 A la vista de la cantidad de posts que se están escribiendo al respecto y del entusiasmo que despierta su utilización, parece claro que jQuery se está erigiendo como un interesantísimo complemento para el framework MVC de Microsoft.
A la vista de la cantidad de posts que se están escribiendo al respecto y del entusiasmo que despierta su utilización, parece claro que jQuery se está erigiendo como un interesantísimo complemento para el framework MVC de Microsoft.
jQuery, para que el no haya oído hablar de ella, es una librería Javascript destinada a facilitar enormemente la vida a los desarrolladores simplificando y unificando el manejo de eventos, la manipulación del contenido (DOM), estilos, el uso de Ajax, la creación de animaciones y efectos gráficos, y un larguísimo etcétera propiciado por la facilidad para añadirle plugins que extienden sus funcionalidades iniciales. Y todo ello de forma muy rápida, sin excesivas complicaciones, y sin añadir demasiado peso a las páginas.
En este post vamos a ver un ejemplo de integración de jQuery con ASP.NET MVC framework realizando una aplicación muy sencilla e ilustrativa que nos enseñará cómo enviar información desde el cliente al servidor y actualizar porciones de página completas con el retorno de éste, respetando en todo momento la filosofía MVC.
El funcionamiento será realmente simple: el usuario introduce su nombre y edad, y al pulsar el botón se enviará esta información al servidor, que la utiliza para componer una respuesta y mandarla de vuelta al cliente. Cuando éste la recibe, la mostrará (con un poco de ‘magia’ visual de jQuery) y transcurridos unos segundos, desaparecerá de forma automática. La siguiente captura muestra el sistema que vamos a construir en ejecución:
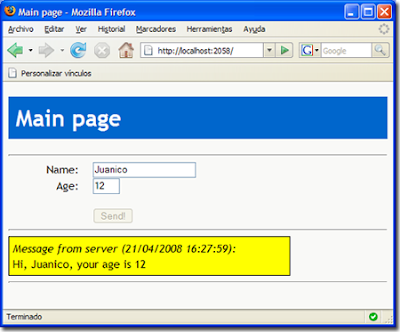
Pero antes de entrar en faena, unos comentarios. En primer lugar, sólo voy a explicar los aspectos de interés para la realización del ejemplo, partiendo de las plantillas adaptadas para Web Developer Express 2008. Si prefieres antes una introducción sobre el framework, puedes visitar las magníficas traducciones de Thinking in .Net de los tutoriales de Scott Guthrië sobre MVC. Se refieren a la primera preview, pero los fundamentos son igualmente válidos.
Segundo, supongo que funcionará con versiones superiores de Visual Studio, pero no he podido comprobarlo. Está creado y comprobado con Visual Web Developer Express, y la Preview 2 del framework MVC.
Y por último, decir que el ejemplo completo podrás descargarlo usando el enlace que encontrarás al final del post. 🙂
Primero: Estructuramos la solución
En líneas generales, nuestra aplicación tendrá los siguientes componentes:
- Tendremos un controlador principal, llamado Home. En él crearemos dos acciones, las dos únicas que permite nuestra aplicación: una, llamada Index, que se encargará de mostrar la página inicial del sistema, y otra llamada Welcome, que a partir de los datos introducidos por el usuario maquetará el interfaz del mensaje de saludo.
- Como consecuencia del punto anterior, dispondremos de dos vistas. La primera, Index compondrá la interfaz principal con el formulario, y la segunda, que llamaremos Welcome, que define la interfaz del saludo al usuario (el recuadro de color amarillo chillón ;-)).
Esta última vista necesitará los datos de la persona (nombre y edad) para poder mostrar correctamente su mensaje, por lo que el controlador deberá enviárselos después de obtenerlos de los parámetros de la petición.
Fijaos que respetamos en todo momento el patrón MVC haciendo que el cliente invoque a la acción Welcome del controlador usando Ajax, y que la composición del interfaz (HTML) se realice a través de la vista correspondiente. Utilizaremos, por tanto, toda la infraestructura del framework MVC, sin modificaciones.
- También, para añadir algo de emoción, he incluido una página maestra, que definirá el interfaz general de las páginas del sistema y realizará la inclusión de los archivos adicionales necesarios, como las hojas de estilo y scripts como jQuery.
Segundo: implementamos el controlador
El controlador de nuestra aplicación va a ser bien simple. Lo vemos y comentamos seguidamente:
public class HomeController : Controller
{
public void Index()
{
RenderView(«Index»);
}
public void Welcome(string name, int age)
{
Person person =
new Person { Age = age, Name = name };
RenderView(«Welcome», person);
}
}
public class Person
{
public string Name { get; set; }
public int Age { get; set; }
}
Podemos observar la clase HomeController que implementa las acciones del controlador Home. La acción Index provoca la visualización de la vista de su mismo nombre.
La acción Welcome, es algo más compleja; en primer lugar, se observa que recibe dos parámetros, en nombre y edad del usuario, que utiliza para montar un objeto de tipo Person, definido algo más abajo, que posteriormente envía a la vista a la hora de renderizarla. Habréis observado aquí la utilización de inicializadores de objetos en la instanciación, y de propiedades automáticas en la definición del tipo.
Tercero: implementamos las vistas
Recordemos que vamos a implementar dos vistas, una para la página principal (llamada Index), que mostrará el formulario de entrada de datos, y otra (que llamaremos Welcome) que definirá el interfaz de la respuesta del servidor. Comenzaremos describiendo cómo incluir jQuery en nuestras páginas, y pasaremos después a ellas.
3.1. Inclusión de jQuery
Para implementar las vistas necesitamos antes preparar la infraestructura. En primer lugar, descargamos jQuery desde la web oficial del proyecto, y la introducimos en nuestro proyecto. Si vas a descargar la solución completa desde aquí, en ella ya viene incluido el archivo.
A continuación, es un buen momento para modificar la página maestra e incluir en ella la referencia a esta librería:
<script type=»text/javascript»
src=»/scripts/jquery-1.2.3.min.js»>
</script>
Un inciso importante aquí. Hace unas semanas se publicó un HotFix para Visual Studio 2008 y Web Developer Express que corrije, entre otras, deficiencias en el intellisense y hacen posible el uso de esta magnífica ayuda cuando escribimos código jQuery. Altamente recomendable, pues, instalarse esta actualización.
Sin embargo, el hecho de introducir en la página maestra la referencia a la librería jQuery hace que el intellisense no funcione como debe. Por tanto, aunque no es la opción que he elegido en este proyecto, podríais incluir el script directamente en la vista Index en lugar de en la Master, y así disfrutaréis del soporte a la codificación.
3.2. La vista «Index»
Esta vista será la encargada de mostrar el formulario e implementar la lógica de cliente necesaria para obtener los datos del usuario, enviarlos al servidor y actualizar el interfaz con el retorno. Su implementación se encuentra en el archivo Index.aspx.
Desde el punto de vista del interfaz de usuario es bastante simple, lo justo para mostrar un par de inputs con sus correspondientes etiquetas y el botón que iniciará la fiesta llamando a la función send():
<form action=»» id=»myForm»>
<label for=»name»>Name: </label><input type=»text» id=»name» />
<br />
<label for=»age»>Age: </label><input type=»text» id=»age» size=»2″ />
<br />
<button id=»btn» onclick=»send(); return false;»>Send!</button>
</form>
<hr />
<div id=»result» style=»display: none; width: 400px»></div>
Observad que no es necesario establecer un action en el formulario, ni otros de los atributos habituales, pues éste no se enviará (de hecho, el formulario incluso sería innecesario). Fijaos también que el evento onclick del botón retorna false, para evitar que se produzca un postback (¡aaargh, palabra maldita! ;-)) del formulario completo.
Puede verse también un div llamado «result», inicialmente invisible, que se utilizará de contenedor para mostrar las respuestas obtenidas desde el servidor.
Pasemos ahora al script. La función send() invocada como consecuencia de la pulsación del botón pinta así:
function send()
{
var name = document.getElementById(«name»).value;
var age = document.getElementById(«age»).value;
updateServerText(name, age);
}
En realidad no hace gran cosa: obtiene el valor de los textboxes y llama a la función que realmente hace el trabajo duro. Este hubiera sido un buen sitio para poner validadores, pero eso os lo dejo de deberes ;-).
El código de la función updateServerText() es el siguiente:
function updateServerText(name, age)
{
document.getElementById(«btn»).disabled = true;
$.ajax({
cache: false,
url: ‘<%= Url.Action(«Welcome», «Home») %>’,
data: {
Name: name,
Age: age
},
success: function(msg) {
$(«#result»).html(msg).show(«slow»);
},
error: function(msg) {
$(«#result»).html(«Bad parameters!»).show(«slow»);
}
});
setTimeout(function () {
document.getElementById(«btn»).disabled = false;
$(«#result»).hide(«slow»);
}, 3000);
}
En primer lugar, se desactiva el botón de envío para evitar nuevas pulsaciones hasta que nos interese. He utilizado un método habitual del DOM, getElementById() para conseguirlo, no encontré una alternativa mejor en jQuery.
A continuación se utiliza el método ajax de jQuery para realizar la llamada al servidor. Aunque existen otras alternativas de más alto nivel y por tanto más fáciles de utilizar, elegí esta para tener más control sobre lo que envío, la forma de hacerlo y la respuesta.
Los parámetros utilizados en la llamada a $.ajax son:
cache, con el que forzamos la anulación de caché, obligando a que cada llamada se ejecute totalmente, sin utilizar el contenido almacenado en cliente. Internamente, jQuery añade al querystring un parámetro aleatorio, con lo que consigue que cada llamada sea única.
url, la dirección de invocación de la acción, que se genera utilizando el método de ayuda Url.Action(), pasándole como parámetros el controlador y la acción, lo que retornará la URL asociada en el sistema de rutas definido. En condiciones normales, si la aplicación se ejecuta sobre el raíz del servidor web, se traducirá por ‘/Home/Welcome’.
data, los datos a enviar, que se establecen en formato JSON, donde cada propiedad va seguida de su valor. jQuery tomará estos valores y los transformará en los parámetros que necesita la acción Welcome, por lo que el nombre de las propiedades deberá corresponder con los parámetros que espera esta acción (Name y Age).
sucess define la función de retorno exitoso, que mostrará los datos recibidos del servidor introduciéndolos en el contenedor «result». Y ya que estamos, gracias a la magia de jQuery, se mostrará con un efecto visual muy majo.
error, define una función de captura de errores para casos extraños, por si todo falla. Por ejemplo, dado que no estamos validando la entrada del usuario, si éste introduce texto en la edad, el framework no será capaz de realizar la conversión para pasarle los parámetros al controlador y fallará estrepitosamente; en este caso simplemente mostraremos un mensaje de error en cliente.
Fijaos que la llamada a la acción (Welcome) del controlador (Home) es capturada por el framework y dirigida al método correspondiente sin necesidad de hacer nada más, dado que se trata de una llamada HTTP normal. De hecho, si sobre el navegador se introduce la dirección «http://localhost:[tupuerto]/Home/Welcome?Name=Peter&Age=12» podremos ver en pantalla el mismo resultado que recibirá la llamada Ajax.
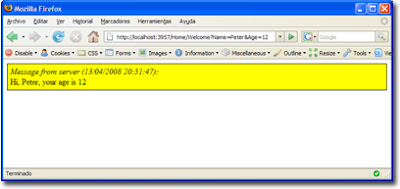
Obviamente, este efecto podría ser controlado y hacer que sólo se respondieran peticiones originadas a través de Ajax y similares.
Por último, continando con el código anterior, dejamos programado un timer para que unos segundos más tarde, el mensaje mostrado, sea cual sea el resultado de la llamada Ajax, desaparezca lentamente y, de paso, se active de nuevo el botón de envío. El efecto, ya lo veréis si ejecutáis la solución, es de lo más vistoso, creando una sensación de interactividad y dinamismo muy a lo 2.0 que está tan de moda.
3.3. La vista «Welcome»
En esta vista definiremos el interfaz del mensaje que mostraremos al usuario cuando introduzca su información y pulse el botón de envío. Dado que estamos usando MVC, la llamada Ajax descrita anteriormente llegará al controlador y éste hará que la vista cree el interfaz que será devuelto al cliente.
La vista, por tanto, es como cualquier otra, salvo algunas diferencias interesantes. Por ejemplo, no tiene página maestra, no la necesita; de hecho ni siquiera tiene la estructura de una página HTML completa, sólo de la porción que necesita para montar su representación. El código de Welcome.aspx, salvo las obligatorias directivas iniciales, es:
<div style=»background-color: Yellow; border: 1px solid black;»>
<em>Message from server (<%=DateTime.Now %>):</em><br />
Hi, <%= ViewData.Name %>, your age is <%= ViewData.Age %>
</div>
Pero aún queda un detalle que afinar. En el archivo code-behind (o codefile) donde se define la clase Welcome hay que indicar expresamente que la clase es una vista de un tipo concreto de la siguiente forma:
public partial class Views_WebParts_Welcome : ViewPage<Person>
{
}
De esta forma indicamos que los datos de la vista son del tipo Person, lo que nos permite beneficiarnos del tipado fuerte en la composición de la misma; de hecho, esto es lo que permite que podamos usar tan alegremente una expresión como ViewData.Age a la hora de componer el interfaz.
Fijaos que aunque en este ejemplo no hemos hecho ninguna composición compleja y los datos que hemos usado, contenidos en ViewData, han sido obtenidos por el Controlador directamente de la vista, sería exactamente igual si se tratara de algo menos simple, como una página concreta de datos obtenidos desde el Modelo, por ejemplo con Linq, y mostrados en forma de grid.
Cuarto: recapitulamos
Hemos visto, paso a paso, un ejemplo de cómo podemos utilizar el framework MVC de Microsoft para el desarrollo de aplicaciones web que hacen uso de Ajax, utilizando para ello la excelente librería de scripting jQuery.
Para ello hemos creado una vista que es la página Web con el formulario principal, y otra vista parcial con el fragmento compuesto por el servidor con la información recibida. El controlador, por su parte, incluye acciones para responder a las peticiones del cliente independientemente de si se originan a través de Ajax o mediante la navegación del usuario, mostrando la vista oportuna.
La modificación dinámica del interfaz, así como las llamadas asíncronas al servidor, encajan perfectamente en la filosofía MVC teniendo en cuenta algunas reglas básicas, como el respeto a las responsabilidades de cada capa.
Y ahora, lo prometido:
 Descargar proyecto (Visual Web Developer Express 2008).
Descargar proyecto (Visual Web Developer Express 2008).
Publicado en: www.variablenotfound.com.
 Días atrás hablaba de las formas de inicialización de objetos que nos proporcionaban las últimas versiones de C# y VB.Net, que permitían asignar valores a miembros de instancia de forma muy compacta, legible y cómoda.
Días atrás hablaba de las formas de inicialización de objetos que nos proporcionaban las últimas versiones de C# y VB.Net, que permitían asignar valores a miembros de instancia de forma muy compacta, legible y cómoda.






