
En la anterior entrega de este monográfico sobre creación de fechas aleatorias, expusimos la primera de una serie de técnicas para el cálculo aleatorio y asignación de fechas sobre un conjunto de datos de gran volumen, siendo este el planteamiento sobre el que seguiremos profundizando en el presente artículo.
Otras técnicas de distribución de datos aleatorios
Las fechas generadas en el artículo anterior presentan una distribución completamente aleatoria de los datos, con la única salvedad de que obligamos a que el año de la fecha sea siempre el mismo.
No obstante, puede haber situaciones en las cuales nos interese alterar dicha aleatoriedad, para dar a los datos una forma determinada, como es lógico, dentro de la propia naturaleza aleatoria del proceso. Y es precisamente aquí donde podemos aplicar alguno de los algoritmos expuestos por Dwain Camps, entre los que hemos seleccionado para nuestras pruebas las distribuciones Gaussian, que trataremos en el presente artículo, y Weibull, que veremos en el próximo.
Distribución Gaussian
Gaussian es una distribución cuya implementación como función en SQL Server precisa los parámetros de media y desviación estándar de los números que están en el intervalo, además de dos números aleatorios, todos ellos de tipo float.
El cálculo de la media y la desviación estándar lo efectuaremos mediante el siguiente bloque de código.
WITH cteDatos AS ( SELECT TOP (365) -- o también 366 ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS Numero FROM sys.all_columns AS col1 CROSS JOIN sys.all_columns AS col2 ) SELECT AVG(numero) AS Media, STDEV(numero) AS DesviacionEstandar FROM cteDatos; Media DesviacionEstandar ------------------ ---------------------- 183 105,510662968252 -- usando TOP (365) 183 105,799338372222 -- usando TOP (366)
La función original que encontramos en el artículo de referencia antes mencionado devuelve un número float positivo o negativo, pero el ejemplo que estamos desarrollando precisa de un int, lo que nos obligará a adaptar el código que realiza el cálculo para pasar el resultado a positivo, redondear decimales y hacer una conversión a int.
CREATE FUNCTION fnAleatorioGaussian( @nMedia float, @nDesviacionEstandar float, @nAleatorio1 float, @nAleatorio2 float ) RETURNS int AS BEGIN RETURN FLOOR( ABS( ( @nDesviacionEstandar * SQRT(-2 * LOG(@nAleatorio1)) * COS(2 * ACOS(-1.) * @nAleatorio2) ) + @nMedia ) ) END
A continuación, volveremos a ejecutar el código que realiza la carga de datos en la tabla INEPadron, haciendo ahora una llamada a la función fnAleatorioGaussian, para el cálculo del número aleatorio y la obtención de la fecha. Puesto que los números aleatorios que necesita esta función como parámetro deben ser float, utilizaremos RAND para generarlos.
DECLARE @dtFechaInicio AS date; DECLARE @dtFechaFin AS date; DECLARE @nNumDiasAnualidad AS int; DECLARE @nMedia AS float; DECLARE @nDesviacionEstandar AS float; SET @dtFechaInicio = '2017'; SET @dtFechaFin = EOMONTH(@dtFechaInicio,11); SET @nNumDiasAnualidad = DATEDIFF(day,@dtFechaInicio,@dtFechaFin) + 1; WITH cteDatos AS ( SELECT TOP (@nNumDiasAnualidad) ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS Numero FROM sys.all_columns AS col1 CROSS JOIN sys.all_columns AS col2 ) SELECT @nMedia = AVG(Numero), @nDesviacionEstandar = STDEV(Numero) FROM cteDatos; TRUNCATE TABLE INEPadron; INSERT INTO INEPadron WITH (TABLOCK) ( ProvinciaResidenciaID, MunicipioResidenciaID, SexoID, ProvinciaNacimientoID, MunicipioPaisNacimientoID, NacionalidadID, Edad, TamMunicipioResidenciaID, TamMunicipioNacimientoID, Fecha ) SELECT SUBSTRING(Datos,1,2), SUBSTRING(Datos,1,2) + IIF( LEN(SUBSTRING(Datos,3,3)) = 0, '999', SUBSTRING(Datos,3,3) ), CONVERT(int,SUBSTRING(Datos,6,1)), SUBSTRING(Datos,7,2), SUBSTRING(Datos,7,2) + IIF( LEN(SUBSTRING(Datos,9,3)) = 0, '999', SUBSTRING(Datos,9,3) ), SUBSTRING(Datos,12,3), CONVERT(int,SUBSTRING(Datos,15,3)), SUBSTRING(Datos,18,2), SUBSTRING(Datos,20,2), CONVERT( date, DATEADD( day, dbo.fnAleatorioGaussian( @nMedia, @nDesviacionEstandar, RAND(CHECKSUM(NEWID())), RAND(CHECKSUM(NEWID())) ) % @nNumDiasAnualidad, @dtFechaInicio ) ) FROM INEPadronOrigen;
En esta ocasión, los tiempos de ejecución del código habrán aumentado considerablemente, pasando a tardar 14 minutos frente a los 41 segundos de la propuesta anterior. Dicho incremento es debido a la naturaleza escalar (scalar function) de la función fnAleatorioGaussian.
Una posible mejora en el rendimiento de este proceso consiste en crear la función como tipo tabla (table-valued function).
CREATE FUNCTION fnAleatorioGaussianTbl( @nMedia float, @nDesviacionEstandar float, @nAleatorio1 float, @nAleatorio2 float ) RETURNS TABLE AS RETURN ( SELECT CONVERT( int, FLOOR( ABS( ( @nDesviacionEstandar * SQRT(-2 * LOG(@nAleatorio1)) * COS(2 * ACOS(-1.) * @nAleatorio2) ) + @nMedia ) ) ) AS Aleatorio )
Dentro del código de carga de datos y generación de fechas aleatorias invocaremos a esta función usando el operador CROSS APPLY en la forma que vemos a continuación. Con esta técnica conseguiremos reducir el tiempo de ejecución a 1 minuto.
DECLARE @dtFechaInicio AS date; DECLARE @dtFechaFin AS date; DECLARE @nNumDiasAnualidad AS int; DECLARE @nMedia AS float; DECLARE @nDesviacionEstandar AS float; ...... ...... TRUNCATE TABLE INEPadron; INSERT INTO INEPadron WITH (TABLOCK) ( ProvinciaResidenciaID, MunicipioResidenciaID, SexoID, ProvinciaNacimientoID, MunicipioPaisNacimientoID, NacionalidadID, Edad, TamMunicipioResidenciaID, TamMunicipioNacimientoID, Fecha ) SELECT SUBSTRING(Datos,1,2), SUBSTRING(Datos,1,2) + IIF( LEN(SUBSTRING(Datos,3,3)) = 0, '999', SUBSTRING(Datos,3,3) ), CONVERT(int,SUBSTRING(Datos,6,1)), SUBSTRING(Datos,7,2), SUBSTRING(Datos,7,2) + IIF( LEN(SUBSTRING(Datos,9,3)) = 0, '999', SUBSTRING(Datos,9,3) ), SUBSTRING(Datos,12,3), CONVERT(int,SUBSTRING(Datos,15,3)), SUBSTRING(Datos,18,2), SUBSTRING(Datos,20,2), CONVERT( date, DATEADD( day, ag.Aleatorio % @nNumDiasAnualidad, @dtFechaInicio ) ) FROM INEPadronOrigen CROSS APPLY dbo.fnAleatorioGaussianTbl( @nMedia, @nDesviacionEstandar, RAND(CHECKSUM(NEWID())), RAND(CHECKSUM(NEWID())) ) AS ag;
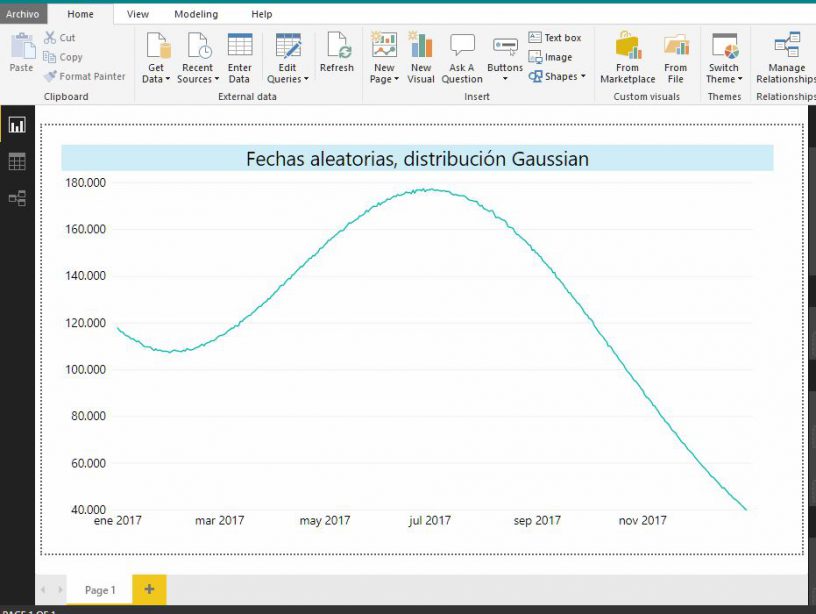
Tomando estos nuevos datos, volveremos a crear un modelo en Power BI, con un gráfico de línea basado en la columna de fecha. En esta ocasión, la línea dibujada por el gráfico tendrá una forma muy distinta de la obtenida en el gráfico de las fechas aleatorias generadas anteriormente mediante la combinación de NEWID, CHECKSUM y ABS.
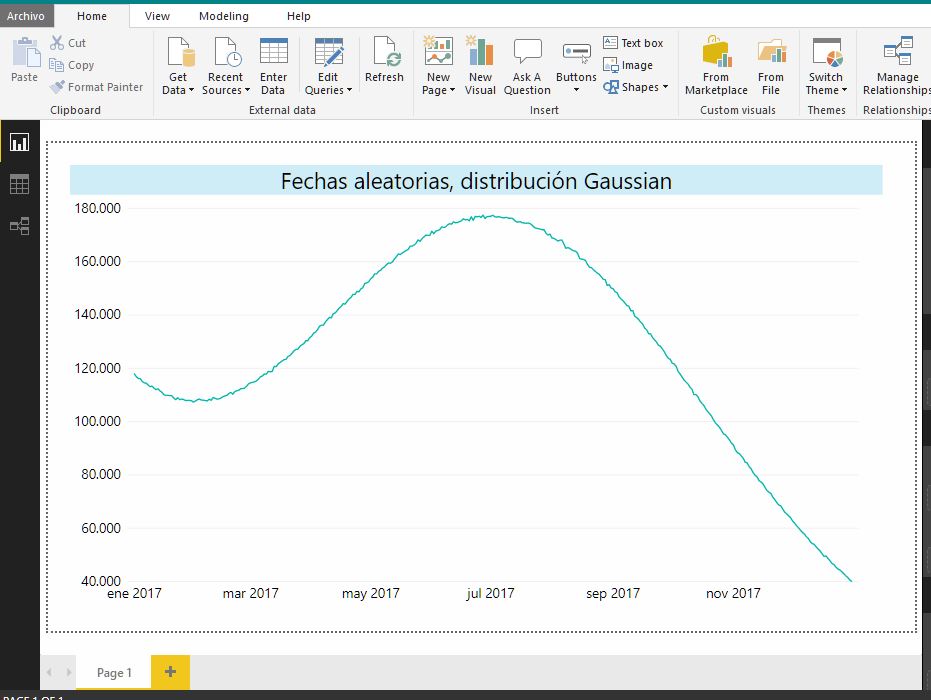
Si comparamos este resultado con el enlace existente en Wikipedia acerca de esta distribución, observaremos que la gráfica de nuestro ejemplo describe una curva con una tendencia algo más parecida a la distribución estándar (línea roja de la siguiente figura).

Conclusiones
En esta segunda entrega sobre generación de fechas, hemos aplicado un algoritmo de cálculo aleatorio de números basado en la distribución Gaussian o normal, con el que hemos conseguido que las fechas obtenidas se distribuyan de una forma muy distinta, comparadas con los resultados conseguidos utilizando la técnica del primer artículo.
Referencias
Dwain Camps: http://www.sqlservercentral.com/articles/SQL+Uniform+Random+Numbers/91103/
Normal distribution (Wikipedia): https://en.wikipedia.org/wiki/Normal_distribution
Documentación SQL Server 2016: https://docs.microsoft.com/en-us/sql/index?view=sql-server-2016
INE (Instituto Nacional de Estadística): http://www.ine.es/
DAX Guide: https://dax.guide/


Deja un comentario