![]() ScottGu, Hanselman y John Resig han publicado hoy una noticia muy esperada por los entusiastas de la popular librería jQuery y de las herramientas de desarrollo de Microsoft: jQuery va a formar parte de la plataforma oficial de desarrollo de la compañía.
ScottGu, Hanselman y John Resig han publicado hoy una noticia muy esperada por los entusiastas de la popular librería jQuery y de las herramientas de desarrollo de Microsoft: jQuery va a formar parte de la plataforma oficial de desarrollo de la compañía.
Esto se traduce, en primer lugar, en que será distribuida con Visual Studio, pero eso sí, tal cual, sin modificaciones ni aditivos que puedan suponer la separación de las versiones oficiales de jQuery. Por ejemplo, ASP.NET MVC incluirá de serie la librería en las plantillas de los nuevos proyectos.
Pero no acaban ahí los compromisos. También facilitarán versiones con anotaciones que permitirán disfrutar totalmente de la experiencia intellisense mientras trabajemos con ella, que según comentan estará disponible como una descarga gratuita independiente en unas semanas. Incluso el soporte 24×7 para desarrolladores podrán abrir cuestiones relacionadas con esta librería.
Asimismo, se pretende darle uso para la implementación de controles para el ASP.NET AJAX Control Toolkit, para la construcción de helpers para el framework MVC, y, en general, integrarla con todas las nuevas características y desarrollos que vayan apareciendo.
Buena noticia, sin duda… 🙂
Publicado en: www.variablenotfound.com.
Mes: septiembre 2008
Bullet Physics, motor de física para C++ y Java
 Siguiendo con el tema que comenzaba hace ya unos meses, hoy os traigo otra demo de otro motor de física, esta vez para desarrollos realizados en C++, Bullet Physics Library. Se trata de un potente motor de física en tres dimensiones para una gran variedad de plataformas, Win32, Linux, Mac, XBox, Wii, e incluso la PS3.
Siguiendo con el tema que comenzaba hace ya unos meses, hoy os traigo otra demo de otro motor de física, esta vez para desarrollos realizados en C++, Bullet Physics Library. Se trata de un potente motor de física en tres dimensiones para una gran variedad de plataformas, Win32, Linux, Mac, XBox, Wii, e incluso la PS3.
Las demostraciones de este motor son ejecutables, por lo que hay que descargarlas y ejecutarlas en el equipo local. Si utilizáis Windows, os recomiendo echar un vistazo al paquete de demostraciones [~3MB], con el que se puede comprobar la potencia de la librería. No es necesario instalar nada, sólo descomprimir el contenido en una carpeta y ejecutar la demo.
La revisión actual, 2.71 se publicó hace tan sólo unos días. El código fuente del proyecto está alojado en Google Code, y su modelo de licencia (MIT) permite su utilización en proyectos comerciales.
Y por cierto, existe un port para Java, jBullet, cuyas demostraciones pueden descargarse y ejecutarse a través de Java Webstart, por lo que resulta mucho más cómodo. Incluso aunque el rendimiento es muy inferior al real al usar renderizado por software, puede ejecutarse en un applet, que por alguna extraña razon no he sido capaz de incrustar aquí en Geeks.ms.
Ver en la página oficial
Debéis elegir una demo en el desplegable (hay cinco disponibles, os recomiendo que comencéis por la primera), en las que podéis usar las teclas «Z» y «X» para acercaros y alejaros de la escena, las flechas de dirección para girar, y con el ratón podéis aplicar impulsos a los cubos (arrastrando con el botón izquierdo) y lanzar cubos (con el bótón derecho). Como observaréis, dentro del mismo applet aparecen instrucciones de otras teclas, incluso algunas para demos concretas. Especialmente interesante e improductivo es lanzarle piezas al cubo gigante (basic demo), intentar hacer caminar la araña (dynamic control demo), o dedicarse a transportar mesas de un lado a otro con una carretilla (forklift demo).
Que lo disfrutéis.
Publicado en: www.variablenotfound.com.
Crear puntos de ruptura en tiempo de ejecución con .NET
 Todos sabemos crear puntos de ruptura (breakpoints) desde Visual Studio, y lo indispensables que resultan para depurar nuestras aplicaciones. Y si la cosa está complicada, los puntos de ruptura condicionales pueden ayudarnos a lanzar el depurador justo cuando se cumpla la expresión que indiquemos.
Todos sabemos crear puntos de ruptura (breakpoints) desde Visual Studio, y lo indispensables que resultan para depurar nuestras aplicaciones. Y si la cosa está complicada, los puntos de ruptura condicionales pueden ayudarnos a lanzar el depurador justo cuando se cumpla la expresión que indiquemos.
Lo que no conocía era la posibilidad de establecerlos por código desde la propia aplicación que estamos depurando, que puede resultar útil en momentos en que nos sea incómodo crearlos desde el entorno de desarrollo. Es tan sencillo como incluir el siguiente fragmento en el punto donde deseemos que la ejecución de detenga y salte el entorno:
// C#
if (System.Diagnostics.Debugger.IsAttached)
{
System.Diagnostics.Debugger.Break();
}
‘ VB.NET:
If System.Diagnostics.Debugger.IsAttached Then
System.Diagnostics.Debugger.Break()
End If
Como ya habréis adivinado, el if lo único que hace es asegurar que la aplicación se esté ejecutando enlazada a un depurador, o lo que es lo mismo, desde dentro del entorno de desarrollo; si se ejecuta fuera del IDE no ocurrirá nada.
Si eliminamos esta protección, la llamada a Debugger.Break() desde fuera del entorno generará un cuadro de diálogo que dará la oportunidad al usuario de abrir el depurador: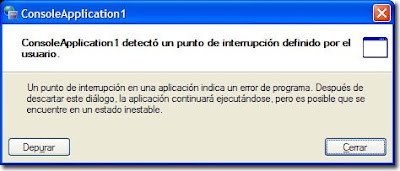
De todas formas lo mejor es usarlo con precaución, que eso de dejar el código con residuos de la depuración no parece muy elegante…
Publicado en: www.variablenotfound.com.
La depuración y las cinco fases del duelo
 Cuando Elisabeth Kübler-Ross, eminente médica psiquiatra suizo-americana, enunció su famoso modelo Kübler-Ross en 1969, seguro que no andaba pensando en el mundo del desarrollo de software. De hecho, este modelo describe las cinco fases por las que pasa un enfermo terminal, o cualquier persona afectada por una situación de gravedad extrema: negación, ira, negociación, depresión y aceptación, también conocidas como «las cinco fases del duelo».
Cuando Elisabeth Kübler-Ross, eminente médica psiquiatra suizo-americana, enunció su famoso modelo Kübler-Ross en 1969, seguro que no andaba pensando en el mundo del desarrollo de software. De hecho, este modelo describe las cinco fases por las que pasa un enfermo terminal, o cualquier persona afectada por una situación de gravedad extrema: negación, ira, negociación, depresión y aceptación, también conocidas como «las cinco fases del duelo».
El genial Kevin Pang ha publicado un divertido artículo en Datamation, Debugging and The Five Stages of Grief, utilizándolas para describir los sentimientos del desarrollador ante la aparición de un bug en su aplicación:
- Negación. En esta fase, ante el descubrimiento de un posible fallo, nos ponemos en actitud defensiva e intentamos echarle la culpa a todo menos a nuestros desarrollos. Nosotros no fallamos nunca… ¿o tal vez sí?
- Ira. Acto seguido, una vez demostrado que existe un problema, comienzan los bufidos, resoplidos y voces airadas del tipo ¿cómo no se ha detectado esto antes?, ¡vaya mierda de aplicación!, o ¡¡joder, justo ahora, con lo ocupado que estoy!!
- Negociación. Vale, asumimos que hay un error y ya hemos despotricado durante un rato. El siguiente paso es negociar (habitualmente con nosotros mismos) sobre el tipo de solución a dar: ¿apuntalamos lo suficiente como para que siga funcionando, u optamos por solucionar de forma definitiva el problema? Difícil decisión a veces.
- Depresión. Ahora lo que toca es la depresiva tarea de la depuración. A nadie le gusta escudriñar en el código en busca de un error, ¡hemos nacido para crear software espectacular, no para corregirlo! Es un buen momento para compadecernos de nosotros mismos.
- Aceptación. Hemos asimilado la realidad de que nuestro código falla, hemos maldecido la situación, decidido que vamos a corregirlo como auténticos profesionales, e incluso hemos llorado un rato sobre nuestra mala suerte. Sin embargo, esto es así y hay que aceptarlo, forma parte de la pesada mochila que los desarrolladores llevamos a las espaldas. Eso sí, sólo otro desarrollador puede entenderlo, no intentes explicárselo a tu esposa, madre, jefe, o vecino.
Si tienes un rato, no te pierdas el artículo original.
Publicado en: www.variablenotfound.com.
Foto del primer bug informático
Hace unos días, el nueve de septiembre, se cumplían 61 años desde la primera aparición «documentada» de un bug informático. Y como en todos los cumpleaños, ahí va la foto del protagonista, literalmente:
Se trata de la polilla que provocó problemas de funcionamento en el primitivo ordenador Mark II el martes 9 de septiembre de 1947, al colarse y quedarse atrapada en el relé número 70 del Panel F (que debe venir a ser algo así como la línea X del archivo Y del código fuente de los de ahora). La incidencia fue reflejada en el cuaderno de bitácora (log) del sistema, al que pertenece la fotografía superior, adjuntando el insecto como prueba del delito.
El término «bug» ya se utilizaba entonces como sinónimo de error en otros ámbitos, como en telegrafía, telefonía o sistemas eléctricos, de ahí la frase que registró el operador debajo del animalito, haciendo referencia a que era la primera vez que se encontraba un auténtico bug (=bicho):
«First actual case of bug being found»
Fuente: The first computer bug
Publicado en: www.variablenotfound.com.
Formas efectivas de ofuscar emails en páginas web
Todos sabemos que los spammers utilizan aplicaciones (llamadas robots, bots, spambots, o arañas) que, de forma automática, rastrean Internet buscando y almacenando direcciones de correo electrónico. Para ello recorren páginas, analizan su contenido en busca de series de caracteres que puedan parecer una dirección de correo (normalmente localizando la arroba -@- u otros patrones presentes en ellas), y siguen sus enlaces en busca de otras páginas no visitadas para iniciar de nuevo este procedimiento.
Esta técnica es tan antigua como la Web, y por este motivo (y no por otros ;-)) estamos en las listas de vendedores de viagra y alargadores de miembros todos aquellos que aún conservamos buzones desde los tiempos en que Internet era un lugar cándido y apacible. Años atrás, poner tu email real en una web, foro o tablón era lo más normal y seguro.
Pero los tiempos han cambiado. Hoy en día, publicar la dirección de email en una web es condenarla a sufrir la maldición del spam diario, y sin embargo, sigue siendo un dato a incluir en cualquier sitio donde se desee facilitar el contacto vía correo electrónico tradicional. Y justo por esa razón existen las técnicas de ofuscación: permiten, o al menos intentan, que las direcciones email sean visibles y accesibles para los usuarios de un sitio web, y al mismo tiempo sean indetectables para los robots, utilizando para ello diversas técnicas de camuflaje en el código fuente de las páginas.
Desafortunadamente, ninguna técnica de ofuscación es perfecta. Algunas usan javascript, lo cual impide su uso en aquellos usuarios que navegan sin esta capacidad (hay estadísticas que estiman que son sobre el 5%); otras presentan problemas de accesibilidad, compatibilidad con algunos navegadores o impiden ciertas funcionalidades, como que el sistema abra el cliente de correo predeterminado al pulsar sobre el enlace; otras, simplemente, son esquivables por los spammers de forma muy sencilla.
En el fondo se trata de un problema similar al que encontramos en la tradicional guerra virus vs. antivirus: cada medida de protección viene seguida de una acción en sentido contrario por parte de los spammers. Una auténtica carrera, vaya, que por la pinta que tiene va a durar bastante tiempo.
En 2006, Silvan Mühlemann comenzó un interesante experimento. Creó una página Web en la que introdujo nueve direcciones de correo distintas, y cada una utilizando un sistema de ofuscación diferente:
- Texto plano, es decir, introduciendo un enlace del tipo:
<a href=»mailto:user@myserver.xx» mce_href=»mailto:user@myserver.xx»>email me</a>
- Sustituyendo las arrobas por «AT» y los puntos por «DOT», de forma que una dirección queda de la forma:
<a href=»mailto:userATserverDOTxx» mce_href=»mailto:userATserverDOTxx»>email me</a>
- Sustituyendo las arrobas y puntos por sus correspondientes entidades HTML:
<a href=»mailto:user@server.xx» mce_href=»mailto:user@server.xx»>email me</a>
- Introduciendo la dirección con los códigos de los caracteres que la componen:
<a href=»mailto:%73%69%6c%76%61%6e%66%6f%6f%62%61%72%34%40%74%69%6c%6c%6c%61%74%65%65%65%65%65″ mce_href=»mailto:%73%69%6c%76%61%6e%66%6f%6f%62%61%72%34%40%74%69%6c%6c%6c%61%74%65%65%65%65%65″>email me</a>
- Mostrando la dirección de correo sin enlace y troceándola con comentarios HTML, que el usuario podrá ver sin problema como user@myserver.com aunque los bots se encontrarán con algo como:
user<!– –>@<!— @ –>my<!– –>server.<!— . –>com
- Construyendo el enlace desde javascript en tiempo de ejecución con un código como el siguiente:
var string1 = «user»;
var string2 = «@»;
var string3 = «myserver.xx»;
var string4 = string1 + string2 + string3;
document.write(«<a href=» + «mail» + «to:» + string1 +
string2 + string3 + «>» + string4 + «</a>»);
- Escribiendo la dirección al revés en el código fuente y cambiando desde CSS la dirección de presentación del texto, así:
<style type=»text/css»>
span.codedirection { unicode-bidi:bidi-override; direction: rtl; }
</style>
<span class=»codedirection»>moc.revresym@resu</span>
- Introduciendo texto incorrecto en la dirección y ocultándolo después desde CSS:
<style type=»text/css»>
span.displaynone { display:none; }
</style>
Email me: user@<span class=»displaynone»>goaway</span>myserver.net
- Generando el enlace desde javascript partiendo de una cadena codificada en ROT13, según una idea original de Christoph Burgdorfer:
<script type=»text/javascript»>
document.write(‘<n uers=»znvygb:fvyinasbbone10@gvyyyngr.pbz» ery=»absbyybj»>‘.replace(/[a-zA-Z]/g,
function(c){return String.fromCharCode((c<=»Z»?90:122)>=(cc=c.charCodeAt(0)+13)?c:c-26);}));
</script>silvanfoobar’s Mail</a>
Después de crear esta página, se aseguró la visita de los bots vinculándola desde la Home de la comunidad tillate.com y esperó durante un año y medio para obtener las conclusiones que publicó en su post Nine ways to obfuscate e-mail addresses compared.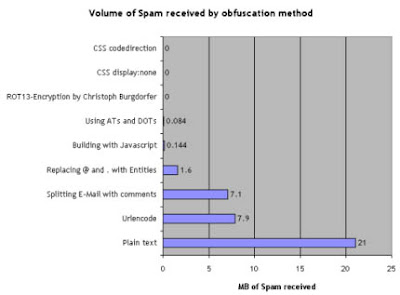 Las conclusiones que obtuvo son las siguientes: incluir la dirección de correo en texto plano y sin protección (opción 1) generó 21 Megabytes de spam; las peores técnicas, la codificación URL (4) y el troceado de la dirección con comentarios (5) lo redujeron a 7-8Mb; ya la sustitución de la arroba y puntos por las entidades HTML (3) dejó el spam en 1.6 Mb, lo que implica una reducción mayor al 90% sobre la primera alternativa. El uso de AT y DOT (2), así como la generación por javascript (6) dieron como resultado la práctica ausencia de spam, que ya con los tres métodos restantes se redujo a cero absoluto.
Las conclusiones que obtuvo son las siguientes: incluir la dirección de correo en texto plano y sin protección (opción 1) generó 21 Megabytes de spam; las peores técnicas, la codificación URL (4) y el troceado de la dirección con comentarios (5) lo redujeron a 7-8Mb; ya la sustitución de la arroba y puntos por las entidades HTML (3) dejó el spam en 1.6 Mb, lo que implica una reducción mayor al 90% sobre la primera alternativa. El uso de AT y DOT (2), así como la generación por javascript (6) dieron como resultado la práctica ausencia de spam, que ya con los tres métodos restantes se redujo a cero absoluto.
Por tanto, atendiendo al resultado de este experimento, si estamos desarrollando una página que asume la existencia de javascript podríamos utilizar el método del ROT13 (9) para generar los enlaces mailto: con ciertas garantías de éxito frente al spam. Podéis usar el código anterior, cambiando el texto codificado (en negrita) por el que generéis desde esta herramienta (ojo: hay que codificar la etiqueta de apertura completa, como <a href=»mailto:loquesea» mce_href=»mailto:loquesea»>, incluidos los caracteres de inicio «<» y fin «>», pero sin introducir el texto del enlace ni el cierre </a> de la misma).
También podemos utilizar alternativas realmente ofuscadoras, como la ofrecida por el Enkoder de Hivelogic, una herramienta on-line que nos permite generar código javascript listo para copiar y pegar, cuya ejecución nos proporcionará un enlace mailto: completo en nuestras páginas.
Pero atención, que el uso de javascript no asegura el camuflaje total y de por vida de la dirección de correo por muy codificada que esté en el interior del código fuente. Un robot que incluya un intérprete de este lenguaje y sea capaz de ejecutarlo podría obtener el email finalmente mostrado, aunque esta opción, por su complejidad y coste de proceso, no es todavía muy utilizada; sí que es cierto que algunos recolectores realizan un análisis del código javascript para detectar determinadas técnicas, por lo que cuando más ofuscada y personalizada sea la generación, mucho mejor.
En caso contrario, si no podemos usar javascript, lo tenemos algo más complicado. Con cualquiera de las soluciones CSS descritas en los puntos 7 y 8 (ambas han conseguido aguantar el tiempo del experimento sin recibir ningún spam), incluso una combinación de ambas, es cierto que el usuario de la página podrá leer la dirección de correo, mientras que para los robots será un texto incomprensible. Sin embargo, estaremos eliminando la posibilidad de que se abra el gestor de correo del usuario al cliquear sobre el enlace, así como añadiendo un importante problema de accesibilidad en la página. Por ejemplo, si el usuario decide copiar la dirección para pegarla en la casilla de destinatario de su cliente, se llevará la sorpresa de que estará al revés o contendrá caracteres extraños. Por tanto, aunque pueda ser útil en un momento dado, no es una solución demasiado buena.
La introducción de «AT» y «DOT», o equivalentes en nuestro idioma como «EN» y «PUNTO», con adornos como corchetes, llaves o paréntesis podrían prestar una protección razonable, pero son un incordio para el usuario y una aberración desde el punto de vista de la accesibilidad. Además, el hecho de que se haya recibido algún mensaje en el buzón que utilizaba esta técnica ya implica que hay spambots que la contemplan y, por tanto, en poco tiempo podría estar bastante popularizada, por lo que habría que buscar combinaciones surrealistas, más difíciles de detectar, como «juanARROBICAservidorPUNTICOcom», o «juanCAMBIA_ESTO_POR_UNA_ARROBAservidorPON_AQUI_UN_PUNTOcom». Pero lo dicho, una incomodidad para el usuario en cualquier caso.
Hay otras técnicas que pueden resultar también válidas, como introducir las direcciones en imágenes, applets java u objetos flash incrustados, redirecciones y manipulaciones desde servidor, el uso de captchas, y un largo etcétera que de hecho se usan en multitud de sitios web, pero siempre nos encontramos con problemas similares: requiere disponer de algún software (como flash, o una JVM), una característica activa (por ejemplo scripts o CSS), o atentan contra la usabilidad y accesibilidad del sitio web.
Como comentaba al principio, ninguna técnica es perfecta ni válida eternamente, por lo que queda al criterio de cada uno elegir la más apropiada en función del contexto del sitio web, del tipo de usuario potencial y de las tecnologías aplicables en cada caso.
La mejor protección es, sin duda, evitar la inclusión de una direcciones de email en páginas que puedan ser accedidas por los rastreadores de los spammers. El uso de formularios de contacto, convenientemente protegidos por sistemas de captcha gráficos (¡los odio!) o similares, pueden ser un buen sustituto para facilitar la comunicación entre partes sin publicar direcciones de correo electrónico.
Publicado en: www.variablenotfound.com.
ASP.NET MVC Preview 5, y la primera beta se acerca
A finales de Agosto se publicó en Codeplex, como viene siendo habitual, los instalables y código fuente de la quinta preview del framework MVC para ASP.NET en el que Microsoft lleva trabajando desde el año pasado y del que ya hemos hablado en varias ocasiones por aquí.
Muchas son las novedades que han introducido esta vez, y algunas realmente muy esperadas, como el sistema de validaciones de datos en formularios, nuevos atributos de nombrado y filtrado de acciones, o los ModelBinders, el mecanismo que permite utilizar parámetros de tipos complejos (es decir, no nativos) en las acciones de nuestros controladores. Richard Chamorro ha realizado un buen resumen de las novedades y cambios de esta entrega respecto a la preview 4, en las que ya iremos profundizando.
Y a propósito de la Preview 4, también introdujo bastantes novedades respecto a la anterior: nuevos atributos de filtros de ejecución de acciones y captura de errores de ejecución, control sobre el cacheado de respuestas, algunos helpers básicos destinados al intercambio de datos usando Microsoft Ajax, cambios en las plantillas para Visual Studio introduciendo controladores y vistas para un sistema simple de autenticación de usuarios y gestión de errores, y otras mejoras. Sin embargo, debido al cierre por vacaciones de Variable not found y a la aparición de la preview 5 no he tenido tiempo para ir revisándolas; ya iré comentando los que me resulten especialmente interesantes.
Por último, según indica el gran Phil Haack en su post «ASP.NET MVC Codeplex preview 5 released«, no entra en sus planes que haya más previews. Lo próximo que tendremos entre las manos será ya una versión Beta, muy cercana al producto final que podremos disfrutar sobre finales de año («en un mes que acabe en -bre», como bromeó hace poco Scott Hanselman). Eso sí, supongo que antes pasaremos por varias betas e incluso alguna versión candidata.
Parece que tenemos unos meses divertidos por delante…
Publicado en: www.variablenotfound.com.
Destacar enlaces a páginas en otros idiomas
 Utilizando apropiadamente (X)HTML y hojas de estilo CSS, se pueden conseguir un montón de efectos interesantes para nuestras webs, como la inclusión de imágenes de fondo en cuadros de texto de formularios que vimos hace algún tiempo. Hoy vamos a ver lo fácil que resulta destacar enlaces (links) a páginas en idiomas distintos al nuestro de forma muy gráfica, colocando a su lado una banderilla que indique la lengua de destino, sin apenas introducir código adicional.
Utilizando apropiadamente (X)HTML y hojas de estilo CSS, se pueden conseguir un montón de efectos interesantes para nuestras webs, como la inclusión de imágenes de fondo en cuadros de texto de formularios que vimos hace algún tiempo. Hoy vamos a ver lo fácil que resulta destacar enlaces (links) a páginas en idiomas distintos al nuestro de forma muy gráfica, colocando a su lado una banderilla que indique la lengua de destino, sin apenas introducir código adicional.
Para lograrlo, necesitamos solucionar dos problemas. El primero es cómo indicar en los enlaces (dentro de la etiqueta <a> de nuestro código X/HTML) el idioma de la página a la que saltará el usuario; el segundo problema es el describir en la hoja de estilos (CSS) estos enlaces, de forma que se representen con la banderita correspondiente. Ambos tienen fácil solución gracias a los estándares de la W3C.
Hace ya bastantes años, el estándar HTML definió el atributo hreflang en los hipervínculos con objeto de indicar el idioma del recurso apuntado por el atributo href. En otras palabras, si estamos apuntando a una página debería contener el idioma de la misma, justo lo que necesitamos:
<a href=»http://www.csszengarden.com» mce_href=»http://www.csszengarden.com» hreflang=»en»>CSS Zen Garden</a>
Por otra parte, el estándar CSS 2.1 define un gran número de selectores que podemos utilizar para identificar los elementos de nuestra página a los que queremos aplicar las reglas de estilo especificadas. El que nos interesa para lograr nuestro objetivo es el llamado selector de atributos, que aplicado a una etiqueta permite filtrar los elementos que presenten un valor concreto asociado a un atributo de la misma.
Así, en el siguiente código, que debemos incluir en la hoja de estilos del sitio web, buscamos los enlaces cuya página de destino sea en inglés (su hreflag comience por «en»), introduciendo el efecto deseado:
a[hreflang=»en»]
{
padding-right: 19px;
background-image: url(img/bandera_ing.jpg);
background-position: right center;
background-repeat: no-repeat;
}
Observad que el padding-right deja un espacio a la derecha del enlace con la anchura suficiente como para que se pueda ver la imagen de fondo, la banderilla, que aparecerá allí gracias a su alineación horizontal a la derecha definida con el background-position.
Y, ahora sí, podemos recomendar visitas a páginas en inglés como CSS Zen Garden  con fundamento. Así es como se verá el enlace (en geeks.ms he tenido que incluir la imagen a mano por un problemilla con la plantilla, el efecto real lo podéis ver en esta misma entrada en Variable not found).
con fundamento. Así es como se verá el enlace (en geeks.ms he tenido que incluir la imagen a mano por un problemilla con la plantilla, el efecto real lo podéis ver en esta misma entrada en Variable not found).
Ah, un último detalle. Aunque hoy en día los navegadores tienden cada vez más a respetar los estándares, es posible que encontréis alguno con el que no funcione bien esta técnica principalmente por no soportar el selector de atributos (por ejemplo IE6 y anteriores, afortunadamente cada vez menos usados).
Publicado en: www.variablenotfound.com.