Una de las preguntas más frecuentes que me hacen sobre contenedores es hasta que punto penalizan el rendimiento. Es una pregunta muy lógica ya que al final los contenedores ofrecen un cierto nivel de aislamiento, parecen máquinas virtuales… Algo han de penalizar, ¿no?. En esta entrada voy a hablar de los runtimes de contenedores, para que entendamos un poco más qué significa ejecutar un contenedor.
Docker
Es casi inevitable hablar de Docker si hablamos de contenedores, aunque en este caso sea para decir que docker no es un runtime de contenedores. Eso puede chocarte, ya que generalmente instalamos Docker para ejecutar contenedores, pero las cosas no son tan sencillas. Cuando salió Docker, era un sistema monolítico que realizaba tareas que realmente eran indendientes entre ellas:
- Creación de imágenes (docker build)
- Gestión de imágenes y de contenedores
- Compartición de imagenes (usando registros)
- Ejecución de contenedores
- Un formato de imagen
Observa que si nos ponemos todos de acuerdo en el último punto (formato de imagen) el resto de puntos son realmente independientes entre ellos y pueden ser ejecutados por herramientas distintas del mismo fabricante o de fabricantes distintos. Y precisamente eso nos lleva a la…
OCI
OCI son las siglas de Open Container Initiative y precisamente su objetivo ha sido definir un formato de imagen unificado. En OCI participan, entre otros, Docker, Google y CoreOS. Posteriormente Docker «separó» su código para ejecutar contenedores y lo donó a la OCI. De eso salió una librería llamada:
runC
Ahora sí que ya estamos hablando de un runtime de contenedores. runC es una pequeña utilidad que se encarga precisamente de eso: ejecutar un contenedor. En el fondo runC es un wrapper que ofrece una interfaz CLI por encima de libcontainer, la librería que usaba Docker para ejecutar los contenedores. Esa librería (libcontainer) es la encargada de usar los elementos del kernel de Linux que dan soporte a los contenedores (como namespaces y cgroups). Gracias a runC podemos ejecutar contenedores directamente, sin pasar por el engine de Docker. Como puedes ver, efectivamente, se trata de una CLI:

Docker ya hace unas cuantas versiones (desde 1.11) que usa internamente runC para ejecutar los contenedores.
containerd
Vale, tenemos por un lado a runC que se encarga de ejecutar contenedores. Pero una cosa es limitarse a ejecutar un contenedor y otra es manejar todo el ciclo de vida de éste, incluyendo la descarga de imágenes, el uso de volúmenes y el networking apropiado. Todo eso queda fuera del alcance de runC y necesitamos a alguien por encima que lo haga. Este alguien es containerd. Como podemos definir a containerd? Pues podemos decir que containerd es un runtime de contenedores de alto nivel, en contraposición a runC que es un runtime de contenedores de bajo nivel. De hecho, containerd usa runC para ejecutar los contenedores y le dota de toda esa funcionalidad adicional.
¿Recuerdas que antes he dicho que Docker 1.11+ usaba runC para ejecutar contenedores? Bien, lo hace, pero indirectamente a través de containerd.
Para Docker tener separados el motor de ejecución de contenedores y su engine permite, entre otras cosas, actualizar el engine sin tener que parar contenedores.
rkt
Cuando hablé de OCI comenté que precisamente si estandarizábamos el formato de imagen, distintas herramientas de distintos fabricantes podían realizar distintas tareas. Para ejecutar contenedores tenemos a runC que viene del «lado de Docker». Pues bien rkt es un equivalente a runC y containerd pero que viene por parte de la gente de CoreOS. Digo que es equivalente a runC y containerd porque rkt tiene características de runtime de bajo nivel y de alto nivel. A día de hoy rkt no usa el formato definido por OCI si no uno propio (llamado ACI). Para más información podéis consultar el roadmap de soporte a OCI.
Aislamiento de contenedores
Recuerda que para que sean posibles los contenedores es necesario que el SO huésped los soporte nativamente. Linux hace tiempo que lo hace a través de dos características del Kernel: namespaces y cgroups (control groups).
- namespaces: Es una característica del Kernel que particiona los recursos del sistema de forma que distintos procesos (o grupos de procesos) ven distintos grupos de recursos. Redes, PIDs (ids de procesos), mounts o IPCs son algunos de los recursos que pueden existir en namespaces. Esto implica que un proceso puede ver un grupo de redes o PIDs que otro proceso puede no ver.
- cgroups: Otra característica del Kernel que limita el uso de recursos del sistema (CPU, disco, etc) a un grupo de procesos.
El aislamiento de contenedores está construído usando namespaces y el control de recursos usando cgroups. No hay complicadísimas técnicas de virtualización, emulación o control: se basa en recursos ofrecidos por el Kernel del propio SO. Eso significa que ejecutar un contenedor es algo muy ligero. Recuerda que los contenedores comparten siempre el Kernel: de Kernel sólo hay uno.
¿Podemos tener contenedores con un mayor nivel de aislamiento?
El propio Kernel de Linux ofrece mecanismos adicionales de aislamiento, como seccomp: usando seccomp se pueden prohibir ciertas llamadas al sistema (syscalls) a partir de un conjunto de reglas definido. Luego tenemos otras herramientas, como AppArmor (o también SELinux) que permiten especificar reglas adicionales que los procesos deben cumplir.
Pero en según que entornos podemos necesitar un nivel de aislamiento entre contenedores superior al provisto por el propio Kernel del SO. Es en este punto donde podemos usar un entorno de ejecución de contenedores que ofrezca un sandbox. En el mundo Linux hay, al menos, dos alternativas que podemos usar: hipervisores o gVisor. En el mundo Windows tenemos Hyper-V.
Aislmiento mediante un hipervisor
En este caso tenemos un modelo parecido al de una máquina virtual: cada contenedor recibe su propio Kernel del sistema operativo al completo. Así, el contenedor realiza llamadas a su Kernel propio (llamémosle guest kernel) que a través de un VMM (Virtual Machine Monitor) se comunica con el Kernel real (host kernel). Esa es la figura general (podemos realizar ciertas optimizaciones a través de paravirtualizaciones concretas) en donde obtenemos un gran aislamiento a cambio de un coste en el rendimiento (especialmente en el tiempo de levantar el contenedor). Este nivel de aislamiento se suele usar en entornos cloud usando hipervisores de nivel 1 (como Xen), pero también podemos usar hipervisores de nivel 2 (como KVM). Un runtime de contenedores que usa hipervisores es runV.
Este nivel de aislamiento es el que provee Hyper-V en el mundo Windows. Efectivamente, en Windows podemos ejecutar un contenedor bajo Hyper-V lo que le da acceso a su propio Kernel y todo el aislamiento que ofrece un hipervisor.
Aislamiento mediante gVisor
gVisor es un proyecto, relativamente reciente, de Google donde optan por otra aproximación a la hora de aislar los contenedores: gVisor «imita» a un guest kernel: intercepta las llamadas al sistema del contenedor y las reenvía al Kernel real de Linux. Y, por supuesto, antes de reenviarlas gVisor aplica todo tipo de reglas y filtros, para añadir el aislamiento deseado. El aislamiento que en teoría ofrece gVisor está entre el que ofrecen herramientas tipo seccomp y el ofrecido por hipervisores. A cambio, el coste en recursos es mucho menor. gVisor ofrece su propio runtime de contenedores llamado runsc que se puede integrar con Docker y con Kubernetes (a través de cri-o).
Runtimes de contenedores y Kubernetes
Hablar de runtimes de contenedores y Kubernetes es hablar de CRI, el Container Runtime Interface.
Inicialmente el soporte para distintos motores de ejecución en Kubernetes estaba integrado directamente en kubelet: así se soportaba tanto Docker como rkt. Eso implicaba que añadir soporte para futuros runtimes era muy complejo, ya que requería fuertes conocimientos de la arquitectura interna del kubelet. Así que, del mismo modo que este post empieza contando como Docker separó su código para desacoplarlo, este mismo camino está recorriendo Kubernetes. Y el resultado es CRI.
Usando CRI se pueden integrar motores de ejecución de contenedores de forma independiente sin necesidad alguna de tener que modificar kubelet (que es un elemento del core de Kubernetes). Un (llamémosle así) driver de CRI para un motor de ejecución concreto debe no solo permitir ejecutar contenedores sino soportar todo aquello que necesita Kubernetes (métricas, networking, logging, etc). Por supuesto cuando se definió CRI el primer paso fue sacar los drivers CRI para los dos motores de ejecución que ya soportaba Kubernetes: Docker y rkt.
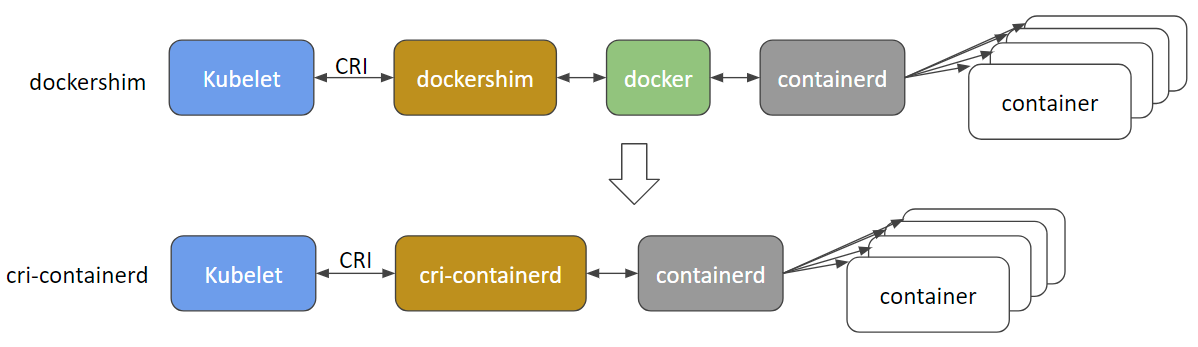
Así p. ej. usando Docker CRI (aka dockershim), cuando ejecutamos un contenedor en k8s, el kubelet llama a Docker-cri (usando la API definida por CRI) , que a su vez llama a Docker quien como hemos visto termina usando containerd para ejecutar el contenedor (bajo runC).
Otra opción es usar un driver CRI para containerd y nos saltamos a Docker directamente, tal y como se puede ver en esta imagen sacada del blog de Kubernetes:
Actualmente se están desarrollando varios drivers CRI:
- docker-cri (dockershim): Que ya está en GA
- rktlet: Para usar rkt bajo CRI
- cri-containerd: Para usar containerd directamente
- frakti: Para ejecutar contenedores bajo runV (usando un hipervisor)
- cri-o: Para usar cualquier runtime que sea compatible con OCI
Lo importante de estos drivers CRI es que «no forman parte del core» de Kubernetes: instalas los que necesitas según tus necesidades.
En resumen…
Cuando hablamos de «ejecutar un contenedor» estamos hablando de muchas cosas realmente. En este post he intentado clarificar un poco qué es lo que ocurre cuando ejecutamos un contenedor y qué opciones tenemos para hacerlo (al menos hoy, porque eso avanza muy rápido).
Saludos!