall outside the scope of this article, pending a future delivery.
First, from Windows Start menu we’ll launch SQL Server Business Intelligence Development Studio, which is located in Microsoft SQL Server 2008 R2 program group. This is a special version of Visual Studio for BI projects development. In the starting dialog we’ll select Analysis Services Project as project template, giving it the name CuboDatosAdvWorks.
Then right-click Data Sources node in the Solution Explorer and select New Data Source option, which opens the wizard to create the cube data source, which in our case will be the test database AdventureWorksDW2008 available in CodePlex, whose structure is ready to be used in data cubes design.
We will leave the default options in the wizard until the connection to the data source step, selecting AdventureWorksDW2008. On reaching the wizard final step will see a summary of the data source we have created.

Our next step is to create a view of the data source, allowing us, as his name suggests, define a custom view of the database, including the tables we need to create the cube.
In this sample cube we’ll measure the amount of sales that AdventureWorks company resellers have invoiced. Being possible query / filter the results by currency type in which the sale was made, and geographic area where the order was sent. We will use FactResellerSales as fact table, and DimSalesTerritory and DimCurrency as dimension tables.
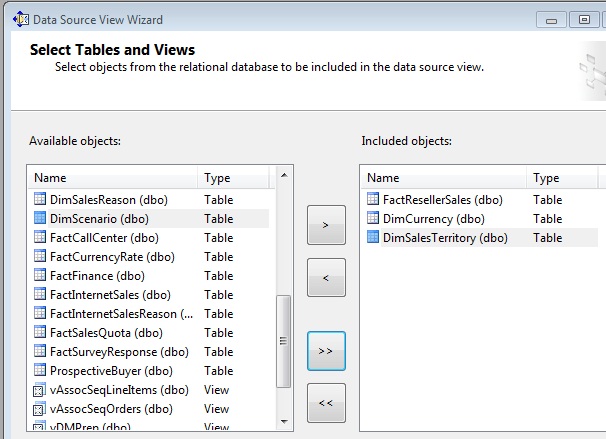
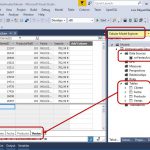
By right-clicking the Data Source Views node in Solution Explorer, we’ll select New Data Source View option, which opens a wizard in which first step we will choose the data source we just created. In the second step we’ll select the tables just mentioned.
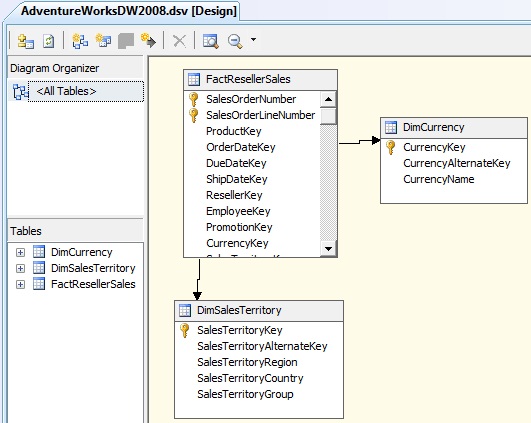
Once finished this wizard it will display its design window where we see a diagram of the selected tables, with the existing relationships between them.
Building dimensions. Basic dimension
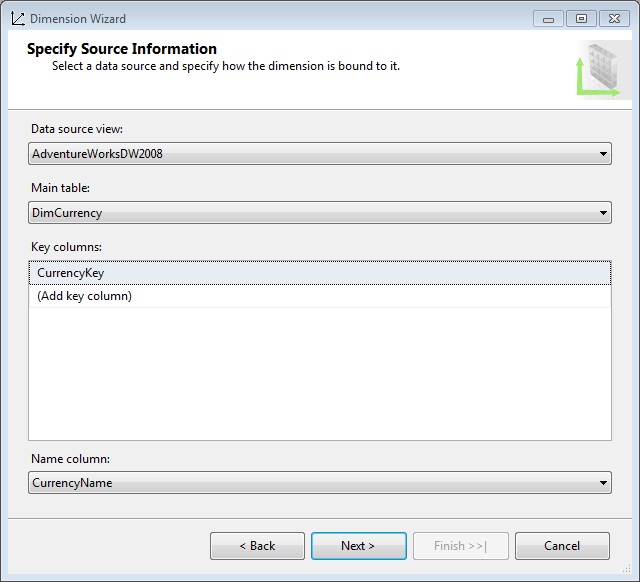
The next step is to create the dimension that allows us to query / filter the cube information by order payment currency. Right clicking on the Dimensions node of Solution Explorer, we’ll select the New Dimension option, starting the wizard as usual. In his first step Select Creation Method, we’ll leave the default option Use an existing table. Upon entering step Specify Source Information, three drop-down lists allow us to configure the information to be obtained for the dimension: Main table to choose the table that use in the dimension: DimCurrency; Key columns to indicate the primary key; and finally, Name column, selecting CurrencyName field, which identifies the attribute to be displayed.
In the Select Dimension Attributes step, the wizard will offer Currency Key as an attribute of the dimension, which we will use, but changing its name to Currency. An attribute is a field, normal or calculated, belonging to the dimension table that is shown as a label anywhere in the dimension involved as part of a query against the data cube.
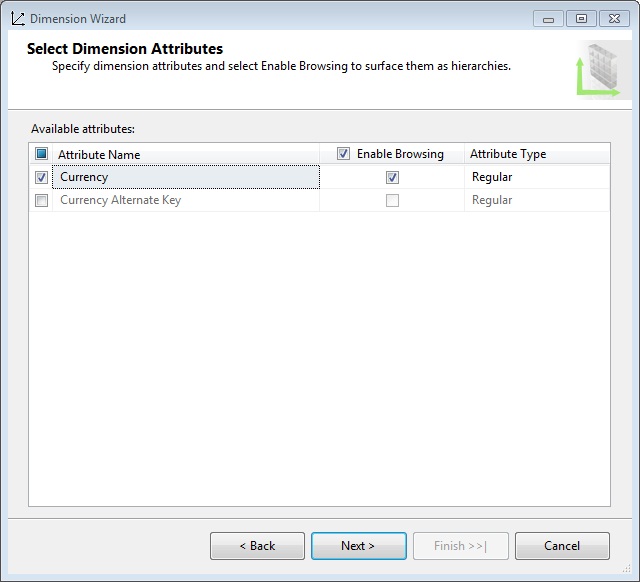
At the last step we shall give the name Currency to the dimension, finishing the wizard. The dimension designer will show now with the structure we just created. Among all the properties of the attribute Currency, the most important are Name, which contains the name that will appear in queries against the cube; KeyColumns, which contains the key field in the table that relates to the fact table, and NameColumn, containing the field of the table that shows the attribute’s value.
In case we need to add more attributes to the dimension, just drag and drop fields from the table in Data Source View pane to the Attributes pane of the designer.
When attribute creation is finished, we’ll process the dimension by clicking the Process button on the toolbar’s designer, or through the Visual Studio Build | Process menu. When the processing dimension is completed, we will click on the designer’s Browser tab, where we’ll inspect its contain.
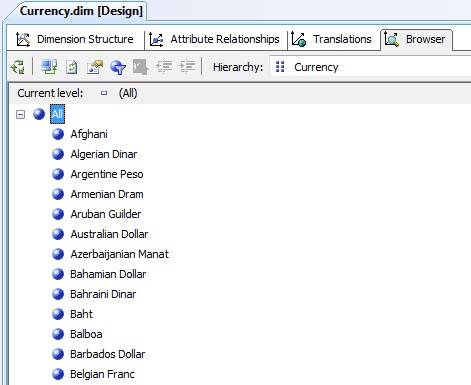
Building dimensions. Hierarchical dimension
In addition to the single level dimensions, as we just saw in the previous section, we can create dimensions that group data on multiple levels, which provide a greater ability to disaggregate the cube information when consulted through a dimension of this type. This element is called a dimension hierarchy.
Let’s take DimSalesTerritory table from our Data Source View sample project. We can see that the combination of SalesTerritoryGroup, SalesTerritoryCountry and SalesTerritoryRegion fields allow us to establish several grouping levels.
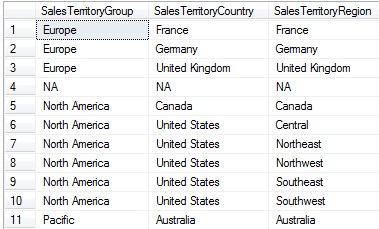
Suppose we need to create a dimension based on this table to obtain, starting from SalesTerritoryGroup field, a hierarchical level display effect.
To do this, we will create the dimension using the wizard in the way explained in previous section. The default attribute selected by the wizard will correspond to table’s primary key: SalesTerritoryKey field.
Once located in the dimension designer, drag from the table in Data Source View pane the SalesTerritoryGroup, SalesTerritoryCountry and SalesTerritoryRegion fields, and drop on the Attributes panel of the same designer.
Then drag the Sales Territory Group attribute to the Hierarchies pane, which will create a new hierarchy. We’ll change its default name by Sales Territory. Also in this hierarchy will drop the Sales Territory Country and Sales Territory Region, noting that next to the hierarchy name appears a warning icon which informs us that relationships between the hierarchy attributes aren’t properly created, which can negatively affect the dimension processing.
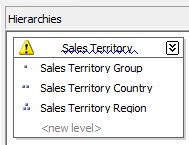
To solve this problem we will click the Attribute Relationships tab, where we see the relationships between attributes automatically created by the designer.
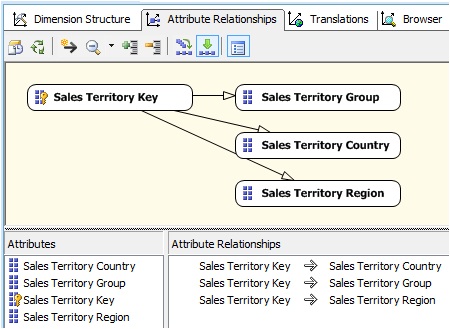
These relationships, however, are not valid for our purposes, so we’ll select their representing arrows in the diagram and delete them. To create the new relationships drag from source attribute to destination, to leave them as see in next figure.

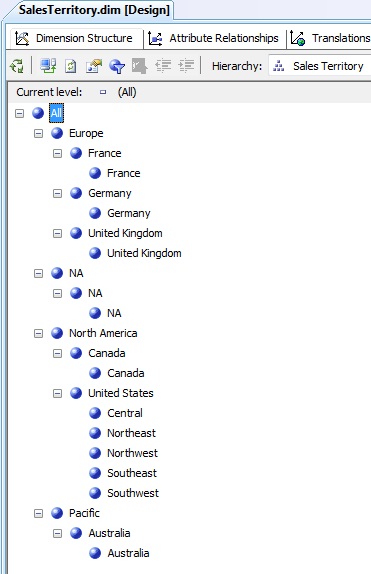
Before dimension processing let’s back to the Dimension Structure tab to verify that the warning is gone. On the other hand we’ll select all attributes of the Attributes panel, assigning the False value on his property AttributeHierarchyVisible, so we’ll get independent attributes are not shown, since what interests us here is to explore only the hierarchy. Next figure shows the dimension result, with all elements of the hierarchy expanded.
Cube Building
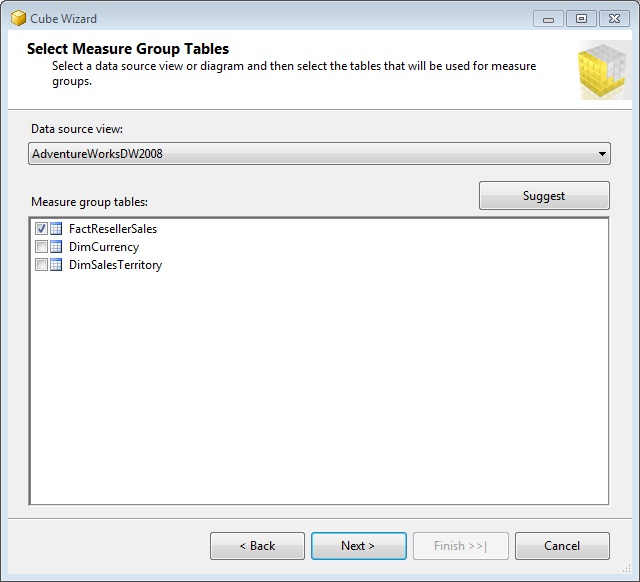
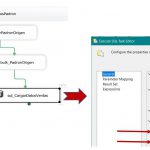
We reached the final stage in the development of our sample project: building the data cube. We will begin by right-clicking the Cubes node in Solution Explorer and selecting the Add Cube option, which will open the creation wizard, leaving the default values until the Select Measure Group Tables step, which as its name suggests, it asked us to select the table containing the fields that we use as measures for the cube, i.e. the fact table, which in this case will be FactResellerSales.
Clicking Next, go into the Select Measures step, where we have to select the fields that serve as cube measures. The goal of this cube is to ascertain the sales amount made by resellers, therefore, we’ll select only the SalesAmount field.

The next step prompts us to select the dimensions that will be part of the cube. It automatically detected the dimensions created by us earlier, which already are offered selected by default.
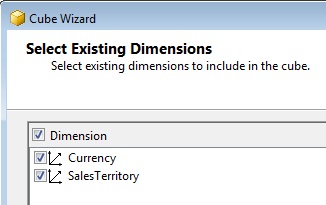
The wizard performs then a search in the fact table to find a field that could also be capable of being treated as a dimension. Since we don’t need this feature, we’ll uncheck the selection of the fact table as source for the creation of dimensions.
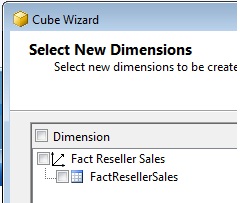
And now the final step, where we will give the name VentasDistribuidores to the cube, ending the wizard.
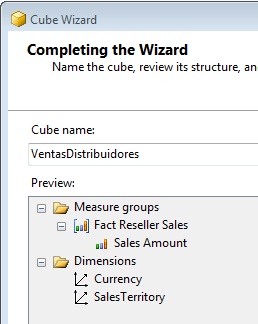
As a result the cube designer displays itself, showing various key elements, such as the dimensions pane, table diagram, measures, etc.
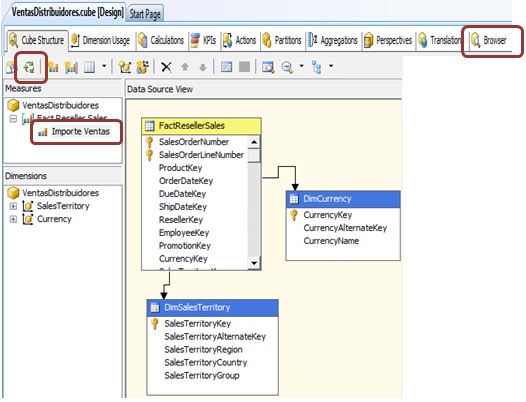
In the Measures pane appears the measure selected in the wizard, but we’ll change its name to Importe Ventas in properties window. In this same window we can watch the name, aggregate function used to calculate the measure, used table field, format string, and so on.

For the measure to appear correctly formatted, in addition to assigning a value to the FormatString property, in the cube properties we have to assign the value Spanish (Spain) to the Language property.
Finally, before we can see the cube, as we did with the dimensions, we must process it by clicking the Process button, which opens the dialog box cube processing where we’ll click the Run button.
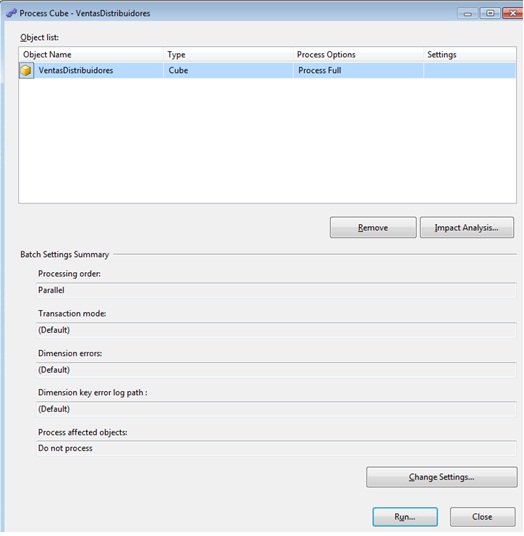
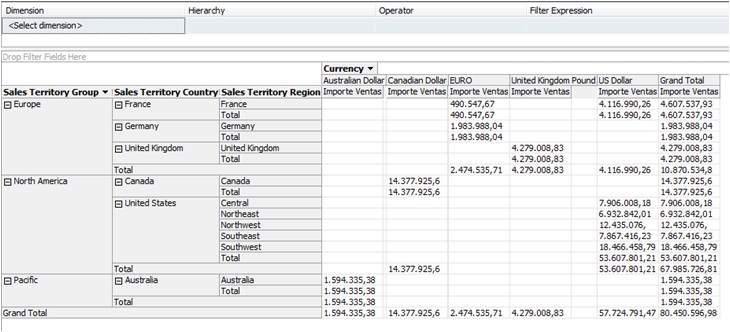
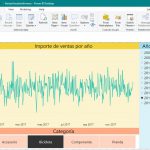
Once the cube has been processed, we can see its contents by clicking on the Browser tab. In the Measure Group pane we’ll expand the Measures node up to the Importe Ventas measure, which drag into the central area of the display. Then drag the SalesTerritory dimension to the display’s left margin. We can right click on this dimension, selecting Expand Items option, resulting in a display of the dimension elements. Finally drag the Currency dimension to the upper margin. As a result we get a data grid where each cell displays the measure for the intersection of the dimensions placed in columns and rows of data display.
Conclusions
In this article we have made an introduction to the development of data cubes with SQL Server 2008 Analysis Services, a component of SQL Server product family intended to provide business intelligence solutions that exploit the analytics potential that lies in data’s company. The possibilities and power of this tool are enormous, and we encourage the reader to implement them.


anonymous
(The spanish version of this article was previously published in dNM+ , issue 93) The recent SQL Server
anonymous
(The spanish version of this article was previously published in dNM+ , issue 83) PowerPivot is a technology