
Dentro del marco de las tecnologías para el desarrollo de sistemas BI (Business Intelligence): almacenes de datos (data warehouses, data marts), cubos de datos OLAP, modelos tabulares, etc., encargados de gestionar grandes volúmenes de datos; el entorno sanitario tiene una oportunidad muy importante, que es poder utilizar estas nuevas tecnologías y los grandes volúmenes de datos que genera en el análisis de datos para la elaboración de métricas e indicadores, mediante los cuales sea posible monitorizar el estado de salud de una población y sus determinantes, identificando áreas de mejora que puedan afectar a una población, en lo que a términos de salud se refiere.
En el presente artículo dedicaremos nuestros esfuerzos a elaborar un sistema de consulta, que tendrá como base una encuesta sanitaria realizada a una población ficticia que utilizaremos para ilustrar este ejemplo, y donde las herramientas que emplearemos serán SQL Server 2016 como motor de datos y PowerPivot (junto a expresiones DAX) como software para el análisis de datos y toma de decisiones.
Antes de continuar quisiera expresar mi agradecimiento a Jenaro Astray Mochales, Felicitas Domínguez Berjón, María Dolores Esteban Vasallo y Ricard Gènova Maleras, integrantes del Servicio de Informes de Salud y Estudios (Subdirección de Epidemiología, Dirección General de Salud Pública, Consejería de Sanidad. CM) por toda la ayuda e indicaciones proporcionadas para el adecuado enfoque y orientación de este artículo.
Pongámonos en situación
Supongamos que las autoridades sanitarias de una región (estado, provincia, comunidad, etc.) necesitan recabar datos acerca de la salud de la población residente en el área geográfica de su competencia. Para ello, elaboran una encuesta que realizan a todos los ciudadanos que acuden a los diferentes tipos de centros sanitarios en los que se presta atención médica.
Durante un periodo de varios meses se formulan las preguntas de la encuesta a los pacientes que acuden a los centros (en el caso de menores, las preguntas se realizan a los adultos al cargo), recogiéndose las respuestas mediante una aplicación diseñada a tal efecto, que las deposita en una base de datos de la que se extraen los datos para nuestro análisis.
Como es natural, del total de la población objetivo de la encuesta no se conseguirá entrevistar a todas las personas por diversos factores que escapan a nuestro control (no acuden a un centro sanitario en el periodo de la encuesta, rechazan participar, etc.), con lo que el nivel de participación no alcanzará el 100%. Es por ello que nuestra misión en el desarrollo de este sistema analítico consistirá en medir dicha participación en lo que respecta al alcance y evolución temporal de la misma, creando los indicadores que para ello sean necesarios.
Datos iniciales
Una vez descrito el escenario de trabajo, la primera acción a tomar consistirá en diseñar la base de datos que contendrá la población objeto del estudio.
Como ya hemos apuntado en un apartado anterior, debemos calcular, tanto en números absolutos como en porcentaje, la población que accede a participar en la encuesta, y ofrecer al usuario la posibilidad de analizar estas métricas por los atributos (dimensiones) de fecha de encuesta, edad y sexo de la persona encuestada. Seguidamente se muestran las sentencias DDL (Data Definition Language) de Transact-SQL a ejecutar en SQL Server. Por cuestiones de simplicidad en el mantenimiento del código fuente, en el presente artículo no se utilizan caracteres especiales como tilde o similares para nombrar identificadores como tablas, variables, etc.
CREATE DATABASE Encuesta; USE Encuesta; CREATE TABLE Poblacion ( LineaID int IDENTITY(1,1) NOT NULL, EdadID int NULL, SexoID char(1) NULL, FechaEncuesta date NULL ); CREATE TABLE Fechas ( FechaID date NULL, Fecha varchar(10) NULL, AnualidadID smallint NULL, Anualidad varchar(4) NULL, MesID tinyint NULL, MesNombre varchar(15) NULL, DiaID tinyint NULL, Dia varchar(2) NULL ); CREATE TABLE Edad ( EdadID int NULL, Edad varchar(3) NULL, GrupoEdad varchar(20) NULL, Orden int NULL ); CREATE TABLE Sexo ( SexoID char(1) NULL, Sexo varchar(15) NULL, Orden int NULL );
Para la creación de los datos de la encuesta utilizaremos alguna de las técnicas o herramientas de generación disponibles en multitud de sitios Web dedicados al desarrollo con SQL Server. En los siguientes enlaces se ofrecen algunos ejemplos: [1], [2], [3], [4] y [5].
En este caso, la tabla de población contiene alrededor de 3.800.000 filas (para nuestro ejemplo, entre tres y cuatro millones de registros sería una cantidad adecuada), con valores de edad comprendidos entre 0 y 100 años; fechas de encuesta con valor NULL o dentro del intervalo comprendido entre el 01/10/2015 y 31/01/2016 (dichos intervalos pueden ser distintos para el lector según los datos de prueba que haya creado); y los valores H y M para el sexo.
Conviene tener presente que en situaciones reales, el conjunto de datos que representa a la población seleccionada para una encuesta (tamaño de la muestra) es habitualmente muy inferior al volumen de datos que vamos a emplear en el presente artículo, pero dado que uno de los objetivos perseguidos es la demostración de las capacidades del motor de PowerPivot para trabajar con un considerable volumen de datos, nos hemos permitido tomarnos esta pequeña licencia al generar una base ficticia de población con una cantidad de registros mayor de lo acostumbrado en un escenario de estas características.
Respecto al resto de las tablas, para las edades y fechas de encuesta nos ayudaremos de la siguiente tabla auxiliar numérica [6].
CREATE TABLE Numeros ( NumeroID int NOT NULL ); WITH GNBase AS (SELECT N FROM (VALUES (1),(1)) AS NBase(N)), GN1 AS (SELECT 1 AS N FROM GNBase AS tblA CROSS JOIN GNBase AS tblB), GN2 AS (SELECT 1 AS N FROM GN1 AS tblA CROSS JOIN GN1 AS tblB), GN3 AS (SELECT 1 AS N FROM GN2 AS tblA CROSS JOIN GN2 AS tblB), GN4 AS (SELECT 1 AS N FROM GN3 AS tblA CROSS JOIN GN3 AS tblB), GNTotal AS ( SELECT 0 AS NumeroID UNION SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS NumeroID FROM GN4 ) INSERT INTO Numeros (NumeroID) SELECT NumeroID FROM GNTotal ORDER BY NumeroID OFFSET 0 ROWS FETCH FIRST 10001 ROWS ONLY; ALTER TABLE Numeros ADD CONSTRAINT PK_Numeros PRIMARY KEY (NumeroID);
Utilizando esta tabla numérica como soporte rellenaremos la tabla Fechas de la siguiente forma.
WITH cteCalculoDias AS ( SELECT DATEDIFF( day, (SELECT MIN(FechaEncuesta) FROM Poblacion), (SELECT MAX(FechaEncuesta) FROM Poblacion) ) AS NumDias ) ,cteFechas AS ( SELECT NumeroID, DATEADD(day,NumeroID,(SELECT MIN(FechaEncuesta) FROM Poblacion)) as Fecha FROM Numeros WHERE NumeroID BETWEEN 0 AND (SELECT NumDias FROM cteCalculoDias) ) INSERT INTO Fechas ( FechaID, Fecha, AnualidadID, Anualidad, MesID, MesNombre, DiaID, Dia ) SELECT Fecha, FORMAT(Fecha,'dd/MM/yyyy'), YEAR(Fecha), FORMAT(Fecha,'yyyy'), MONTH(Fecha), DATENAME(month,Fecha), DAY(Fecha), CONVERT(varchar(2),DAY(Fecha)) FROM cteFechas;
De forma similar añadiremos las filas para la tabla Edad, donde también clasificaremos cada una de las edades por grupos, característica muy utilizada por los usuarios que realizan análisis de datos sanitarios. Los tipos de grupos pueden ser muy variados, y para este ejemplo organizaremos las edades en rangos de 10 años, excepto en el primer y último grupo, donde el intervalo de años será menor y mayor respectivamente.
INSERT INTO Edad (EdadID,Edad,GrupoEdad,Orden) SELECT NumeroID, CONVERT(varchar,NumeroID), CASE WHEN NumeroID BETWEEN 0 AND 4 THEN '0-4 años' WHEN NumeroID BETWEEN 5 AND 14 THEN '5-14 años' WHEN NumeroID BETWEEN 15 AND 24 THEN '15-24 años' WHEN NumeroID BETWEEN 25 AND 34 THEN '25-34 años' WHEN NumeroID BETWEEN 35 AND 44 THEN '35-44 años' WHEN NumeroID BETWEEN 45 AND 54 THEN '45-54 años' WHEN NumeroID BETWEEN 55 AND 64 THEN '55-64 años' WHEN NumeroID BETWEEN 65 AND 74 THEN '65-74 años' WHEN NumeroID BETWEEN 75 AND 84 THEN '75-84 años' WHEN NumeroID BETWEEN 85 AND 100 THEN '85-100 años' END, CASE WHEN NumeroID BETWEEN 0 AND 4 THEN 1 WHEN NumeroID BETWEEN 5 AND 14 THEN 2 WHEN NumeroID BETWEEN 15 AND 24 THEN 3 WHEN NumeroID BETWEEN 25 AND 34 THEN 4 WHEN NumeroID BETWEEN 35 AND 44 THEN 5 WHEN NumeroID BETWEEN 45 AND 54 THEN 6 WHEN NumeroID BETWEEN 55 AND 64 THEN 7 WHEN NumeroID BETWEEN 65 AND 74 THEN 8 WHEN NumeroID BETWEEN 75 AND 84 THEN 9 WHEN NumeroID BETWEEN 85 AND 100 THEN 10 END FROM Numeros WHERE NumeroID BETWEEN 0 AND 100;
La tabla Sexo la rellenaremos con una sentencia más simple.
INSERT INTO Sexo (SexoID,Sexo,Orden) VALUES ('H','Hombre',1), ('M','Mujer',2);
El modelo de análisis. Importación de datos
Tras la base de datos llega el momento de desarrollar el modelo de datos en PowerPivot, con el que analizaremos los resultados de participación de la encuesta.
En primer lugar, desde un nuevo archivo Excel 2013 o superior, nos situaremos en la pestaña POWERPIVOT y abriremos la ventana del mismo nombre mediante la opción Administrar del grupo Modelo de datos. Una vez situados en dicha ventana, en el grupo de opciones Obtener datos externos, abriremos la lista De base de datos y elegiremos la opción De SQL Server.
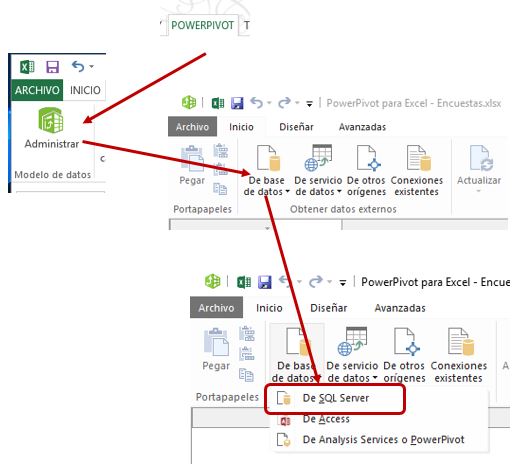
Aparecerá a continuación el asistente de importación, en el que introduciremos los datos de conexión contra el servidor SQL Server que contiene la base de datos Encuesta.
En el siguiente paso seleccionaremos como modo de importación la escritura de una consulta que especifique los datos a importar.

Y por último escribiremos la sentencia de importación.
SELECT EdadID, SexoID, FechaEncuesta FROM Poblacion;

Al aceptar este último paso, el asistente realizará el proceso de importación indicado en la sentencia, añadiendo el resultado en forma de nueva tabla en el modelo de datos de PowerPivot.
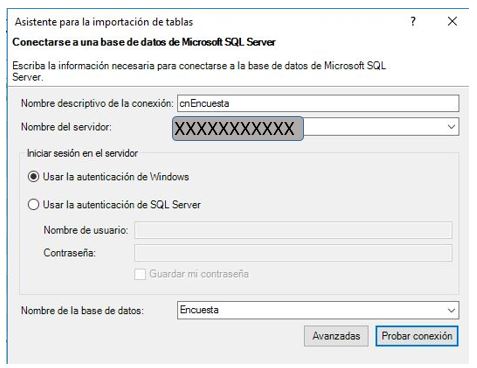
El motivo de excluir la columna LineaID en la operación de importación de la tabla Poblacion se debe a una cuestión de rendimiento explicada en [7]: se trata de una columna que no va a intervenir en los análisis que vamos a realizar sobre el modelo, y además actúa como identificador de fila, lo que significa un valor distinto en cada fila. Ello supondría un trabajo extra para el motor de PowerPivot, que no podría comprimir los datos en la forma adecuada, lo que implicaría una penalización en el trabajo con el modelo.
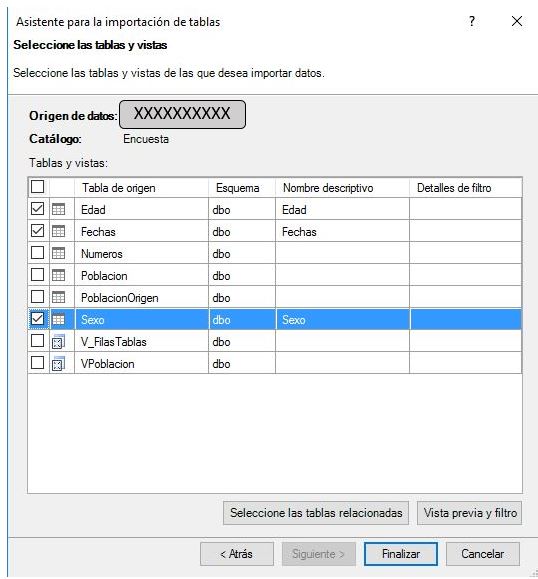
A continuación volveremos a usar este asistente para importar las demás tablas: Edad, Fechas y Sexo.
Relaciones entre tablas
Una vez incorporadas, identificaremos cada tabla por el rol analítico que desempeñan en el modelo: tabla de datos o tabla de búsqueda.
La tabla Poblacion será nuestra tabla de datos, ya que en ella crearemos, entre otras, las métricas para el cálculo de la cifra de población y porcentaje de participación. El resto de tablas del modelo serán las tablas de búsqueda, que relacionaremos con la tabla de datos (ver el siguiente diagrama) mediante sus columnas comunes, para poder analizar los resultados de las medidas por diversos criterios.
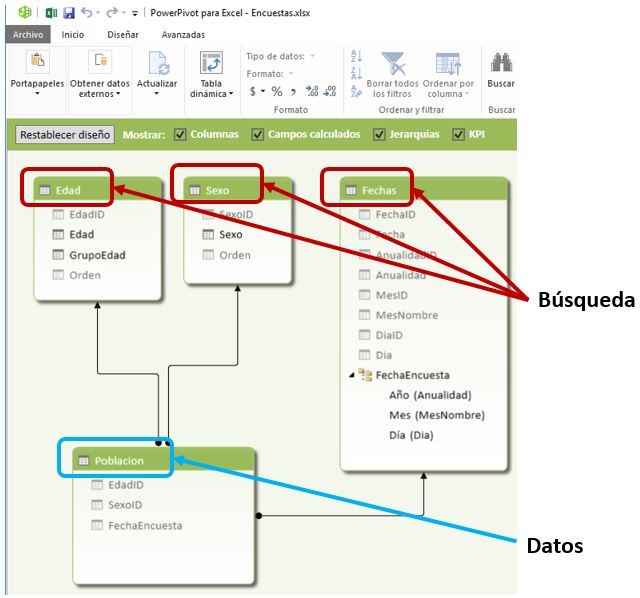
En la ventana de administración de relaciones se muestra con más detalle la información relativa a las relaciones creadas en el modelo. Esta ventana se encuentra accesible desde la ventana de PowerPivot, en el menú Diseñar, opción Administrar relaciones del grupo Relaciones.

Creando una jerarquía
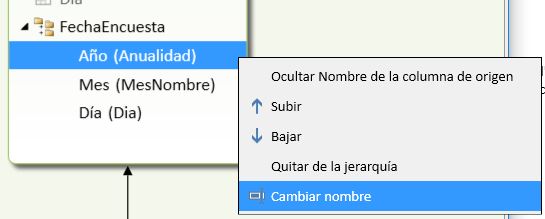
Dentro de un modelo de PowerPivot, las fechas representan un tipo de dato que permite ser tratado mediante una jerarquía, lo que facilita el análisis de la información a diferentes niveles de detalle, por lo que para crear una jerarquía en la tabla Fechas, en primer lugar cambiaremos la visualización del modelo a diagrama (menú Inicio, grupo Ver, opción Vista de diagrama) y haremos clic en el icono Crear jerarquía, situado en la parte superior derecha de la tabla, lo que añadirá la nueva jerarquía al final de la tabla, a la que daremos el nombre FechaEncuesta. A partir de aquí arrastraremos las columnas Anualidad, MesNombre y Dia a la jerarquía, como muestra la siguiente figura.

Como podemos apreciar, los nombres de los niveles de la jerarquía no tienen necesariamente que coincidir con los de las columnas de la tabla utilizadas para construirla. Haciendo clic derecho sobre cualquier nivel podemos cambiar su nombre mediante la opción Cambiar nombre.
Columnas de ordenación
Resulta fundamental establecer una correcta ordenación de los datos en las columnas que posteriormente vayamos a utilizar para analizar la información del modelo desde una tabla dinámica. Un claro ejemplo lo constituye la columna GrupoEdad, de la tabla Edad, que sin una ordenación previa, podría mostrarse de la forma que vemos en la siguiente figura.
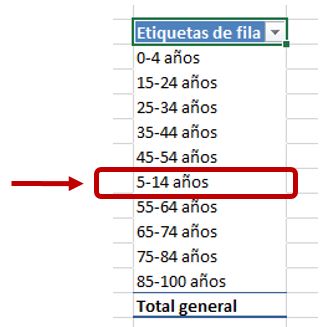
Por dicho motivo la tabla Edad dispone de la columna Orden, que aplicaremos de la siguiente manera: haremos clic en el título de la columna GrupoEdad; seleccionaremos la opción Ordenar por Columna del menú Inicio, grupo Ordenar y filtrar; en la ventana de ordenación que aparece a continuación elegiremos la columna que vamos a ordenar (GrupoEdad) y cuál va a ser la columna de ordenación (Orden).

El resto de columnas del modelo que precisan ordenación se detallan en la siguiente tabla.
| Tabla | Columna a ordenar | Columna de ordenación |
| Edad | Edad | EdadID |
| Fechas | Anualidad | AnualidadID |
| “ | MesNombre | MesID |
| “ | Dia | DiaID |
| Sexo | Sexo | Orden |
Ocultar columnas del modelo
En aquellas columnas no necesarias a efectos analíticos aplicaremos la opción Ocultar en herramientas cliente, disponible al hacer clic derecho en el título de la columna, de forma que no aparecerán cuando analicemos los datos desde una tabla dinámica, proporcionando un modelo menos recargado, dirigido a lo que el usuario necesite analizar.
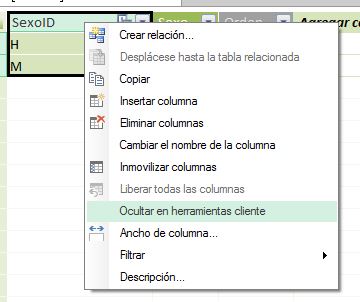
En la ventana de PowerPivot, las columnas ocultas se reconocen porque se muestran con un tono atenuado, tanto en vista de datos como de diagrama.
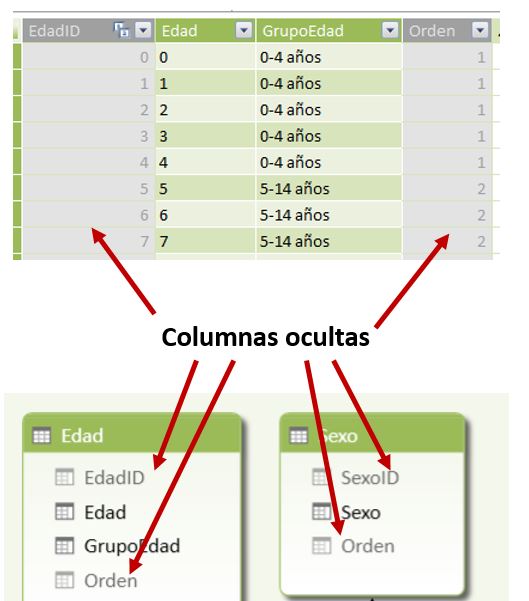
La siguiente tabla muestra el detalle de las columnas que ocultaremos del modelo, así como la tabla a la que pertenecen.
| Tabla | Columna oculta |
| Poblacion | EdadID |
| “ | SexoID |
| “ | FechaEncuesta |
| Edad | EdadID |
| “ | Orden |
| Fechas | FechaID |
| “ | Fecha |
| “ | AnualidadID |
| “ | Anualidad |
| “ | MesID |
| “ | MesNombre |
| “ | DiaID |
| “ | Dia |
| Sexo | SexoID |
| “ | Orden |
Calculando la población existente
Como primer dato imprescindible para analizar la evolución de la encuesta, tenemos que calcular la cifra total de la población diana a la que se tenía intención de entrevistar, o lo que es lo mismo, el número de registros de la tabla Poblacion. Esto lo conseguiremos mediante una medida con el nombre Poblacion, que crearemos desde la ventana de PowerPivot, escribiendo la siguiente expresión en lenguaje DAX en la zona de fórmulas de dicha ventana.
Poblacion := COUNTROWS ( Poblacion )
La función COUNTROWS de DAX, tal y como su nombre indica, realiza un recuento de las filas pertenecientes a la tabla que recibe como parámetro. Adicionalmente formatearemos la medida como número entero y con separador de miles.

Para observar los resultados que proporciona esta medida, desde la ventana de PowerPivot (menú Inicio, opción Tabla dinámica) añadiremos una tabla dinámica a la ventana de Excel, donde situaremos la medida como valores a analizar, y algunos campos de otras tablas del modelo en filas (GrupoEdad) y columnas (Sexo).
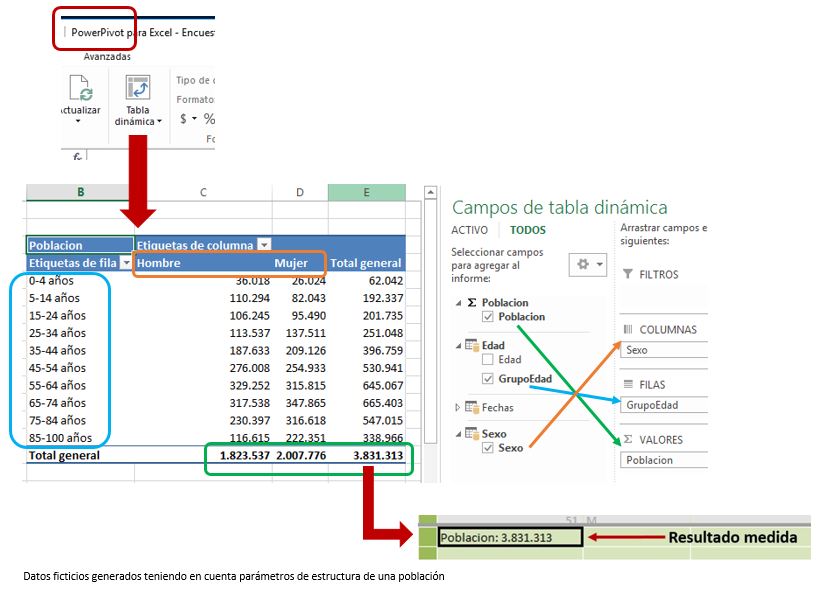
Población participante en la encuesta
La segunda medida básica a crear debe ser un recuento de la población a la que se ha conseguido encuestar, que en la tabla Poblacion del modelo de datos correspondería solamente a los registros que tienen valor en la columna FechaEncuesta. Con dicha finalidad crearemos la medida PoblacionEncuestada utilizando la siguiente expresión DAX.
PoblacionEncuestada := CALCULATE ( Poblacion[Poblacion], NOT ( ISBLANK ( Poblacion[FechaEncuesta] ) ) )
La función CALCULATE evalúa la expresión pasada como primer parámetro, modificando su contexto de evaluación ([8], [9], [10]) original mediante el uso de expresiones de filtro situadas en el segundo y sucesivos parámetros. Trasladando estas condiciones al problema que debemos resolver, en el primer parámetro situaremos la medida Poblacion creada anteriormente, mientras que en el segundo parámetro utilizaremos una expresión de filtro, que seleccionará los registros de la tabla Poblacion cuyo valor en la columna FechaEncuesta (Poblacion[FechaEncuesta]) no (función NOT) sea vacío (función ISBLANK); o dicho de otro modo, en la medida PoblacionEncuestada reutilizamos la medida Poblacion, para contar solamente las personas que sí han realizado la encuesta mediante los filtros aplicados.
Ahora añadiremos esta nueva medida a la tabla dinámica que estamos empleando para nuestras pruebas, quitando el campo Sexo de las columnas para simplificar la vista de los datos. Nótese cómo las cifras de población encuestada son inferiores a las de población general.
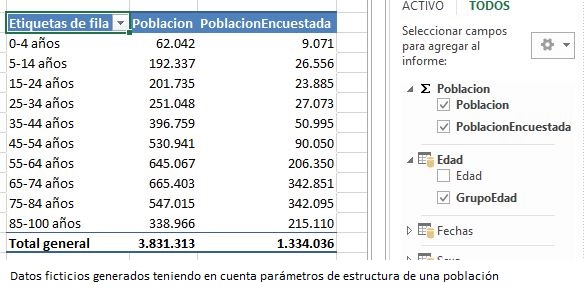
Porcentaje de participación en la encuesta
La siguiente medida consistirá en averiguar, en forma de porcentaje, el grado de participación en la encuesta de la población objetivo de la misma, para lo que utilizaremos la función DIVIDE, que como podemos adivinar, realiza una división entre los valores pasados como parámetro, los cuales en nuestro caso serán las medidas PoblacionEncuestada como numerador y Poblacion como denominador. La expresión a utilizar sería la siguiente.
Participacion := DIVIDE ( Poblacion[PoblacionEncuestada], Poblacion[Poblacion] )
Aplicando el formato de porcentaje a esta nueva medida, la incluiremos en la tabla dinámica para analizar los resultados de la encuesta por los grupos de edad.
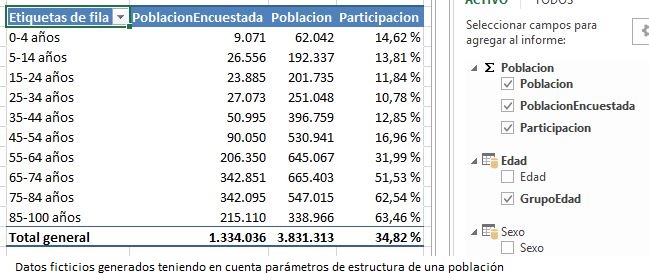
También es posible, como ya hemos visto anteriormente, emplear más de un campo para analizar los valores de las medidas. En el siguiente caso hemos colocado el campo Sexo en filas, mientras que el campo Edad lo utilizamos como elemento de filtro, seleccionando un subconjunto de las etiquetas (edades) del mismo.

Incorporando la fecha de encuesta al análisis
A efectos de establecer un aumento gradual en la dificultad del análisis del modelo, hasta ahora hemos evitado el uso de la tabla Fechas dentro de la tabla dinámica, pero tras la creación de las medidas principales, ha llegado el momento de comenzar a analizar los datos desde la perspectiva temporal que aporta la mencionada tabla.
En primer lugar, desde la ventana de PowerPivot, nos situaremos en la tabla Fechas, y seleccionaremos la opción Marcar como tabla de fechas del menú Diseñar. Esto nos permitirá aprovechar características avanzadas de análisis sobre fechas en el modelo.
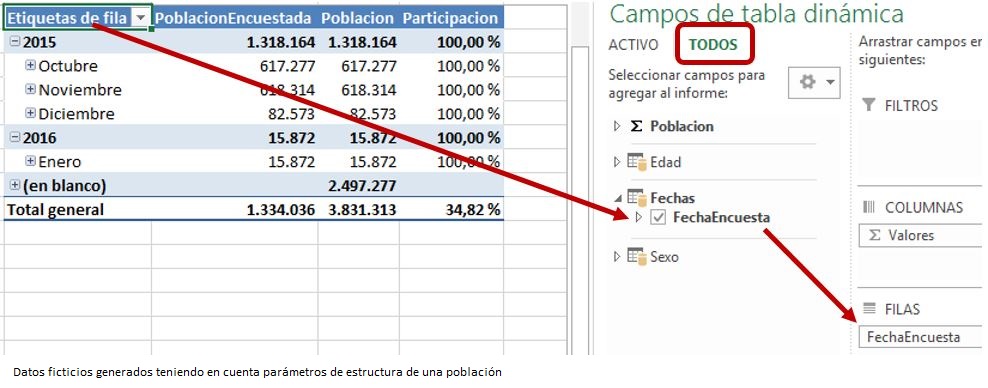
Situando el campo FechaEncuesta (jerarquía) en las filas de la tabla dinámica, observaremos que, a excepción de los totales y las fechas con la etiqueta “(en blanco)”, que corresponden a las filas de la tabla Poblacion sin fecha, los números de las medidas PoblacionEncuestada y Poblacion son iguales, puesto que en ambos casos apuntan a los mismos registros. Esto también tiene como resultado que el porcentaje de la medida Participacion siempre sea 100% (si la tabla Fechas no está visible, hacer clic en el elemento TODOS que hay en la parte superior del panel de campos).


Sin embargo, ahora que estamos utilizando las fechas para estudiar la información del modelo, sería más adecuado enfrentar la población encuestada con la población total empleada para el estudio. La medida Poblacion actual, cuya finalidad es proporcionar la cifra de toda la población (sin tener en cuenta que hayan realizado o no la encuesta), no responde, no obstante, a nuestras necesidades, ya que precisamos que en este escenario, la cifra de población sea siempre el total, independientemente del nivel de fecha de encuesta (Año, Mes o Día) que se esté analizando.
La solución a este problema pasa por alterar el contexto de filtro ([8], [9], [10]) mediante la función ALL, la cual ignora cualquier filtro sobre la tabla que recibe como parámetro, y como indica su nombre, devuelve todas las filas, en este caso, de la tabla Poblacion (más adelante explicaremos esta función con mayor detalle). Aplicando lo anterior a la función COUNTROWS dentro de una nueva medida conseguiremos nuestro objetivo de contar siempre todos los registros.
PoblacionTotalFija := COUNTROWS ( ALL ( Poblacion ) )
La actual medida Participacion consecuentemente no servirá para calcular el porcentaje de participación en la forma que ahora necesitamos, por lo que crearemos una nueva medida ParticipacionPobEncuestadaPobTotalFija usando la medida que acabamos de crear y PoblacionEncuestada.
ParticipacionPobEncuestadaPobTotalFija := DIVIDE ( Poblacion[PoblacionEncuestada], Poblacion[PoblacionTotalFija] )
El resultado con las nuevas medidas será la obtención del porcentaje de población que ha participado según el nivel al que hayamos desplegado el campo-jerarquía FechaEncuesta. En algunos casos, debido a que el valor de la población encuestada es muy pequeño, el porcentaje resultante se muestra como cero, aunque podemos añadir más precisión aumentando los decimales en la ventana de PowerPivot, dentro del grupo de opciones Formato.

Evolución temporal en el porcentaje de participación
Si bien el anterior cálculo funciona correctamente, el hecho de tener disponible el porcentaje de participación para un momento concreto en el tiempo (Año, Mes o Día) quizá no resulte tan relevante como la posibilidad de observar su progresión desde una perspectiva también temporal.
Por tal motivo, a continuación crearemos una nueva medida con el nombre PoblacionAcumulada, que al añadirse a la tabla dinámica, una vez situado en su área de filas el campo FechaEncuesta, realizará el recuento acumulado de la población conforme transcurren las fechas desde el comienzo del periodo de encuestas.
Para ello volveremos a combinar la función CALCULATE con la medida Poblacion, aplicando en esta ocasión como filtro la función DATESYTD.
PoblacionAcumulada := CALCULATE ( Poblacion[Poblacion], DATESYTD ( Fechas[FechaID] ) )
DATESYTD es una función incluida en la categoría Time Intelligence de DAX, y su misión consiste en devolver una tabla compuesta por una columna de fechas, que se evalúa por periodos anuales.
Dispone de un parámetro al que pasamos una columna de tipo fecha mediante diversas variantes: nuestro caso actual, que es la columna FechaID de la tabla Fechas; una expresión de tabla que devuelva una columna de fechas; o una expresión lógica que defina una tabla con una única columna de fechas.
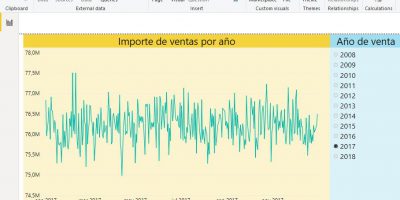
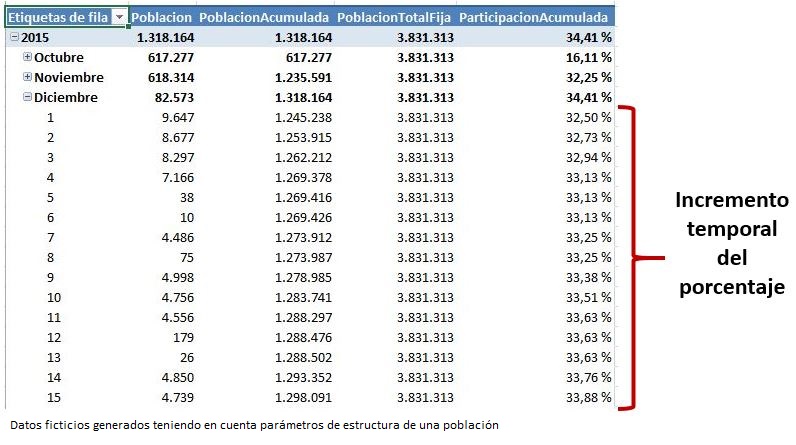
Como resultado de la aplicación de esta medida, la tabla dinámica generará los valores de forma acumulada tal y como muestra la siguiente figura.
Para obtener el porcentaje de participación en base a este cálculo acumulado, crearemos otra medida con la función DIVIDE, que use las medidas PoblacionAcumulada y PoblacionTotalFija como numerador y denominador.
ParticipacionAcumulada := DIVIDE ( Poblacion[PoblacionAcumulada], Poblacion[PoblacionTotalFija] )
El principal inconveniente en el uso de DATESYTD radica en que es una función que trabaja con periodos anuales, por lo que al revisar el resultado anterior comprobaremos que cuando termina un año, las medidas de acumulado se reinician.
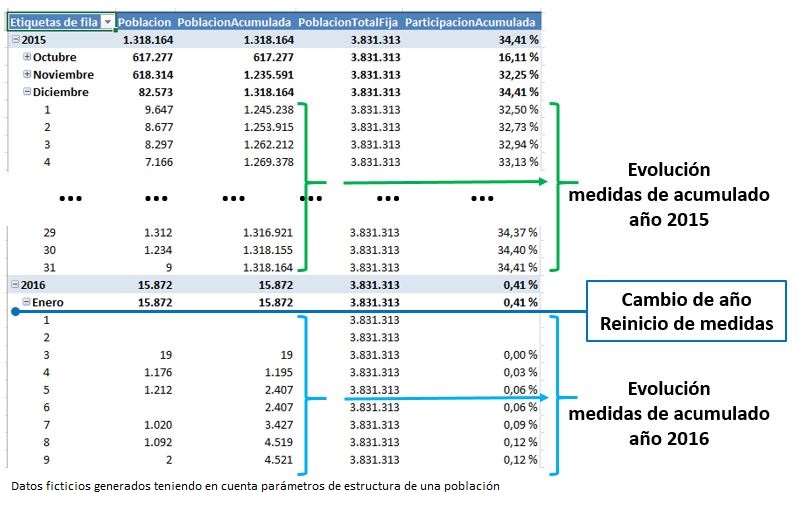
Si necesitamos analizar la participación durante todo el periodo de encuestas tendremos que hacer algunos ajustes adicionales a la medida que calcula la población para conseguir dicho objetivo.
Evolución del porcentaje de participación sobre el periodo temporal completo
Puesto que DATESYTD no se adapta completamente a nuestros requerimientos, hemos de elegir otra función que cumpla con el requisito de abarcar el periodo temporal completo que tenemos en el modelo de datos. Buscando de nuevo en la categoría Time Intelligence de la documentación sobre DAX hallaremos la función DATESBETWEEN, cuyo nombre nos proporciona una buena pista de lo que necesitamos: devuelve una tabla compuesta por una columna de fechas comprendidas en un rango, que aplicaremos a nuestro cálculo. Como primer parámetro pasaremos la columna FechaID de la tabla Fechas, mientras que en el segundo y tercer parámetro deberemos indicar las fechas inferior y superior del rango.
Para determinar la primera y última fecha a utilizar disponemos igualmente de sendas funciones: FIRSTDATE y LASTDATE, que devuelven respectivamente la primera y última fecha de la columna pasada como parámetro dentro del contexto de evaluación actual.
Con todos estos elementos reformularemos, o mejor, crearemos una medida nueva para calcular el recuento acumulado de población de forma continua sobre todas las fechas, sin tener en cuenta las divisiones anuales.
PoblacionAcumuladaContinua := CALCULATE ( Poblacion[Poblacion], DATESBETWEEN ( Fechas[FechaID], FIRSTDATE ( Fechas[FechaID] ), LASTDATE ( Fechas[FechaID] ) ) )
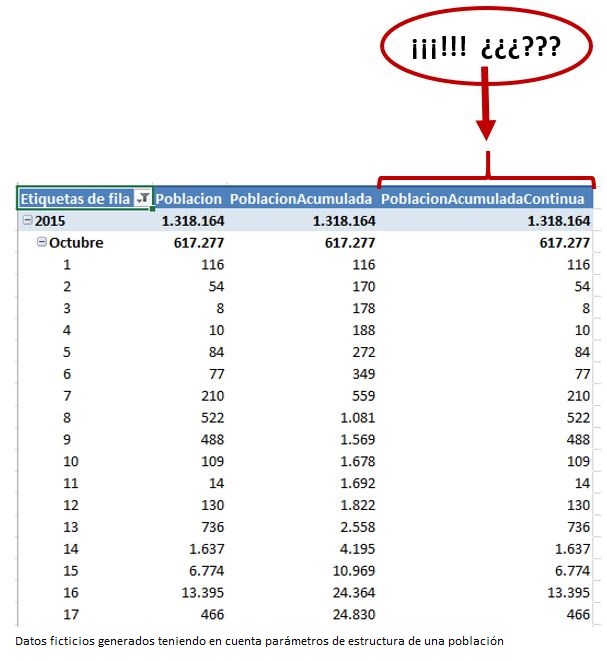
Para nuestra sorpresa el resultado no es el esperado, ya que la nueva medida PoblacionAcumuladaContinua no está haciendo el cálculo acumulado que necesitamos. Sin embargo, a pesar de que podamos estar teniendo la impresión de que hay un problema, la medida realmente está funcionando de forma correcta; ello es debido al contexto de evaluación.
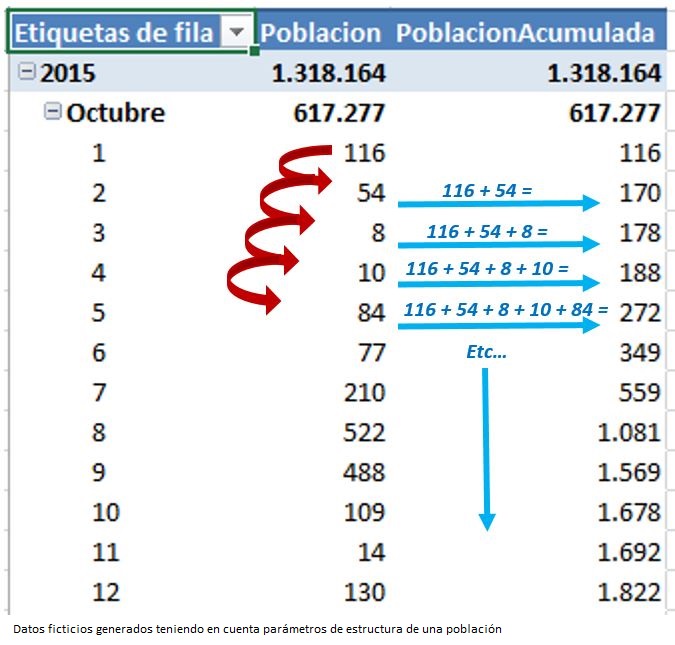
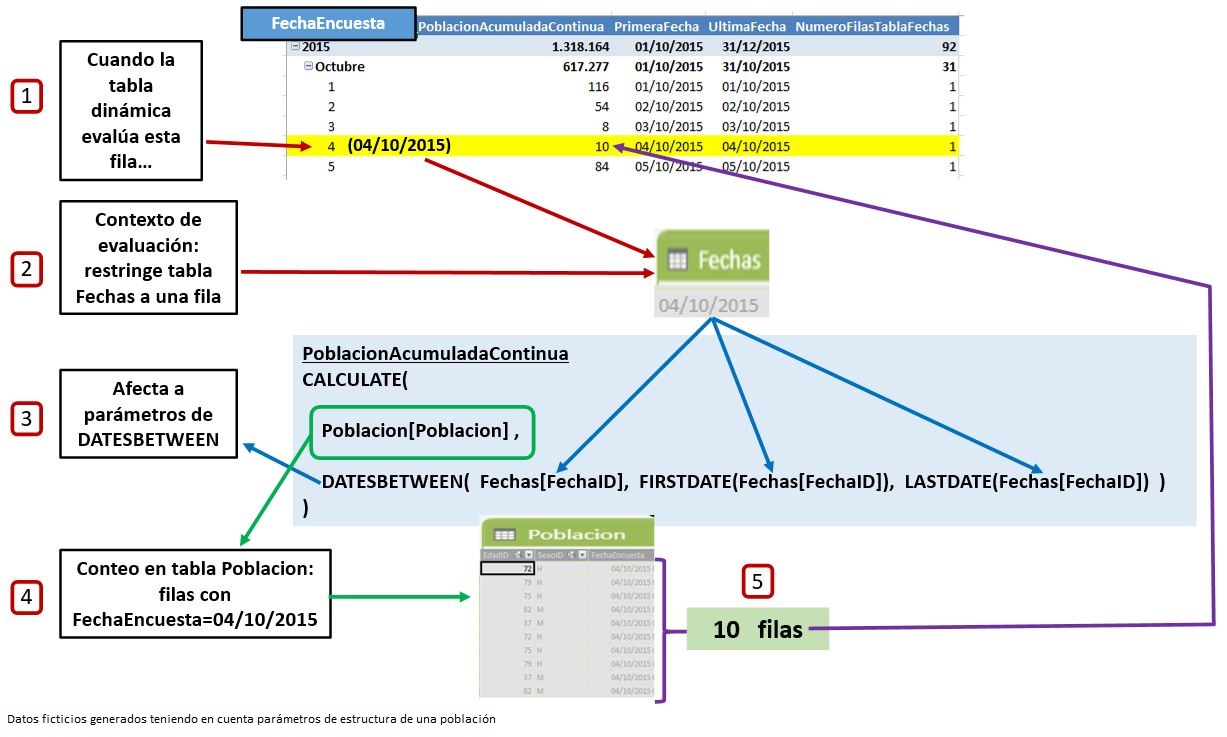
Antes de comenzar a diseccionar la medida para entender la mecánica de su funcionamiento, analicemos en primer lugar la conducta y resultados que esperaríamos de los datos con los que estamos trabajando. Para comprender mejor dichos resultados emplearemos un pequeño conjunto de datos, en concreto, los recuentos de población de las primeras fechas de encuesta, desde 01/10/2015 hasta 05/10/2015.
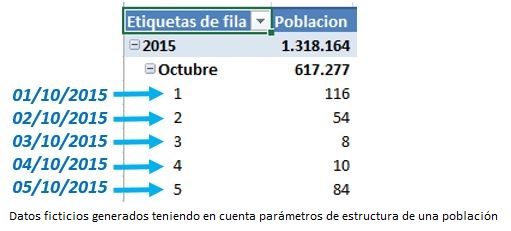
En la figura anterior vemos que en el día 01/10/2015 hay 116 personas que han participado en la encuesta, el día 02/10/2015 han sido 54 personas, y así sucesivamente.
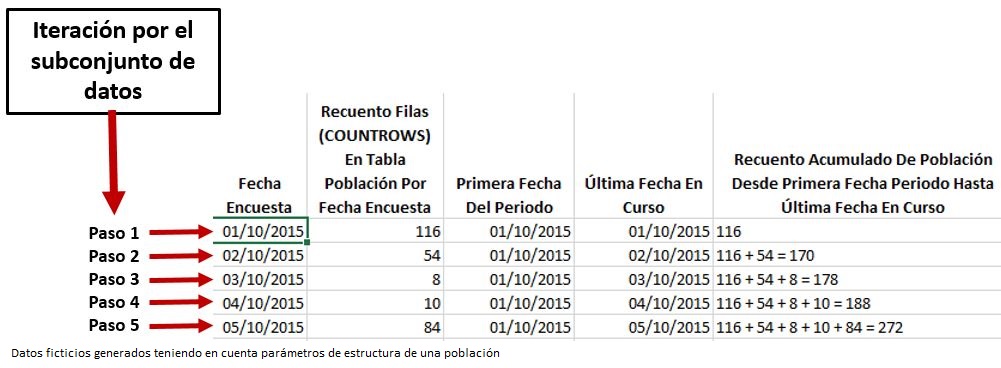
¿Qué cabría esperar de un procedimiento de acumulado para estos valores? Que el día 01/10/2015, al ser la fecha de inicio, el valor acumulado fuera de 116; el 02/10/2015, el acumulado sería 170 porque el rango de fechas desde 01/10/2015 hasta 02/10/2015 toma los valores 116 y 54; y así hasta llegar al último día de este subconjunto de datos, donde el rango de fechas va desde el 01/10/2015 hasta el 05/10/2015, con lo cual los valores que están en el intervalo son 116, 54, 8, 10 y 84, dando como resultado 272. La siguiente figura muestra la representación de estos pasos de un modo más esquemático.
Puesto que la medida PoblacionAcumuladaContinua no está funcionando de esta manera, podemos deducir que el intervalo de fechas utilizado en DATESBETWEEN, que obtenemos mediante FIRSTDATE y LASTDATE, no es el que cabría esperar. Por tal motivo vamos a observar por separado los valores que están devolviendo las funciones FIRSTDATE y LASTDATE, así como la cantidad de filas de la tabla Fechas que está manejando DATESBETWEEN. Para ello crearemos las siguientes medidas que añadiremos a la tabla dinámica.
PrimeraFecha := FIRSTDATE ( Fechas[FechaID] ) UltimaFecha := LASTDATE ( Fechas[FechaID] ) NumeroFilasTablaFechas := COUNTROWS ( Fechas )
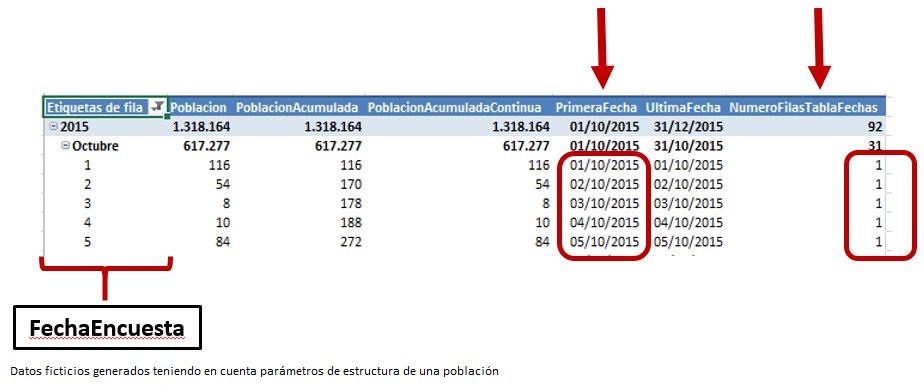
Desde nuestro punto de vista, el valor a utilizar como primera fecha en todas las filas debería ser 01/10/2015, sin embargo la función FIRSTDATE está devolviendo el valor del campo FechaEncuesta de la fila en curso, al igual que LASTDATE, por lo que en todas las filas se está utilizando un rango de tiempo compuesto por una única fecha: la correspondiente a la fila que se está evaluando. Este hecho también lo confirma la medida NumeroFilasTablaFechas devolviendo 1 en todas las filas.
El causante de este comportamiento, como hemos indicado anteriormente, es el contexto de evaluación de PowerPivot. Esta característica hace que en una tabla dinámica, la visibilidad de la información desde la celda de una medida quede restringida a las coordenadas de filtro existentes sobre dicha celda.
Para intentar aclarar este concepto tomemos como ejemplo la fila correspondiente a la fecha 04/10/2015 del subconjunto de datos que estamos analizando. Cuando el flujo de ejecución de la tabla dinámica debe generar la mencionada fila, la celda de la medida PoblacionAcumuladaContinua solo puede ”ver” en la tabla Fechas el valor 04/10/2015 (y no el rango entre 01/10/2015 y 04/10/2015), o lo que es lo mismo, a efectos de dicha celda, la tabla Fechas contiene un único registro con el valor 04/10/2015. Dentro de la medida esto afecta a los parámetros pasados a DATESBETWEEN, FIRSTDATE y LASTDATE, que reciben una tabla compuesta por una sola fila; así el primer parámetro de CALCULATE (la medida Poblacion[Poblacion]) hace un recuento de filas de la tabla Poblacion en las que la columna FechaEncuesta es igual a 04/10/2015, obteniendo 10 como resultado. La siguiente figura muestra un diagrama de los pasos de este proceso.
¿Qué debemos hacer para lograr que la fecha 01/10/2015 sea utilizada como primer día del rango en todos los casos para el cálculo de DATESBETWEEN? La respuesta está en alterar el contexto de evaluación predeterminado, lo que en este caso particular conseguimos mediante la función ALL. Veamos primeramente esta función de un modo práctico aplicada a FIRSTDATE en una medida.
PrimeraFechaAll := FIRSTDATE ( ALL ( Fechas[FechaID] ) )
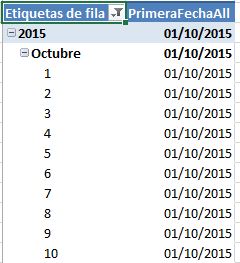
ALL es una función que devuelve todas las filas de una tabla o valores de una columna (depende lo que pasemos como parámetro) ignorando los filtros que en ese momento estén establecidos en la tabla dinámica. Con ello modificamos el contexto de evaluación, por lo que en nuestro ejemplo, la función FIRSTDATE, en lugar de recibir la tabla Fechas con un único registro, recibe dicha tabla en su totalidad para cada evaluación de fila de la tabla dinámica. De esa forma, FIRSTDATE ahora puede “llegar“ a la primera fila real de la tabla Fechas: 01/10/2015.
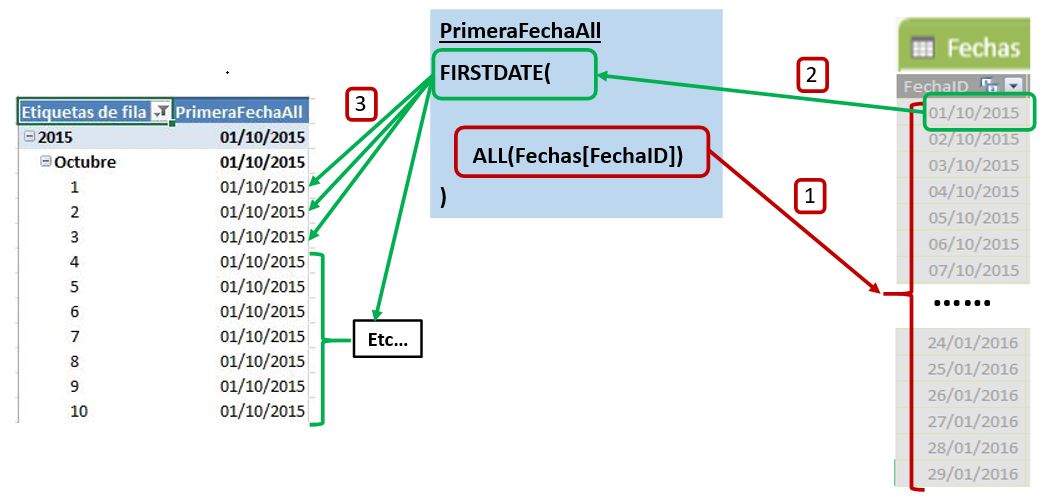
Vamos a crear una nueva versión de la medida PoblacionAcumuladaContinua a la que llamaremos PoblacionAcumuladaContinuaAll introduciendo este cambio.
PoblacionAcumuladaContinuaAll := CALCULATE ( [Poblacion], DATESBETWEEN ( Fechas[FechaID], FIRSTDATE ( ALL ( Fechas[FechaID] ) ), LASTDATE ( Fechas[FechaID] ) ) )
Ahora el recuento acumulado funcionará de la forma en que nos habíamos propuesto, continuando el acumulado al cambiar también el año.

A continuación crearemos la medida que usaremos para calcular el porcentaje de participación a lo largo del periodo de realización de las encuestas.
ParticipacionAcumuladaContinua := DIVIDE ( Poblacion[PoblacionAcumuladaContinuaAll], Poblacion[PoblacionTotalFija] )
Situando todos los elementos necesarios en la tabla dinámica, y aplicando también un filtro al campo FechaEncuesta para que no se muestren los datos de las etiquetas “(en blanco)”, obtendremos como resultado que un 34,82 % de la población objeto del estudio ha realizado la encuesta.
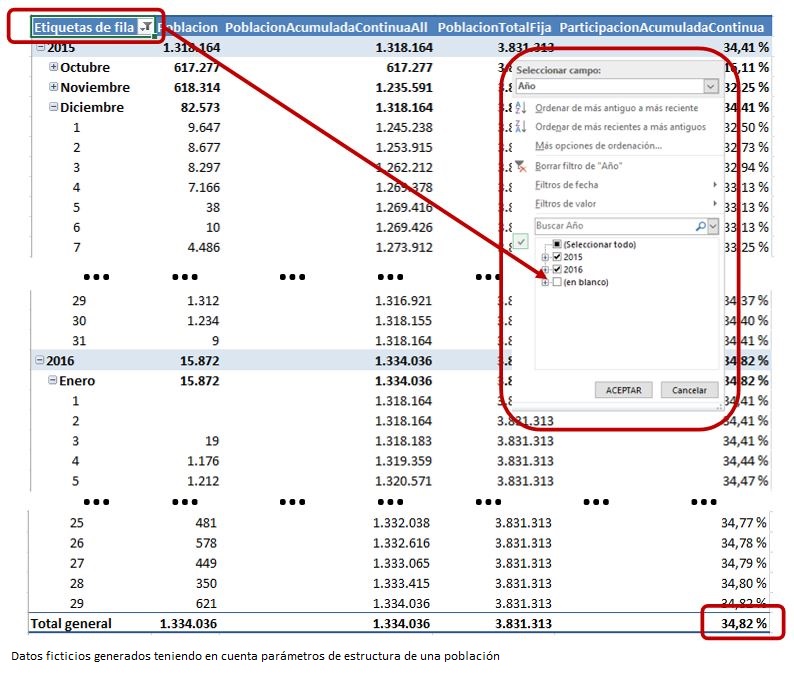
Porcentaje de participación por fecha y sexo. Una vuelta más de tuerca al contexto de evaluación
Si bien ya hemos cumplido nuestro objetivo principal: calcular el porcentaje de participación de la población en la encuesta durante sus fechas de realización, vamos a someter al motor de PowerPivot a otra pequeña prueba, añadiendo a la tabla dinámica el campo Sexo en el área de columnas como elemento adicional de análisis sobre el modelo de datos. Observemos los resultados en la siguiente figura.
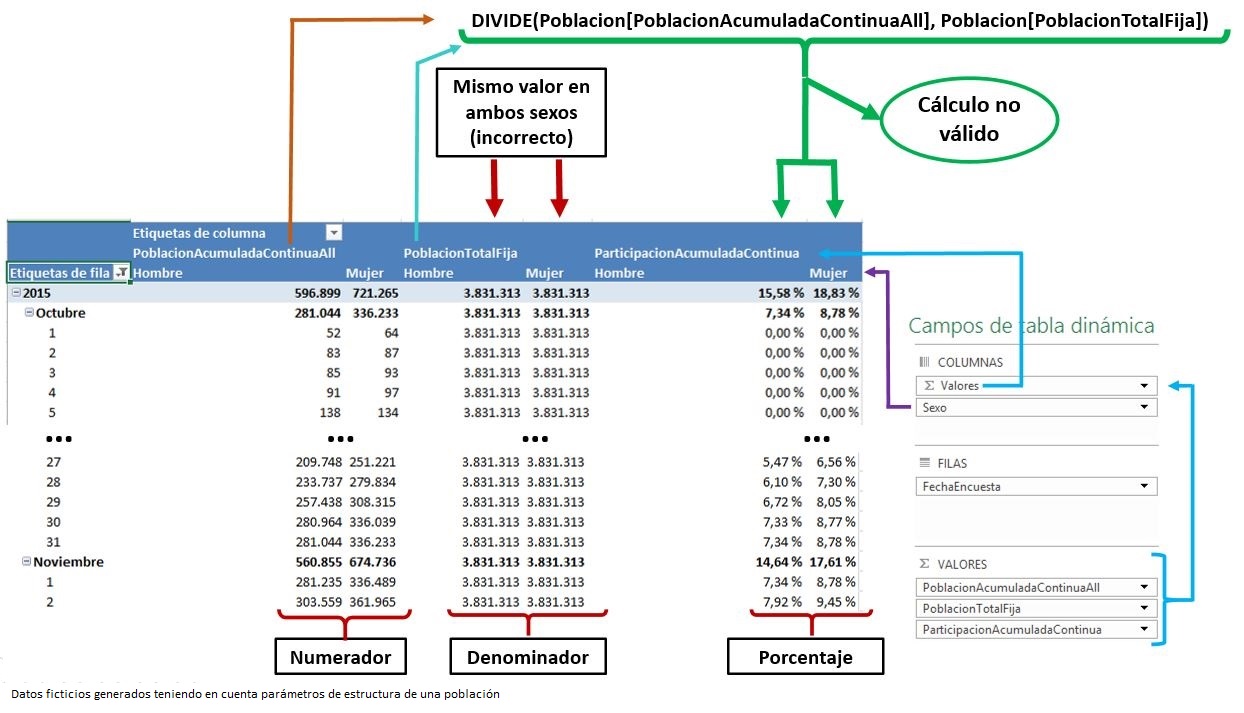
Examinando los resultados comprobaremos que la medida PoblacionTotalFija, que hasta ahora ha servido adecuadamente como denominador de población para calcular el porcentaje de participación, no resulta válida dentro de este nuevo escenario, ya que devuelve el mismo total global de población para ambos valores del campo Sexo. Lo que necesitamos es una medida que calcule el total de población de hombres por una parte, y de mujeres por otra. En definitiva, volvemos a encontrarnos con una situación que requiere la modificación del contexto de evaluación predeterminado de PowerPivot.
Los totales por el campo Sexo que acabamos de mencionar podemos obtenerlos en una tabla dinámica que contenga la medida Poblacion y el campo Sexo.

Pero en cuanto añadimos el campo FechaEncuesta en el área de filas introducimos un nuevo factor de filtro que tiene como resultado un nuevo cálculo de la medida, y donde antes solamente había un campo de coordenada de filtro: Sexo, ahora también tenemos FechaEncuesta, por lo que la medida debe mostrar sus valores para cada celda de la tabla dinámica con un filtro combinado de ambos campos.
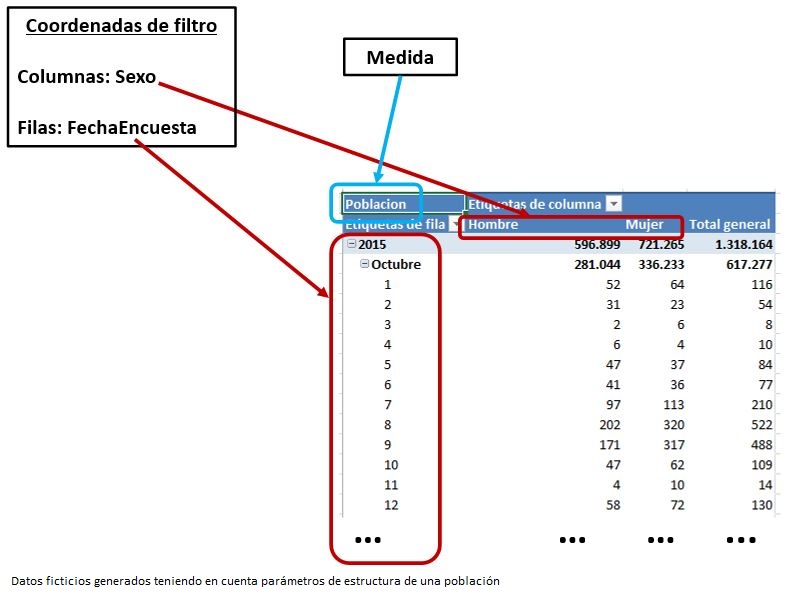
Sin embargo la finalidad que perseguimos consiste en mostrar las fechas de encuesta en las filas pero con los valores totales de cada sexo en todas las celdas. Para conseguir estos resultados debemos desactivar el filtro actual que la tabla Fechas ejerce sobre las filas de la tabla dinámica debido al campo FechaEncuesta ¿Y cómo habíamos conseguido en un ejemplo anterior anular la acción de filtro de un campo? Mediante la función ALL, que aplicaremos sobre la tabla Fechas en una nueva medida con la siguiente expresión DAX.
PoblacionTotalSinFiltroFechas := CALCULATE ( Poblacion[Poblacion], ALL ( Fechas ) )

Al anular el filtro de la tabla fechas con ALL la medida Poblacion cuenta las filas de la tabla del mismo nombre en función del campo Sexo, que es el único que queda activo.
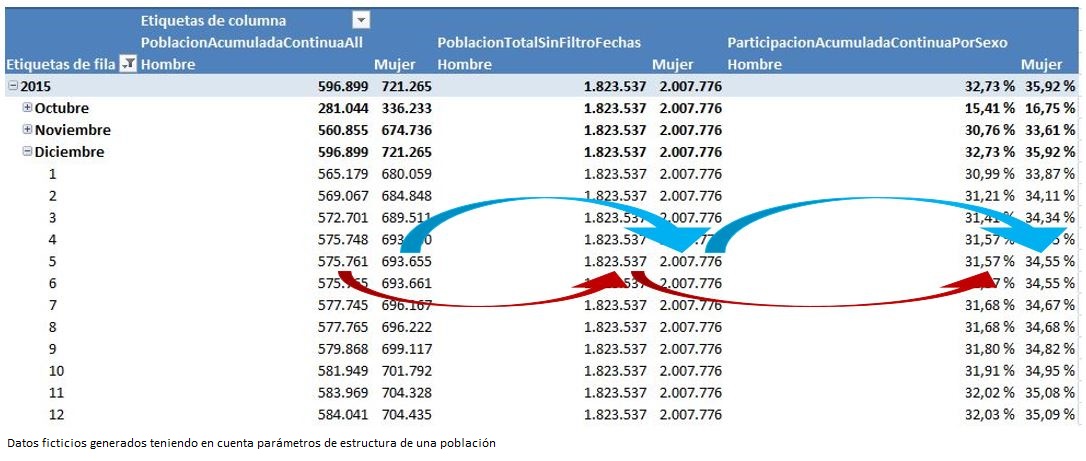
Con esta última medida recién creada y PoblacionAcumuladaContinuaAll ahora sí podemos implementar una medida de porcentaje que calcule correctamente la participación acumulada por sexo de la encuesta.
ParticipacionAcumuladaContinuaPorSexo := DIVIDE ( Poblacion[PoblacionAcumuladaContinuaAll], Poblacion[PoblacionTotalSinFiltroFechas] )
Conclusiones
A lo largo del presente artículo hemos explicado el procedimiento de creación de un sistema BI circunscrito al entorno sanitario con SQL Server 2016 y PowerPivot combinado con expresiones DAX como herramientas de desarrollo. El objetivo perseguido ha sido ofrecer al usuario las métricas necesarias para analizar los resultados de un proceso de encuesta sobre una supuesta población, con el objetivo de obtener los indicadores de alcance poblacional y porcentaje de participación. Esperamos que los pasos dados en su elaboración resulten de utilidad al lector.
Referencias
[1] Generar datos de prueba para SQL Server desde Excel. Operaciones en Excel (1): http://geeks.ms/lmblanco/2011/04/26/generar-datos-de-prueba-para-sql-server-desde-excel-operaciones-en-excel-1/
[2] Generar datos de prueba para SQL Server desde Excel. El traspaso a SQL Server (y 2): http://geeks.ms/lmblanco/2011/04/28/generar-datos-de-prueba-para-sql-server-desde-excel-el-traspaso-a-sql-server-y-2/
[3] Generación de datos demográficos desde SQL Server: http://geeks.ms/lmblanco/2011/07/18/generacin-de-datos-demogrficos-desde-sql-server/
[4] Different ways to get random data for SQL Server data sampling: https://www.mssqltips.com/sqlservertip/3157/different-ways-to-get-random-data-for-sql-server-data-sampling/
[5] Generatedata.com: http://www.generatedata.com
[6] Tablas numéricas auxiliares (Tally Tables) en acción. Tablas de dimensión para cubos OLAP: http://geeks.ms/lmblanco/2014/12/02/tablas-numricas-auxiliares-tally-tables-en-accin-tablas-de-dimensin-para-cubos-olap/
[7] Introducción al desarrollo y optimización de modelos de datos en PowerPivot: http://geeks.ms/lmblanco/2016/04/21/introduccion-al-desarrollo-y-optimizacion-de-modelos-de-datos-en-powerpivot/
[8] Context in DAX Formulas: https://msdn.microsoft.com/en-us/library/gg413423(v=sql.110).aspx
[9] Row Context and Filter Context in DAX: https://www.sqlbi.com/articles/row-context-and-filter-context-in-dax/
[10] Understanding Evaluation Contexts in DAX: https://www.microsoftpressstore.com/articles/article.aspx?p=2449191


Deja un comentario